

Python爬虫自学笔记(五)Scrapy框架
Python有很多好用的框架,在爬虫领域,最重要的就是Scrapy框架了。
1、安装与启动
安装(命令行)
pip3 install scrapy创建scrapy项目(命令行进到要建立scrapy项目的目录下):
scrapy startproject 项目名 创建爬虫(命令行):
scrapy genspider 爬虫名 要爬取的网站地址 # 可以创建多个爬虫启动爬虫:
命令行启动
scrapy crawl 爬虫名字
scrapy crawl 爬虫名字 --nologscrapy在pycharm配置启动(无需命令行启动)
# 在项目路径下创建一个run.py(名字随意),右键执行即可
from scrapy.cmdline import execute
# execute(['scrapy','crawl','爬虫名','--nolog'])
execute(['scrapy','crawl','爬虫名'])2、框架的项目结构
官方的结构图:
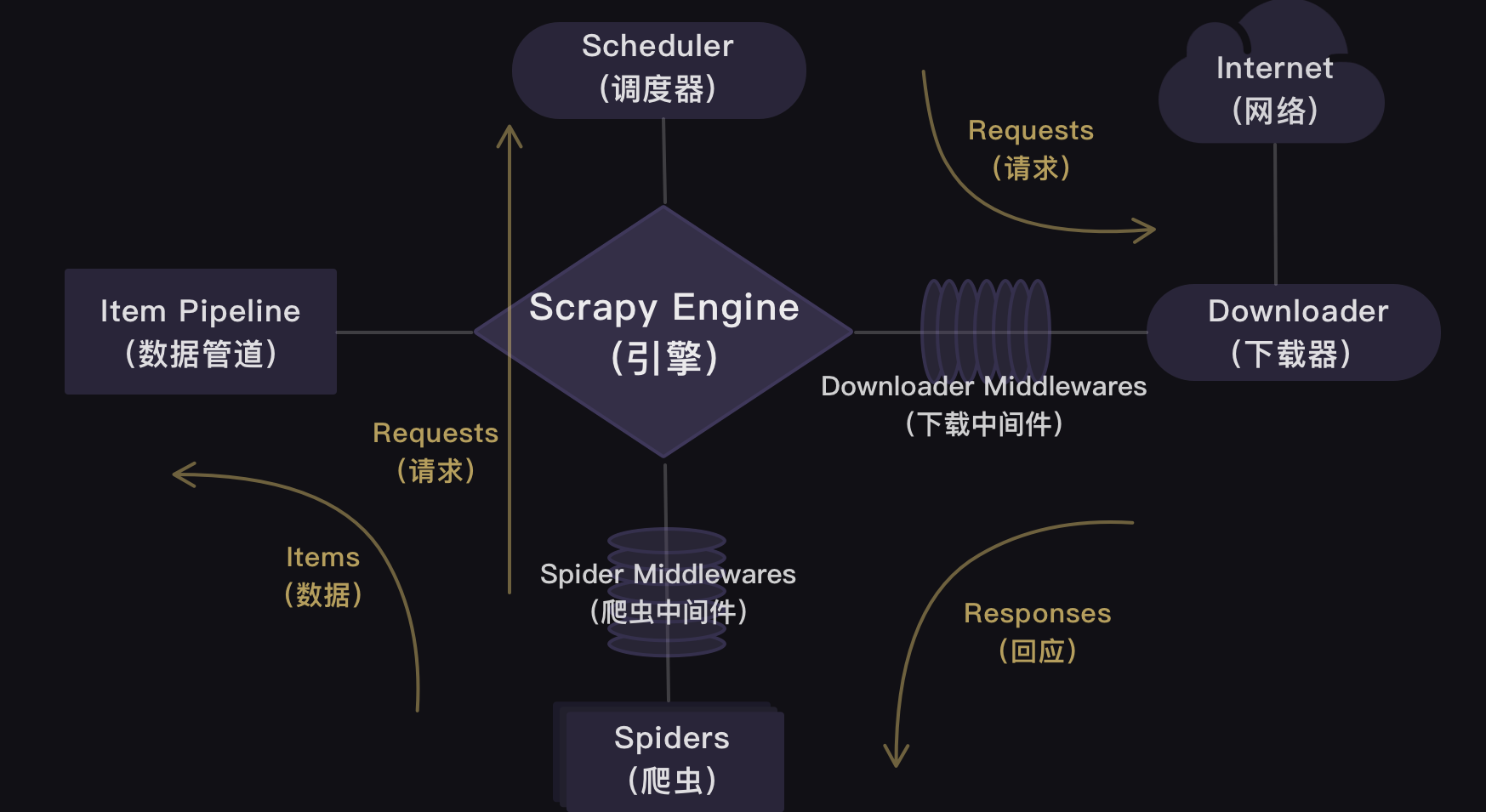
简书上给的这个结构图很清晰
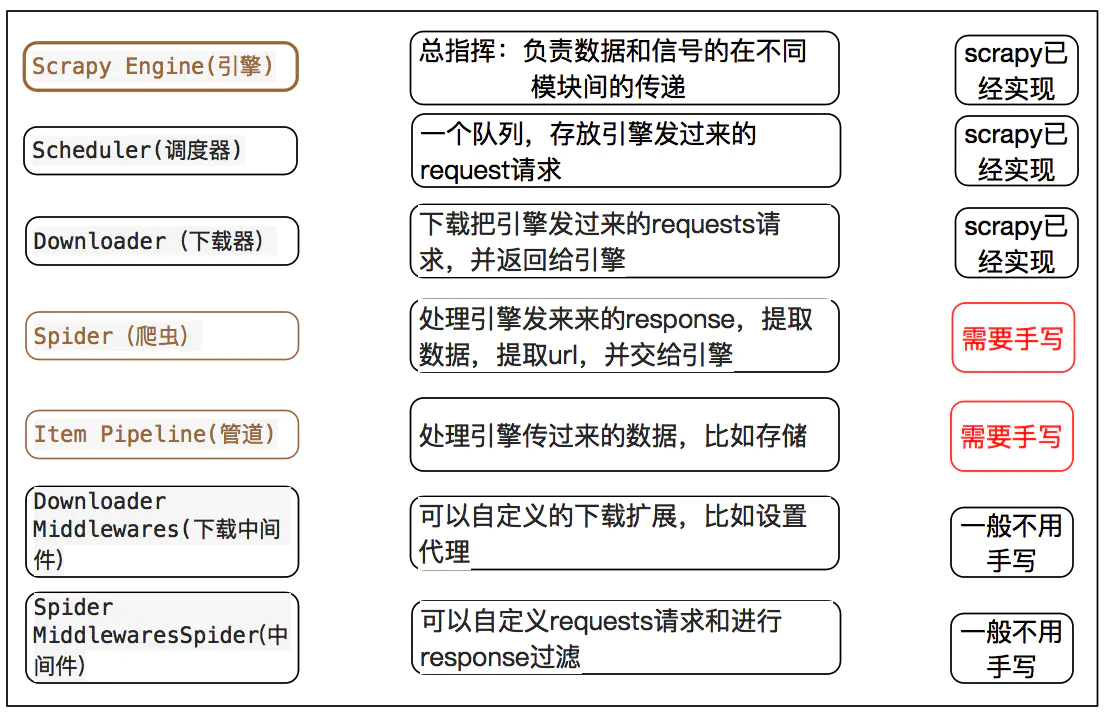
我将用个例子来说明各个部分的使用
比如,我打算从 https://www.kanunu8.com(努努书坊 - 小说在线阅读 (kanunu8.com)) 这个网站来下载阿加莎-克里斯蒂的小说
用上面命令行创建项目
scrapy startproject ajiasha将看到下面这样的一个项目结构
ajiasha/
scrapy.cfg # deploy configuration file
ajiasha/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
3、爬虫代码编写
spiders这个文件夹是用来放爬虫文件的,是整个框架的核心部分。
我们在该文件夹下新建一个.py文件,命名为paxiaoshuo.py
这里最重要的是新建一个爬虫类,继承自scrapy的爬虫类
class ajiashaSpider(scrapy.Spider): name = 'paajs' allowed_domains = ['https://www.kanunu8.com'] urlbase='' start_urls = ['https://www.kanunu8.com/files/writer/3993.html'] title='' author='' abstract='' bu='' jie='' content=''
类里面首先要定义name,因为之后的启动爬虫就要用到这个名字
然后设置allowed_domains,设置allowed_domains的含义是过滤爬取的域名,
在插件OffsiteMiddleware启用的情况下(默认是启用的),不在此允许范围内的域名就会被过滤,而不会进行爬取
然后start_urls顾名思义就是起始链接,当 没有指定特定的url时,spider将从该列表中开始抓取。
因此,第一个被获取到的页面的url将是该列表之一。后续的url将会从获取的数据中提取。
剩下的就是定义一些变量留着下面存放东西
下面最核心的就是parse函数,用于处理每个 Request 返回的 Response 。
parse() 通常用来将 Response 中爬取的数据提取为数据字典,或者过滤出 URL 然后继续发出 Request 进行进一步的爬取。
这里因为我下载的是小说,我希望保证小说章节顺序的完整,所以我只用了一个parse函数。
如果是很多并列的数据,可以先用一个parse函数得到一个网址序列,再把这个序列传给下一个parse函数,逐个解析,得到想要的数据。
