
MySQL
非关系型数据库: key value
mongodb redis
关系数据库 E-R关系图
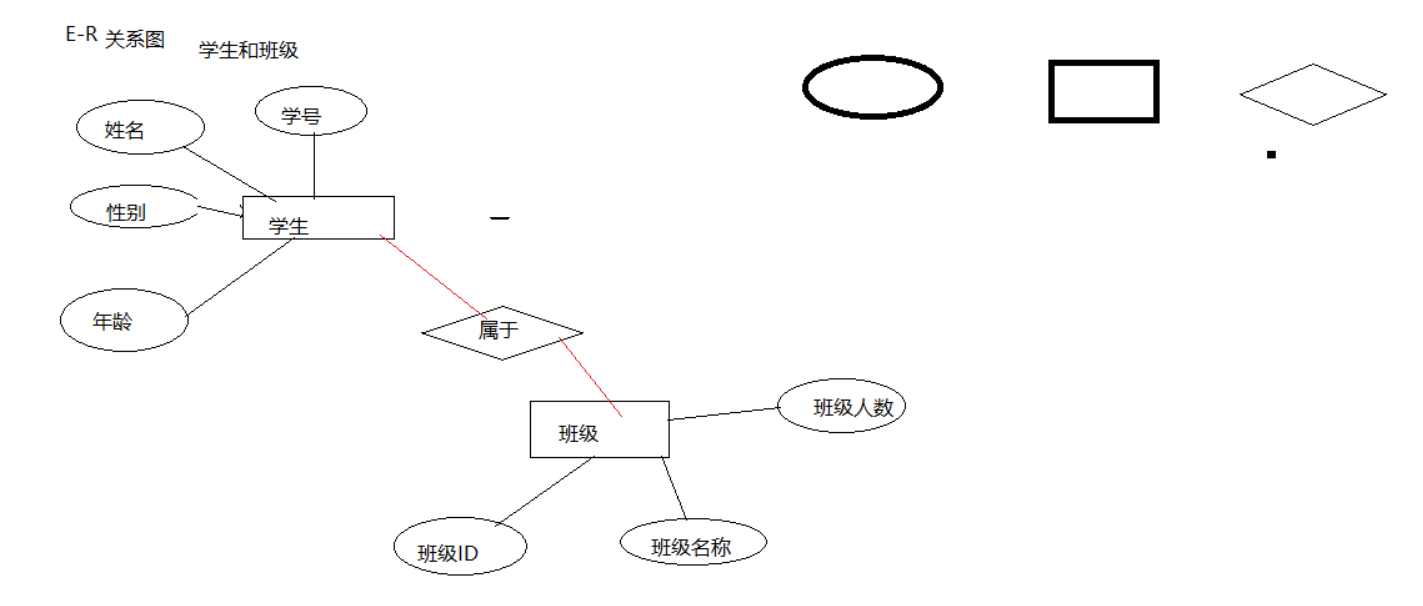
描述实体与实体之间的关系
试试在在存在的事物 男生和女生 学生和班级 员工和部门
MySQL语句
DDL:数据定义语言: 定义数据库 表 结构的 create drop alter
DML:数据操作语言: 操作数据 insert(插入) update(修改) delete(删除)
DCL: 数据控制语言: 定义访问全新,取消访问权限,安全设置 grant
DQL:数据查询语言 select(查询) from子句 where子句
test:
创建数据库时候 指定字符集
create database 数据库名字 character set utf-8
创建数据库时候 指定校对规则
create database 数据库名字 character set urt-8 collate 校对规则 比如: create database 数据库名字 character set urt-8 collate utf8_bin;
补充: 字符集是一套符号和编码,校对规则是在字符集内用于比较字符的一套规则。
查看所有数据库:show databases
performance_schema
information_schema
show CREATE DATABASE book;
修改数据库的操作 alter database 数据库的名字 character set 字符集
删除数据库: drop database 数据库名字;
查看当前使用的数据库 SELECT DATABASE();
创建表:
create table 表名(
列名 列的类型(长度) 约束,
列名 列的类型 约束
)
列的类型 : Java sql
int int
String/char varchar/char
char固定长度 char(3) 不满空格补 varchar可变长度 varchar(3) 不会空格补 varchar省空间,但是最多都是3哦! 长度是代表字符的个数!
