

Python爬虫自学笔记(三)动态网页爬取
现在很多网站用的是动态网页加载技术,这时候用前面的request库和BS4库就不能解决问题了,需要用新的办法。
打开网页,按F12或者右键弹出菜单里选择“检查”,右侧会打开开发者工具。
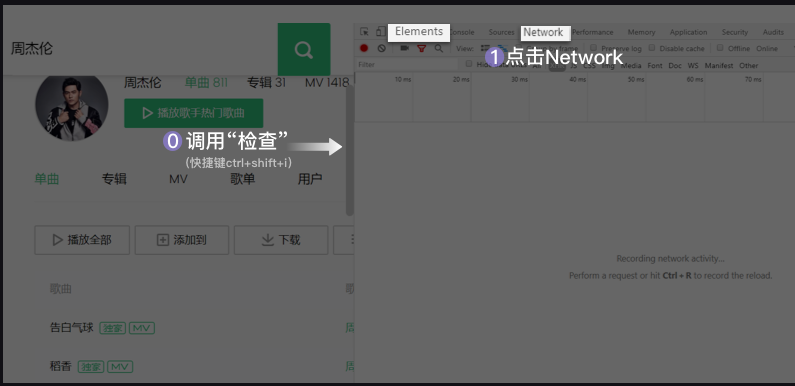
这里有一排菜单,最左边的是Element,显示的是网页的源代码,如果在这里能直接找到所需要爬取的内容,就说明这是静态页面,可以用 request库和BeautifulSoup4库的工具爬取所需内容。如果这里找不到所需内容,那么就是动态页面。这时候往右面看Network菜单。
Network的功能是:记录在当前页面上发生的所有请求。现在看上去好像空空如也的样子,这是因为Network记录的是实时网络请求。现在网页都已经加载完成,所以不会有东西。
右侧勾选框Preserve log,它的作用是“保留请求日志”。如果不点击这个,当发生页面跳转的时候,记录就会被清空。所以,我们在爬取一些会发生跳转的网页时,会点亮它。
然后刷新页面,这时候就会跳出来很多记录。
找到这个页面的第0个请求:search.html,然后点击它,我们来查看它的Response(官方翻译叫“响应”,你可以理解为服务器对浏览器这个请求的回应内容,即请求的结果)。
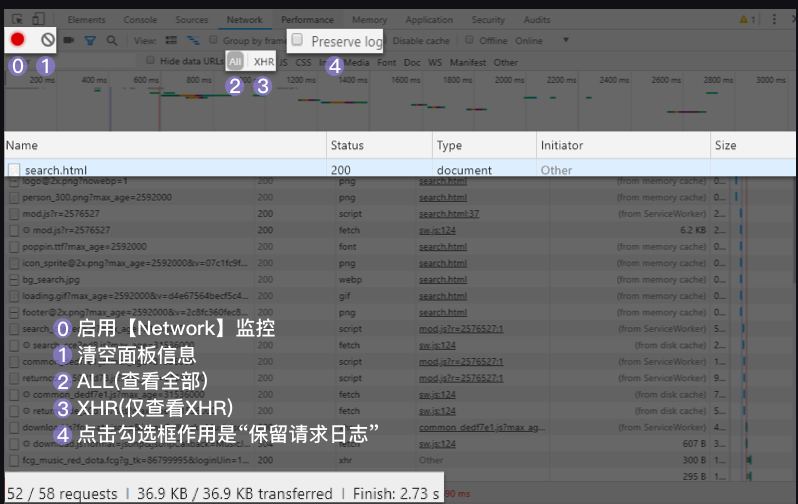
下面第1行,是对请求进行分类查看。我们最常用的是:ALL(查看全部)/XHR(仅查看XHR)/Doc(Document,第0个请求一般在这里),有时候也会看看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他)。最后,JS和CSS,则是前端代码,负责发起请求和页面实现;Font是文字的字体;而理解WS和Manifest,需要网络编程的知识,倘若不是专门做这个,不需要了解。
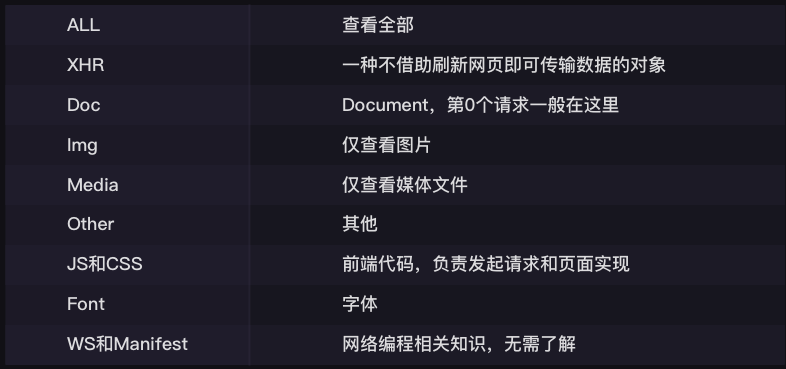
在Network中,有一类非常重要的请求叫做XHR(当你把鼠标在XHR上悬停,你可以看到它的完整表述是XHR and Fetch)
AJAX技术在工作的时候,会创建一个XHR(或是Fetch)对象,然后利用XHR对象来实现,服务器和浏览器之间传输数据。在这里,XHR和Fetch并没有本质区别,只是Fetch出现得比XHR更晚一些,所以对一些开发人员来说会更好用,但作用都是一样的。
在XHR列表中,找到带有我们所需要数据的一个(这个要靠经验了,可以一个个点开看,也可以观察英文名)
点开XHR,看到如下列表
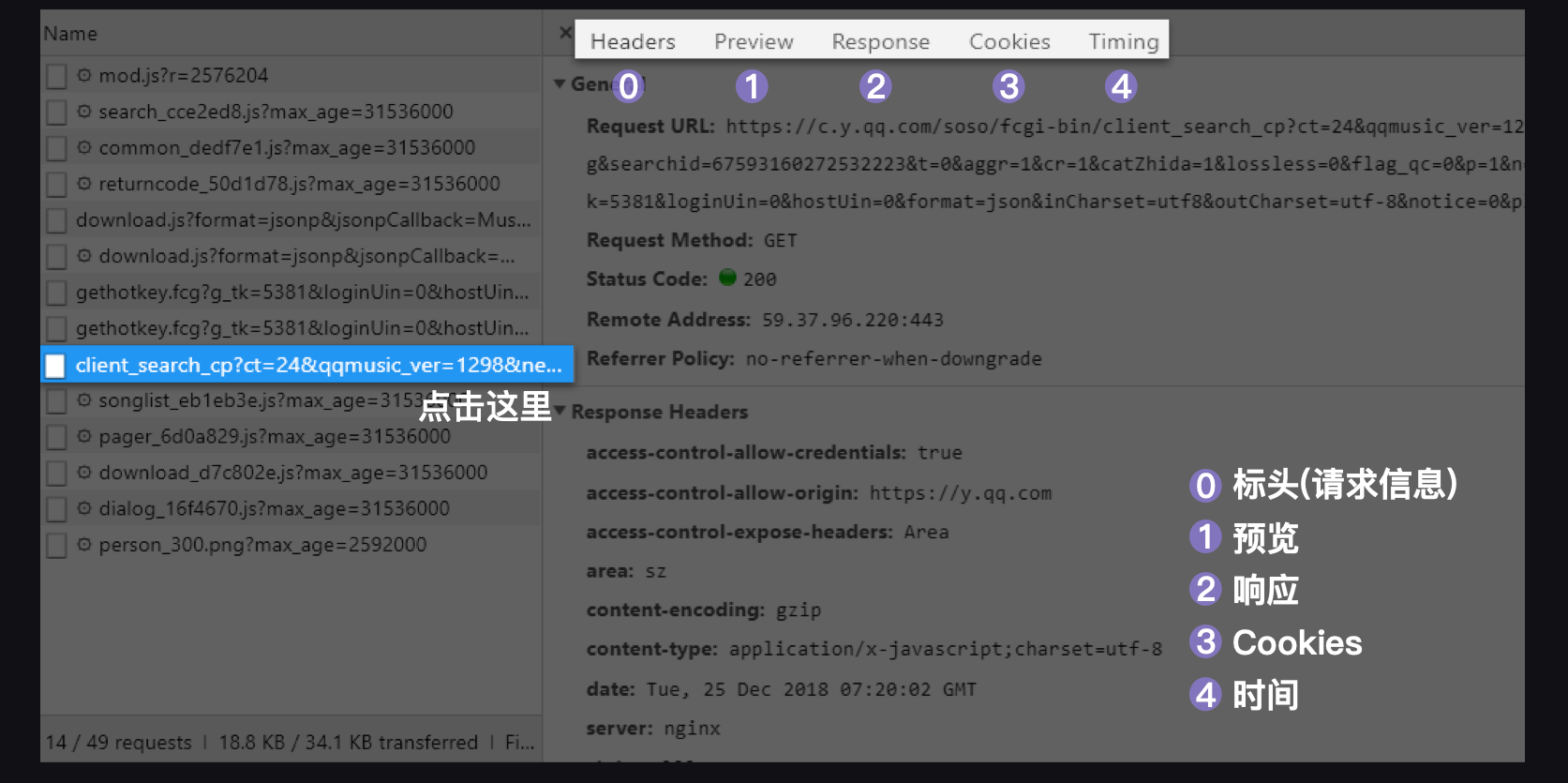