def parse(self,response): soup=bs4.BeautifulSoup(response.text,'html.parser') soup.encoding='gb2312' zuopinlist=soup.find('div').find_all('table')[8].find_all('table')[1].find_all('a') zpdic={} url_list=[] for zp in zuopinlist: f = re.findall('《(.*?)》',zp.text)[0] zpdic[f]=self.allowed_domains[0]+zp['href'] print(zpdic) for k,v in zpdic.items(): url=v #self.urlbase=url url_list.append(url) #yield scrapy.Request(url,callback=self.parse_sec) #page = response.url res_bu=requests.get(url) res_bu.encoding='gb2312' html=bs4.BeautifulSoup(res_bu.text,'html.parser') data1=html.find('div').find_all('table')[8].find_all('td')[0] self.title=data1.text.strip('\n') data2=html.find('div').find_all('table')[8].find_all('td')[1] n=data2.text.find('发布时间') self.author=data2.text[:n] data3=html.find('div').find_all('table')[8].find_all('tr')[3].find_all('table')[0].find_all('tr')[1].find('td') self.abstract=data3.text data4=html.find('div').find_all('table')[8].find_all('tr')[3].find_all('table')[1].find_all('td') for i in data4: if len(i.find_all('strong'))>0: self.bu = i.text elif i.text=='\xa0': continue else: self.jie = i.text print(self.jie) try: j=i.find('a') jie_link=j['href'] new_url = urllib.parse.urljoin(url,jie_link) print(new_url) Request(url=jie_link,callback=self.parse_sec) res_jie = requests.get(new_url) res_jie.encoding='gbk' con=bs4.BeautifulSoup(res_jie.text,'html.parser') data=con.find('div').find_all('table')[4].find('p') self.content=data.text except TypeError: pass #self.content='全书完'
4、数据存储
scrapy存储数据可以用内置格式,也可以自定义格式。
scrapy 内置的数据格式主要有四种:JSON,JSON lines,CSV,XML
我们将结果用最常用的JSON导出,命令如下:
scrapy crawl dmoz -o douban.json -t json-o 后面是导出文件名,-t 后面是导出类型
自定义格式就是使用Item类生成输出对象用于储存数据。
Item 对象是自定义的python字典,可以使用标准字典语法获取某个属性的值
爬取的数据需要存储,首先就要对数据进行定义。
项目目录下的 items.py就是干这个的。
比如,我需要爬取小说的名称、作者、章节名等,那么在items.py对这些进行定义
import scrapy class AjiashaItem(scrapy.Item): #定义一个类DoubanItem,它继承自scrapy.Item # define the fields for your item here like: title = scrapy.Field() #定义书名的数据属性 author=scrapy.Field() #定义作者的数据属性 abstract=scrapy.Field() #定义内容提要的数据属性 bu=scrapy.Field() #定义分部、章的数据属性 jie=scrapy.Field() #定义小节的数据属性 content = scrapy.Field() #定义正文内容的数据属性