double double
float float
boolean boolean
date date YYYY-MM-DD
time HH:MM:SS
datetime YYYY-MM-DD HH:MM:SS 默认值是 null
timestamp YYYY-MM-DD HH:MM:SS 默认当前时间
text: 主要存放文本
blob : 存放的是二进制
列的约束:
主键约束: primary key
唯一约束: unique
非空约束: not null
创建表:
分析实体
create TABLE stu( sid int PRIMARY KEY, #主键通常都是唯一的 sname VARCHAR(10), sex int , age int );
查看所有的表
show databases;
查看表的定义:
show create table 表名
查看表的结构:
desc stu;
修改表:
添加列(add)
alter table 表名 add 列名 列的类型 列的约束
ALTER table stu add scor int not null;
修改列 (modify)
ALTER TABLE stu MODIFY sex VARCHAR(2);
修改列名 (change)
ALTER TABLE stu change sex gender VARCHAR(2) ; # 后面的属性约束要跟上
删除列 (drop)
ALTER TABLE stu drop scor;
修改表名(rename)
RENAME table stu to xuesheng;
修改表的字符集
alter TABLE xuesheng CHARACTER set gbk;
删除表:
drop table xuesheng;
SQL对表中的数据进行CRUD:
insert into(列名1, 列名2 ,列名3) values(值1, 值2 ,值3);
insert into stu(sid, sname, sex, age) VALUES (1,'jack',1,23);
简单写法
insert into stu VALUES(2,'MI',2,32);
批量插入:
INSERT INTO stu VALUES(3,'a1',1,32),(4,'a2',2,31),(5,'a3',1,13);
单挑插入和批量插入的效率问题 批量块
删除操作:
delete from 表名 where
DELETE from stu where sid = 3;
delete from 表名 #全部删除掉 如果没有指定条件 会将将表中的所有数据删除掉
类似的 truncate 语句
delete: 属于DML语句 一条一条删除表中的的数据
truncate: 属于DDM语句,先删除表,再去重建表
如果数据量 比较少 delete效率高 反之 truncate效率高
更新表记录:
update 表名 set 列名=列的值 ,列名=列的值 where
update stu set sex=9 where sid = 1
如果参数是字符串,日期 一定要加单引号!!!!
update stu set sname = 'Robbon' where sid = 1
如果不加where条件 那么整个这一列都会被修改
update stu set sname = 'Robbon'
查询操作:
distinct 去除重复的数据
商品的分类: 手机数码, 鞋靴箱包
分类 id 分类名称 分类描述
create table category( cid int PRIMARY KEY auto_increment, cname VARCHAR(10), cdesc VARCHAR(31) )
插入数据:
INSERT into category VALUES(null,'手机数码','三星,华为,小米'); INSERT into category VALUES(null,'鞋靴箱包','爱马仕,LV,耐克'); INSERT into category VALUES(null,'香烟酒水','茅台,黄鹤楼'); INSERT into category VALUES(null,'甜点零食','饼干,泡芙');
所有商品: 商品Id 商品名称 商品的价格 生产日期 分类分类ID
商品和商品分类的关系 所属的关系
CREATE TABLE product( pid int PRIMARY key auto_increment, pname VARCHAR(10), price DOUBLE, pdate timestamp, cno int #这个字段类型 必须和 另外一张表的一模一样 )
插入数据:
INSERT into product values(null,'锤子手机',2000,null,1); INSERT into product values(null,'阿迪达斯',200,null,2); INSERT into product values(null,'五粮液',2800,null,3); INSERT into product values(null,'蒙牛',20,null,4); INSERT into product values(null,'卫龙辣条',2,null,4);
查询所有的商品名字 价格:
SELECT pname, price from product;
别名查询:
表别名
SELECT p.pname, p.price from product as p;
列别名
