多目标优化
定义问题
1. 数据偏差
在有点击的数据上训练 stay 模型,在全局估计。(然而我们系统里面,是用了非点击的数据的 = = 跟论文里面不一样啊!!!我要不要剔除这部分数据呢)
2. 数据稀疏
正例样本少。
常见多目标优化形式
1. 针对每一个目标单独建模,线上加权。难以维护。
2. 针对样本进行加权,boost stay... 可以快速上线,不方便迭代。
3. 用 learning to rank,直接对排序目标进行优化,但是需要构造期望排序的样本对,样本数量大,且偏序关系不容易构造,多目标之间的关系不易调整。
4. 同一个模型训练多个目标,好处迭代方便,节省资源,缺点是模型比较复杂,各个人物之间学习可能相互影响,影响训练速度。
所有多目标的模型结构
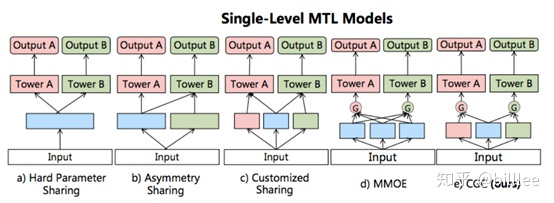
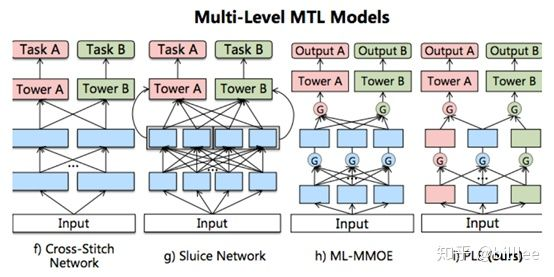
单层多目标模型本质上的区别:share embedding 的方式
- hard parameter sharing
完全 share embedding,然后输出分别输入到不同任务的多塔模型中。
- asymmetry sharing
感觉建了两套 embedding,其中底层 embedding 可能被多个任务利用。(可能写 feature_config 的时候写多份?,但是我们 slot_id 决定了每个特征只能对应一个 embedding?)
- customized sharing
疑惑:如果只看图的话,感觉更像是,有公用的特征,有任务独立用的特征。or 一个特征对应两个任务的 embedding?
- mmoe
原身是 moe, 全局只有一个 gate。
mmoe 引进 #任务 的 #gate。网络学习如何对 expert 进行加权求和。
- customized gate control
就是在 customized sharing 里面引入 gate。
疑惑:embedding到底是哪里。是蓝色的方块吗?
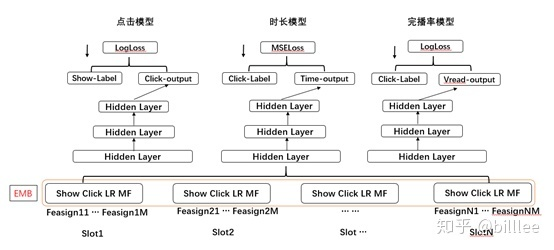
这个图可以解决我不懂 embedding 是哪层的问题
多目标中的常见问题
1. 样本空间不一致
定义:不同任务使用的训练样本不一样,stay只在有点击的样本上训练。
solution:
- 目标转换: 从预估 [ctr, stay] 改成预估 [ctr*stay] 注意我们这里
注意 esmm 本质上利用的是依赖关系,相当于有先验知识。而我们这里改成 0,1 以后,可能就丧失了
- 不回传梯度:只用有点击的样本进行 stay 的学习。需要注意下 batch 内求梯度平均值的时候要改成正样本数量,而非 batch_size!
2. loss
- 调整学习率相当于调整总loss的各任务占比
- 增大点击率模型的学习率,可以弥补时长未能学习未点击样本造成的训练偏差问题。
- regression 也可以用 logloss
- loss 的本质是为了衡量预估和真实目标的差距。
- sigmoid 后面接 mse 容易造成梯度消失。(可推导)
- 但是这里还是因为业务形式的问题,完播率 label 一般接近 0 或1 ,所以用 logloss 是比较合理的。stay duration 还是不太能够放量。
阿里多目标的优化路径

参考:
https://zhuanlan.zhihu.com/p/299913604

 浙公网安备 33010602011771号
浙公网安备 33010602011771号