机器学习中聚类模型
机器学习中聚类模型
1 K-means
参考链接:建模算法系列二十六:K-means聚类(附源码) - 知乎 (zhihu.com)
1.1 K-means聚类方法的步骤代码【整体】
clc;clear;close all;
data(:,1)=[90,35,52,83,64,24,49,92,99,45,19,38,1,71,56,97,63,
32,3,34,33,55,75,84,53,15,88,66,41,51,39,78,67,65,25,40,77,
13,69,29,14,54,87,47,44,58,8,68,81,31];
data(:,2)=[33,71,62,34,49,48,46,69,56,59,28,14,55,41,39,
78,23,99,68,30,87,85,43,88,2,47,50,77,22,76,94,11,80,
51,6,7,72,36,90,96,44,61,70,60,75,74,63,40,81,4];
figure(1)
scatter(data(:,1),data(:,2),'LineWidth',2)
%% 原理推导K均值
[m,n]=size(data);
cluster_num=4;
cluster=data(randperm(m,cluster_num),:); % 随机产生四个点。也就是类簇的中心
epoch_max=1000;%最大次数
therad_lim=0.001;%中心变化阈值
epoch_num=0;
while(epoch_num<epoch_max)
epoch_num=epoch_num+1;
for i=1:cluster_num
repeatmat =repmat(cluster(i,:),m,1) % 第i个中心的重复;
distance=(data-repeat_mat).^2;
distance1(:,i)=sqrt(sum(distance'));
end
[~,index_cluster]=min(distance1');
for j=1:cluster_num
cluster_new(j,:)=mean(data(find(index_cluster==j),:));
end
if (sqrt(sum((cluster_new-cluster).^2))>therad_lim)
cluster=cluster_new;
else
break;
end
end
1.2 K-means聚类方法的步骤
1.2.1 准备阶段:导数数据+确定类簇数+确定迭代次数+确定终止条件
(1)随机任取四个类簇中心
(2)确定最大迭代次数为1000次
(3)确定终止条件:最后一次与最后一次的上一次差距
1.2.2 初次迭代阶段
(1)计算每个样本点到各个类中心的距离(这个距离可以用各种距离计算),存储在一个list中或者ndarray中。
例如:在上述代码中。
红色框表示:第一个样本点距离四个类中心的距离。
红色框第一个数表示:第一个样本点距离第一个类中心的距离。
后续的依此类推。
(2)选择样本点距离最近的类中心,并记录索引此时类中心的索引值,索引值代表类中心编号。
例如下图:
蓝框表示:第一个样本点属于第一类。
得到index_cluster表示类别,如下图所示。
(3)计算属于同一类所有样本点的中心距离,并成为新的类中心。得到新的类中心的坐标。
(4)判断新的类中心,与原来类中心的差距是不是小于一个阈值。若不满足,则继续往下迭代,若满足,则停止迭代。
1.2.3 第二次迭代:再计算所有样本点到新类中心的距离……一系列操作。
2 谱聚类
掉包代码链接:https://www.cnblogs.com/pinard/p/6235920.html
2.1 谱聚类的思想
参考链接:https://zhuanlan.zhihu.com/p/54348180
它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
那么如何将切图这个操作转化为优化问题?【参考链接https://www.cnblogs.com/JiePro/p/Clustering_1.html】这里定义损失函数——被截断的边的权重之和
$\operatorname{Cut}\left(G_1, G_2\right)=\sum_{i \in G_1, j \in G_2} W_{i j}$
通过这个链接里面的一系列解释,可以得出结论——谱聚类就是基于图论的一种方法,将切图这个操作转换为求所切边权重之和最小值的优化问题。此优化问题的解就是拉普拉斯矩阵的特征向量。要对应到聚类这个目的上面去,就需要对特征向量进行聚类。
2.2 谱聚类的实现流程(相似矩阵的生成方式+切图的方式)
相似矩阵的生成方式有大概三种:$epsilon$-邻近法,K邻近,全连接法;切图有大概两种方法:RatioCut,Ncut;补充:最常用的相似矩阵的生成方式是基于高斯核距离的全连接方式。最常用的切图方式是Ncut。而到最后常用的聚类方法为K-Means。