SELECT p.pname as '商品名字', p.price as '商品价格' from product as p;
select 选择显示哪些列的内容 from要优先于from执行
去掉重复值查询:
查询商品所有的价格
SELECT DISTINCT price from product;
运算查询:
SELECT *,price*10 from product;
SELECT *,price*10 as 涨后价 from product;
条件查询: where关键字
查询商品价格 > 60 商品信息
SELECT * from product where price > 60
还可以 > >= < <= != <>
查询商品价格不等于88的所有商品
SELECT * from product where price <> 60
查询商品价格 在 10 到 100 之间的
SELECT * from product where price>10 and price<100; 或者 SELECT * from product where price BETWEEN 10 AND 100;
逻辑运算符: and or not
查询商品价格 小于100 或者 大于900
SELECT * from product where price <100 or price>900;
模糊查询 like
- :代表一个字符
% :代表多个字符
查询出名字中带有 “条” 的所有商品
SELECT * from product where pname like '%条%';
查询第二个名字是“龙”的所有商品
SELECT * from product where pname like '_龙%';
in 获取某个范围的值
查询出商品分类ID在 1,3,4里的所有商品
SELECT * from product where cno in (1,3,4);
排序查询:
asc: 升
desc: 降
查询所有商品按照价格排序
SELECT * from product ORDER BY price desc;
SELECT * from product ORDER BY price asc;
查询名称有 龙 的商品 按价格降序排序
先查询出 龙 的商品
SELECT * from product where pname like '%龙%';
然后对结果进行排序
SELECT * from product where pname like '%龙%' ORDER BY price;
聚合函数:
su() 求和
avg() 求平均值
count() 统计数量
max() 最大值
min() 最小值
SELECT SUM(price) from product;
SELECT avg(price) from product;
SELECT count(*) from product;
form出的这个表的字段进行操作
注意 where条件后面不能接聚合函数
查出商品价格大于 平均价格的所有商品
分析 : 查询所有商品 然后大于平均价格
SELECT * from product
SELECT avg(price) from product;
SELECT* FROM product where price > (SELECT avg(price) from product);
分组:
根据商品cno字段(种类) 分组后统计商品个数
SELECT cno, COUNT(*) from product group BY cno
根据cno分组,分组统计每组商品的平均价格 并且商品平均价格 >60
SELECT cno,avg(price) from product group BY cno having avg(price) >60;
注意: having 关键字 可以接聚合函数 出现在分组之后 where关键字 不可以接聚合函数 出现在分组之后
SQL的编写顺序:
select from .. where .. groupby having order by
执行顺序:
from 得到表的数据 然后进行条件判断where 然后得到一张表进行分组group by 分组完毕之后进行筛选having 显示结果slect 显示结果进行order by排序
小结:alter table 表名(add, modify,change, drop)
多表的使用
两个表之前存在 关系 这个关系需要维护
外键约束: foreigin key
给product表中的cno添加一个外键约束
ALTER table product add foreign key(cno) REFERENCES category(cid);
从分类表中删除分类为3的信息 不可以的! 因为两个表建立了关系! 删除失败
如果一定要删除 首先得去priduct表 删除 所有分类id为3的商品
多表之间的建表原则
建数据库的原则 通常情况下一个项目 建一个数据库
建表原则 首先看关系
一对多 商品和分类
建表原则: 在多的一方 添加一个外键 指向一的一方的主键 category product
多对多 学生表 课程表
建表原则: 多建一张中间表,中间表至少要有两个主键,这两个外键分别指向原来的那张表。

一对一的建表:
1、 公民表 身份证表 直接合并一个就ok了
2、 或者两边的主键设计为同一个
将一对一的情况 当作是一对多情况处理 在任意一张表添加一个外键 并且这个外键要唯一 指向另外一张表
直接将两张表合并成一张
将两张iao的主键建立器连接,让两张表里面的主键相等