在爬虫里面把爬取到的值传递给这个item类,增加的代码如下:
item=AjiashaItem() item['title']=self.title item['author']=self.author item['abstract']=self.abstract item['bu']=self.bu item['jie']=self.jie item['content']=self.content yield item
实例化 AjiashaItem,然后把数据对应地赋值给这个类。
接下来,数据就被送到 pipelines.py 进行处理。
一样的我们要先定义一个管道的类
class AjiashaPipeline: def __init__(self) -> None: self.flag=True self.title='' self.author='' self.abstract='' self.bu='' self.jie='' self.content=''
from itemadapter import ItemAdapter import docx from docx.shared import Inches,Pt,Cm from docx.enum.text import WD_PARAGRAPH_ALIGNMENT class AjiashaPipeline: def __init__(self) -> None: self.flag=True self.title='' self.author='' self.abstract='' self.bu='' self.jie='' self.content='' def process_item(self, item, spider): path=item['title']+'.docx' try: doc=docx.Document(path) except: doc=docx.Document() if item['title']!=self.title: #path='C:\\小说\\阿加莎小说\\'+item['title']+'.docx' #doc.save(path) self.title=item['title'] #path='C:\\小说\\阿加莎小说\\'+self.title+'.docx' #doc=docx.Document(path) self.flag=True if self.flag==True: tit=doc.add_heading(self.title,level=0) tit.style.font.name='Times New Roman' tit.style.font.size = Pt(25) tit.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER self.author=item['author'] aut=doc.add_heading(self.author,level=1) aut.style.font.name='Times New Roman' aut.style.font.size = Pt(18) aut.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER self.abstract=item['abstract'] abs=doc.add_paragraph() abs.paragraph_format.first_line_indent = Inches(0.3) textabs = abs.add_run(self.abstract) textabs.style.font.size = Pt(15) textabs.style.font.name = 'Times New Roman' doc.add_page_break() self.flag=False if item['bu']!