2.2.1 构造相似矩阵
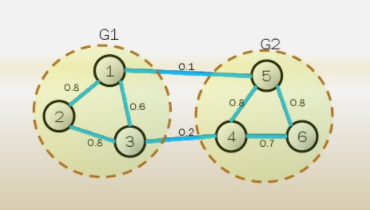
这个图中六个样本点,两个点之间的连线用边表示,边上的数字表示的是两个顶点之间的逻辑关系(相似程度),称之为“权重”,用$W_{ij}$来表示。权重的基本思想是,距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高。但这仅仅是定性,我们还需要定量。
将所有权重以矩阵的形式存放,称之为邻接矩阵,如下图所示。
但是此例子是直接给出了邻接矩阵里的数值,但是在谱聚类问题中,我们只有顶点流量,无法计算得到邻接矩阵。
因此可以通过样本点距离度量的相似矩阵S获得邻接矩阵。因此引出构建邻接矩阵的三种方法。
(1)\( \epsilon \)-邻近法(比较少用)
对于ϵ-邻近法,它设置了一个距离阈值ϵ,然后用欧式距离 $s_{ij}$ 度量任意两点 $x_{i}$ 和 $x_{j}$的距离。$S_{i j}=\left\|x_i-x_j\right\|^2$。
然后根据$s_{ij}$和ϵ的大小关系,来定义邻接矩阵W:
$W_{i j}= \begin{cases}0 & \text { if } s_{i j}>\epsilon \\ \epsilon & \text { if } s_{i j} \leq \epsilon\end{cases}$。
从上式可见,两点间的权重要不就是ϵ ,要不就是0,矩阵中没有携带关于数据集的太多信息,所以该方法一般很少使用,在sklearn中也没有使用该方法。
(2)knn
基本思想是,利用 Knn 算法遍历所有的样本点,取每个样本最近的 k 个点作为近邻,只有和样本距离最近的 k 个点之间的 $W_{i j}>0$。
但是,由于每个样本点的 k 个近邻可能不是完全相同的,所以用此方法构造的相似度矩阵并不是对称的。
为了解决这种问题,一般采用下面两种方法之一:
1. 只要一个点在另外一个点的K邻近中,就保留$s_{ij}$
2.必须两个点互为K邻近,才能保留$s_{ij}$
(3)全连接法(最常用)
相比前两种方法,全连接法中所有的点之间的权重值都大于0。
可以选择不同的核函数来定义边权重,常用的有:多项式核函数,高斯核函数和Sigmoid核函数。其中,最常用的是高斯核函数RBF,在sklearn中默认的也是该方法,此时相似矩阵和邻接矩阵相同:$W_{i j}=W_{j i}=\sum_{i=1, j=1}^n \exp \frac{-\left\|x_i-x_j\right\|^2}{2 \sigma^2}$
2.1.2 根据相似矩阵S构建邻接矩阵W,构建度矩阵D
对于图中的任意一个点$v_{i}$,它的度$d_{i}$定义为和它相连的所有边的权重之和,即:$d_i=\sum_{j=1}^n w_{i j}$。更通俗一点说,就是每一行相加即可。
2.2.3 计算出拉普拉斯矩阵L
拉普拉斯矩阵L=D-W。

2.2.4 构建标准化后的拉普拉斯矩阵,并对其进行特征值分解,得到特征向量$H_{nn}$
最小化Cut函数的解,就是拉普拉斯矩阵的前k小值的特征向量。【核心思想】
(1)标准化后的矩阵为$D^{-1 / 2} L D^{-1 / 2}$
(2)特征值分解与特征向量的知识【参考链接https://blog.csdn.net/weixin_43772166/article/details/115136235】
矩阵和向量作乘法,向量会变成另一个方向或长度的新向量,主要会发生旋转、伸缩的变化。如果矩阵乘以某些向量后,向量不发生旋转变换,只产生伸缩变换那么就说这些向量是矩阵的特征向量,伸缩的比例就是特征值。
例如:$A \mathrm{x}=\lambda \mathrm{x}$。A是n阶方阵,$\lambda$是A对应的特征值,x是A对应的特征向量。
特征值分解就是将一个矩阵分解成:$\mathrm{A}=\mathrm{P} \Lambda \mathrm{P}^{-1}$。P是这个矩阵A的特征向量组成的矩阵,$\Lambda$是特征值组成的对角矩阵,里面的特征值是由大到小排列的,这些特征值对应的特征向量就是描述这个矩阵变化方向。
2.2.5 对k个特征向量作Kmeans或者别的方法的聚类
将k个特征向量竖着排,排列之后,每一行就相当于一个样本。特征向量的维度就是样本点的个数,特征向量的个数就是样本点的维度。
按照这个聚类方法,得出的结论就是对原始样本点的聚类结果。
2.3 代码实现
参考两个链接