实际用途: 用的不多 拆表操作用的多
将常用的信息和不常用的信息拆分 减少表的臃肿
用户表 订单表 商品表 商品分类
用户表 和 订单表 一对多的关系
用户表 和 商品表没关系
商品表 和 商品分类 一对多
订单表 和 商品部 多对多
用户表:
CREATE TABLE user( uid int PRIMARY key auto_increment, username VARCHAR(31), password VARCHAR(31), phone VARCHAR(11) );
INSERT INTO `user` VALUES(1,'zhangsan','123','1353823211');
订单表:
create TABLE orders( oid int PRIMARY KEY auto_increment, sum int, otime timestamp, address VARCHAR(100) );
根据一对多的关系 一个用户对应多个订单
订单表 添加一列 指向 用户表 并且添加外键约束
所以订单表:
create TABLE orders( oid int PRIMARY KEY auto_increment, sum int, otime timestamp, address VARCHAR(100), uno int, FOREIGN KEY(uno) REFERENCES user(uid) );
分类表:
CREATE TABLE `category` ( `cid` int(11) PRIMARY KEY AUTO_INCREMENT, `cname` varchar(10) , `cdesc` varchar(31) , )
商品表:
create table product( pid int PRIMARY key auto_increment, pname VARCHAR(10), price double, cno int, #指向商品分类表的外键 FOREIGN key(cno) REFERENCES category(cid) )
插入数据:
INSERT into product values(null,'锤子手机',2000,1); INSERT into product values(null,'阿迪达斯',200,2); INSERT into product values(null,'五粮液',2800,3); INSERT into product values(null,'蒙牛',20,4); INSERT into product values(null,'卫龙辣条',2,4);
订单项(中间表) 订单id 商品数量 订单项总价
create TABLE orderitem( ono int, #指向order的id pno int, #指向product的id FOREIGN KEY(ono) REFERENCES orders(oid), FOREIGN KEY(pno) REFERENCES product(pid), ocount int, subsum double );
给一号订单添加商品:
INSERT INTO orderitem VALUES(1,1,2,2000); INSERT INTO orderitem VALUES(1,5,8,16);
给二号订单添加商品:
INSERT INTO orderitem VALUES(2,2,2,2000); INSERT INTO orderitem VALUES(2,3,2,5000);
小结:
多表之间的关系如何维护,外键约束: foreign key
添加一个外键: alter table product add foreign key(cno) references category(cid);
foreign key(cno) references category(cid)
删除时候,先删除外键关联的所有数
主键约束
默认不能为 空 唯一
外键都是指向另外一张表的主键
一张表一个主键
唯一约束
列里面的内容 必须唯一 不能出现重复 可以为空
唯一约束不可以作为其他表的外键
可以有多个唯一约束
SELECT * from product;
SELECT * from category;
SELECT * from product, category; #查询出笛卡尔积 查出来两张表的乘积
#隐式内连接
SELECT * from product as p, category as c where p.cno=c.cid;
#显示内连接
SELECT * from product p INNER JOIN category c on p.cno=c.cid;
区别: 隐式内连接 在查询出结果的基础上去做的where条件过滤
显示内连接 带着 条件去查询结果,执行效率要高
SELECT * from product p LEFT OUTER JOIN category c ON p.cno = c.cid;
左外链接 会将左表中的所有数据都查询出来 如果右表中没有对应的数据 用null代替
SELECT * from product p RIGHT OUTER JOIN category c ON p.cno = c.cid;
右外连接 会将右表的所有数据查询出来 如果左表没有对应的数据 用null代替
分页查询: limit 略

 浙公网安备 33010602011771号
浙公网安备 33010602011771号