从左往右分别是:Headers:标头(请求信息)、Preview:预览、Response:响应、Cookies:Cookies、Timing:时间。
点开Headers
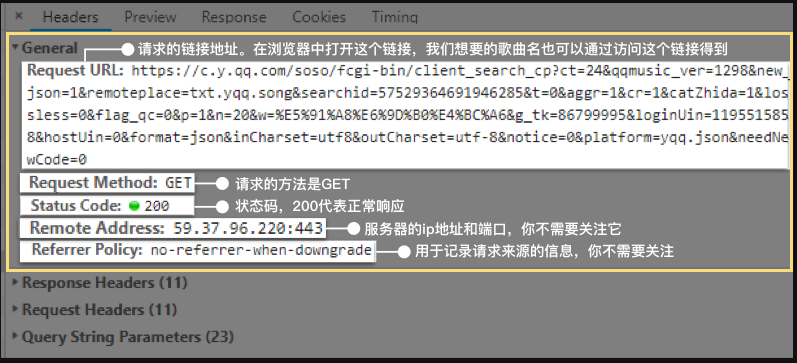
General里的Requests URL就是我们应该去访问的链接。如果在浏览器中打开这个链接,就会得到一个类似字典的数据结构,它是JSON数据。
json数据可以跨平台,跨语言工作。json和XHR之间的关系:XHR用于传输数据,它能传输很多种数据,json是被传输的一种数据格式。
我们用requests库的json方法可以解析这一数据。
# 引用requests库 import requests # 调用get方法,下载这个字典 res = requests.get(url) # 使用json()方法,将response对象,转为列表/字典 json = res.json() #遍历字典,获取所需资料 for i in json: for j in i: print(j)
带参数请求
每个url都由两部分组成。前半部分大多形如:https://xx.xx.xxx/xxx/xxx
后半部分,多形如:xx=xx&xx=xxx&xxxxx=xx&……
两部分使用?来连接。举例豆瓣网址,前半部分就是:https://www.douban.com/search
后半部分则是:q=%E6%B5%B7%E8%BE%B9%E7%9A%84%E5%8D%A1%E5%A4%AB%E5%8D%A1
它们的中间使用了?来隔开。
这前半部分是我们所请求的地址,它告诉服务器,我想访问这里。而后半部分,就是我们的请求所附带的参数,它会告诉服务器,我们想要什么样的数据。
这参数的结构,会和字典很像,有键有值,键值用=连接;每组键值之间,使用&来连接。
就像豆瓣。我们请求的地址是https://www.douban.com/search 而我们的请求所附带的参数是“海边的卡夫卡”:q=%E6%B5%B7%E8%BE%B9%E7%9A%84%E5%8D%A1%E5%A4%AB%E5%8D%A1(那段你看不懂的代码,它是“海边的卡夫卡”使用utf-8编码的结果)。
requests模块里的requests.get()提供了一个参数叫params,可以让我们用字典的形式,把参数传进去。
我们可以把Query String Parameters里的内容,直接复制下来,封装为一个字典,传递给params。只是有一点要特别注意:要给他们打引号,让它们变字符串。
通过改变params里的参数,可以找到自己想要的页面,如有的翻页会写成 "page= ",有的人名、作品名等等都能找到相应的参数,需要仔细分析
请求头 Request Headers