1.https://blog.csdn.net/zhanglianhai555/article/details/104807914?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-104807914-blog-52990015.pc_relevant_multi_platform_featuressortv2dupreplace&spm=1001.2101.3001.4242.2&utm_relevant_index=4
2.https://zhuanlan.zhihu.com/p/392736238?utm_id=0
3 DBSCAN 聚类算法
代码参考链接(调包):https://blog.csdn.net/qq_34160248/article/details/123443490
原理的简单实例化参考链接:https://blog.csdn.net/hansome_hong/article/details/107596543
其英文全称是 Density-Based Spatial Clustering of Applications with Noise,意即:一种基于密度,对噪声鲁棒的空间聚类算法。直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
DBSCAN聚类算法是偏工程的,没什么数学公式
3.1 算法描述
输入:数据集,邻域半径Eps,领域中对象数目阈值 MinPts;
输出:密度联通簇。
处理流程如下:
(1)从数据集中任意选取一个数据对象点 p;
(2)如果对于参数 Eps 和 MinPts,所选取的数据对象点 p 为核心点,则找出所有从 p 密度可达的数据对象点,形成一个簇;【数据点形成一个簇之后,后面操作就不会再涉及这些点了】
(3)如果选取的数据对象点 p 是边缘点,选取另一个数据对象点;
(4)重复(2),(3)步。
3.2 算法实例
3.2.1 数据集准备
下面给出一个样本数据集,如表 1 所示,并对其实施 DBSCAN 算法进行聚类,取 Eps=3,MinPts=3。表中有13个点以及他们的坐标。
数据集中的样本数据在二维空间内的表示如图 3 所示。

第一步,顺序扫描数据集的样本点,首先取到 p1(1,2)。
1)计算 p1 的邻域,计算出每一点到 p1 的距离,如 d(p1,p2)=sqrt(1+1)=1.414。
2)根据每个样本点到 p1 的距离,计算出 p1 的 Eps 邻域为 {p1,p2,p3,p13}。
3)因为 p1 的 Eps 邻域含有 4 个点,大于 MinPts(3),所以,p1 为核心点。
4)以 p1 为核心点建立簇 C1,即找出所有从 p1 密度可达的点。
5)p1 邻域内的点都是 p1 直接密度可达的点,所以都属于C1。
6)寻找 p1 密度可达的点,p2 的邻域为 {p1,p2,p3,p4,p13},因为 p1 密度可达 p2,p2 密度可达 p4,所以 p1 密度可达 p4,因此 p4 也属于 C1。
7)p3 的邻域为 {p1,p2,p3,p4,p13},p13的邻域为 {p1,p2,p3,p4,p13},p3 和 p13 都是核心点,但是它们邻域的点都已经在 Cl 中。
8)P4 的邻域为 {p3,p4,p13},为核心点,其邻域内的所有点都已经被处理。
9)此时,以 p1 为核心点出发的那些密度可达的对象都全部处理完毕,得到簇C1,包含点 {p1,p2,p3,p13,p4}。
第二步,继续顺序扫描数据集的样本点,取到p5(5,8)。
1)计算 p5 的邻域,计算出每一点到 p5 的距离,如 d(p1,p8)-sqrt(4+1)=2.236。
2)根据每个样本点到 p5 的距离,计算出p5的Eps邻域为{p5,p6,p7,p8}。
3)因为 p5 的 Eps 邻域含有 4 个点,大于 MinPts(3),所以,p5 为核心点。
4)以 p5 为核心点建立簇 C2,即找出所有从 p5 密度可达的点,可以获得簇 C2,包含点 {p5,p6,p7,p8}。
第三步,继续顺序扫描数据集的样本点,取到 p9(9,5)。
1)计算出 p9 的 Eps 邻域为 {p9},个数小于 MinPts(3),所以 p9 不是核心点。
2)对 p9 处理结束。
第四步,继续顺序扫描数据集的样本点,取到 p10(1,12)。
1)计算出 p10 的 Eps 邻域为 {p10,pll},个数小于 MinPts(3),所以 p10 不是核心点。
2)对 p10 处理结束。
第五步,继续顺序扫描数据集的样本点,取到 p11(3,12)。
1)计算出 p11 的 Eps 邻域为 {p11,p10,p12},个数等于 MinPts(3),所以 p11 是核心点。
2)从 p12 的邻域为 {p12,p11},不是核心点。
3)以 p11 为核心点建立簇 C3,包含点 {p11,p10,p12}。
第六步,继续扫描数据的样本点,p12、p13 都已经被处理过,算法结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号