=self.bu: self.bu=item['bu'] bu=doc.add_heading(self.bu,level=2) bu.style.font.name='Times New Roman' bu.style.font.size = Pt(18) bu.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER if item['jie']!=self.jie: self.jie=item['jie'] jie=doc.add_heading(self.jie,level=3) jie.style.font.name='Times New Roman' jie.style.font.size = Pt(16) jie.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER self.content=item['content'] cont=doc.add_paragraph() cont.paragraph_format.first_line_indent = Inches(0.3) textcont = cont.add_run(self.content) textcont.style.font.size = Pt(15) textcont.style.font.name = 'Times New Roman' doc.add_page_break() doc.save(self.title+'.docx') return item
我们还需要修改一下 setting设置,添加请求头,以及把ROBOTSTXT_OBEY=True改成ROBOTSTXT_OBEY=False。
我们还要取消DOWNLOAD_DELAY = 0这行的注释(删掉#)。DOWNLOAD_DELAY翻译成中文是下载延迟的意思,
这行代码可以控制爬虫的速度。因为这个项目的爬取速度不宜过快,我们要把下载延迟的时间改成1秒。
DOWNLOAD_DELAY = 1
把如下的注释删掉#,使之生效
ITEM_PIPELINES = { 'ajiasha.pipelines.AjiashaPipeline': 300, }
这句话的意思是开启item管道,其中的 ajiasha.pipelines.AjiashaPipeline 这个类,后面的数字300是优先级排序,如果有多个管道类的话,
用数字表示它们的先后顺序,300是默认值,可以改成0-1000之间的任意数字,数字越小优先级越高
也可以直接在setting里面设定好输出的路径、文件格式等,只要加上以下代码
#以TXT为例,其他CSV也是一样 FEED_URI='ajs.txt' #这是文件路径 FEED_FORMAT='txt' #这是文件类型 FEED_EXPORT_ENCODING='utf-8' #这是文件编码格式
因为我是直接在pipelines.py中打开Word文档进行存储处理了,所以这里就不需要这几句。
5、启动程序
当然,最后的最后,我们需要启动程序让它运行。
想要运行Scrapy有两种方法,一种是在本地电脑的终端跳转到scrapy项目的文件夹(跳转方法:cd+文件夹的路径名),
然后输入命令行:scrapy crawl 爬虫名(我们这个项目就是 paajs)
另一种运行方式需要我们在最外层的大文件夹里新建一个main.py文件(与scrapy.cfg同级)。
ajiasha/
main.py # 启动文件
scrapy.cfg # deploy configuration file
ajiasha/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
我们只需要在这个main.py文件里,输入以下代码,点击运行,Scrapy的程序就会启动。
from scrapy import cmdline #导入cmdline模块,可以实现控制终端命令行。 cmdline.execute(['scrapy','crawl','paajs']) #用execute()方法,输入运行scrapy的命令。paajs是我们这个项目定义的爬虫名,实际运行要换成自己的爬虫名