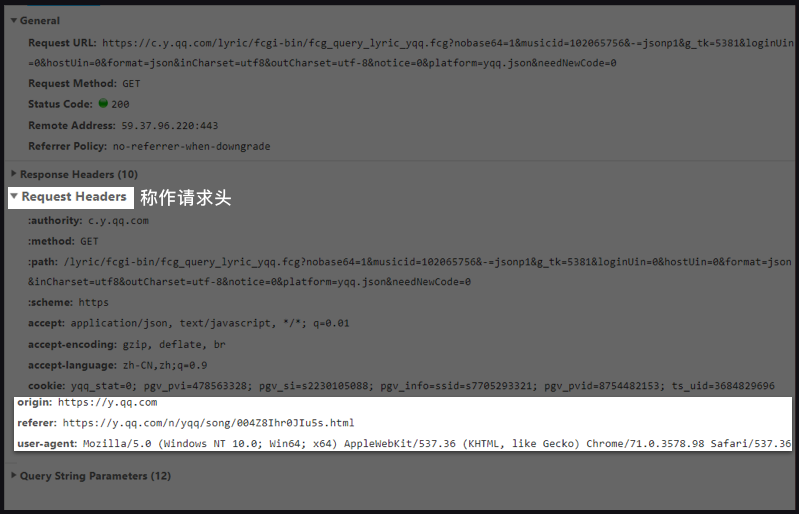
每一个请求,都会有一个Request Headers,我们把它称作请求头。它里面会有一些关于该请求的基本信息,比如:这个请求是从什么设备什么浏览器上发出?这个请求是从哪个页面跳转而来?
如上图,user-agent(中文:用户代理)会记录你电脑的信息和浏览器版本(如我的,就是windows10的64位操作系统,使用谷歌浏览器)。
origin(中文:源头)和referer(中文:引用来源)则记录了这个请求,最初的起源是来自哪个页面。它们的区别是referer会比origin携带的信息更多些。
如果我们想告知服务器,我们不是爬虫,而是一个正常的浏览器,就要去修改user-agent。倘若不修改,那么这里的默认值就会是Python,会被服务器认出来。
有趣的是,像百度的爬虫,它的user-agent就会是Baiduspider,谷歌的也会是Googlebot……如是种种。
Requests模块允许我们去修改Headers的值。
如此,只需要封装一个字典就好了。和写params非常相像。
而修改origin或referer也和此类似,一并作为字典写入headers就好。就像这样:
headers = { 'origin':'https://china.nba.com', # 请求来源 'referer':'https://china.nba.com', # 请求来源,携带的信息比“origin”更丰富 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36', # 标记了请求从什么设备,什么浏览器上发出 }
最后分享一个案例,爬取NBA网站上现役球员的资料
import requests,openpyxl wb=openpyxl.Workbook() sheet=wb.active sheet.title='NBA现役球员' sheet['A1']='姓名' sheet['B1']='国籍' sheet['C1']='身高' sheet['D1']='体重' sheet['E1']='场上位置' sheet['F1']='所属球队' sheet['G1']='出道年份' sheet['H1']='来源' url = 'https://china.nba.com/static/data/league/playerlist.json' headers = { 'origin':'https://china.nba.com', # 请求来源,本案例中其实是不需要加这个参数的,只是为了演示 'referer':'https://china.nba.com', # 请求来源,携带的信息比“origin”更丰富,本案例中其实是不需要加这个参数的,只是为了演示 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36', # 标记了请求从什么设备,什么浏览器上发出 } res = requests.get(url,headers=headers) playerlist=res.json() players=playerlist['payload']['players'] print(len(players)) for player in players: #print('姓名:'+player['playerProfile']['displayName']) #print('国籍:'+player['playerProfile']['country']) #print('身高:'+player['playerProfile']['height']) #print('体重:'+player['playerProfile']['weight']) #print('位置:'+player['playerProfile']['position']) #print('球队:'+player['teamProfile']['city']+player['teamProfile']['displayAbbr']) #print('出道:'+player['playerProfile']['draftYear']) #print('来源:'+player['playerProfile']['schoolType']) #print() name=player['playerProfile']['displayName'] country=player['playerProfile']['country'] high=player['playerProfile']['height'] weight=player['playerProfile']['weight'] position=player['playerProfile']['position'] team=player['teamProfile']['city']+player['teamProfile']['displayAbbr'] draftYear=player['playerProfile']['draftYear'] laiyuan=player['playerProfile']['schoolType'] sheet.append([name,country,high,weight,position,team,draftYear,laiyuan]) wb.save('NBA现役球员.xlsx')

