
Raft论文学习笔记
先附上论文链接 https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf
最近在自学MIT的6.824分布式课程,找到两个比较好的github:MIT课程《Distributed Systems 》学习和翻译 和 https://github.com/chaozh/MIT-6.824-2017
6.824的Lab 2 就是实现Raft算法。Raft是一种分布式一致性算法,提供了和paxos相同的功能和性能,但比paxos要容易理解很多。
一:Raft的一些概念
为了提升可理解性,Raft 将一致性算法分解成了几个部分:、
1)Leader选举:当之前的Leader宕机的时候,要选出新的Leader
2)日志复制:Leader从客户端接收日志然后复制到集群中的其它节点,并且要使其它节点的日志保持和自己相同
3)安全性:如果有任何的服务器节点已经commit一个日志条目到它的状态机中,那么其它服务器节点不能在同一个日志索引位置commit一个不同的指令。
Raft将系统中的角色分为领导者(Leader)、跟随者(Follower)和候选人(Candidate):
Leader:通常情况下系统中只有一个Leader,其它服务器节点都是Follower。Leader负责接受客户端的请求并把日志同步到Follower。Raft 中日志条目都遵循着从Leader发送给其它节点这一个方向,这也是Raft追求简单易懂的体现,像Viewstamped Replication和Zookeeper日志条目的流动都是双向的,导致机制比较复杂。
Follower:接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
Candidate:Leader选举过程中的临时角色。
这三种角色的转换如下图:
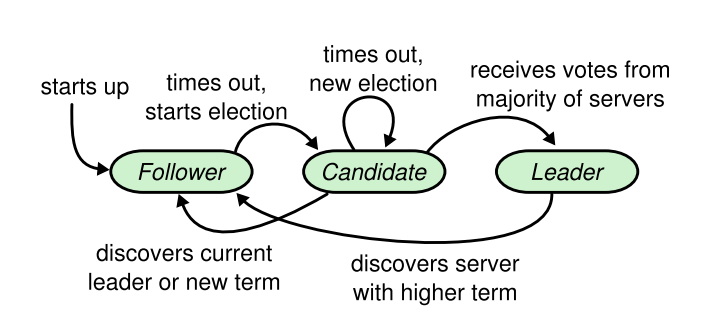
Follower只响应来自其他服务器的请求。如果Follower接收不到消息,那么它就会变成Candidate并发起一次选举。获得集群中大多数选票的Candidate将成为Leader。Leader在宕机之前一直都会是Leader。
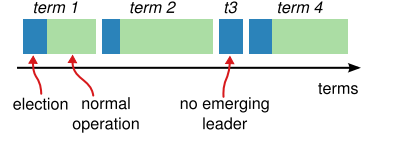
Raft算法将时间分为一个个的任期(term),每一个term的开始都是Leader选举。在成功选举Leader之后,Leader会在整个term内管理整个集群。如果Leader选举失败,该term就会因为没有Leader而结束,在下一个term继续选Leader。
二:Leader选举
Raft 使用一种心跳机制来触发领导人选举。在初始状态,服务器节点都是Follower,如果Follower在一段时间(election timeout)内没有接收到Leader的心跳,则认为Leader挂了。此时Follower会将term加1,并转换为Candidate状态。然后Follower会向集群中其它服务器节点发送RequestVote消息请求其它节点投票给自己。一个节点收到RequestVote 消息后通过比较两份日志中最后一条日志条目的索引值和term得出谁的日志比较新。如果本节点的日志比较新,则会拒绝掉该投票请求,否则赞成。当Candidate得到大多数节点的赞成后,则此Candidate会成为Leader,并不断发送心跳给其它节点,以维持其Leader地位。
这种选举方法保证了Leader有着最新的日志,这样就能保证日志条目都遵循着从Leader发送给其它节点这一个方向,使Raft更容易理解。
如果选票被瓜分,会导致所有Candidate都无法得到大多数节点的赞成票,会导致选举失败。在下一轮选举中,同样也会出现这种选票瓜分的情况。为了避免出现这种问题,raft将选举超时时间随机化,这样就不会出现多个Candidate同时选举超时,再同时发起选举的情况。这样在第一个选举超时的Candidate会有最大的term,发送RequestVote从而成为Leader。
三、日志复制
Leader被选举出来后,就可以接受客户端的请求了。客户端的每个请求都包含一条被Replicated State Matchine执行的指令。Leader把客户端发过来的指令作为一条新的日志条目加到日志中区,随后发起AppendEntries RPC请求将指令发送给其它节点。当日志条目被安全地复制(大多数节点已经将该日志条目写入日志当中)后,则Leader将这个日志条目应用到它的状态机中,然后把执行结果返回给客户端。
那么Follower 是怎么接受来自Leader 的AppendEntries 的呢?先说一下一致性检查的过程。由于Follower可能落后Leader一些日志(比如之前挂了后来恢复了),或者比Leader多一些日志(比如这个结点是上一个term的Leader,有一些日志还没Commited就挂了),而raft要求Follower要完整复制Leader的日志,因需要进行一致性检查。在发送AppendEntries RPC时,Leader会包含最新日志的前一个条目的索引和任期号。如果Follower在日志中找不到包含相同索引号和任期号的条目,那么它将会拒接接受新的日志条目。
Leadre针对每个Follower维护了一个nextIndex,表示下一个要发送给Follower的日志条目的索引。当一个Leader刚被选举出时,将nextIndex初始化为自己最新日志的index+1。如果AppendEntries 请求被拒绝,Leader会减小nextIndex进行重试,直到在某个位置Leader和Follower的日志一致,则AppendEntries RPC成功,Follower上冲突的日志条目会全部删除并加上Leader的日志。这时,Follower的日志就会和Leader保持一致。
之前任期日志条目的处理
本轮任期的Leader不能提交一个之前任期内的日志条目,否则可能会出现下述情况
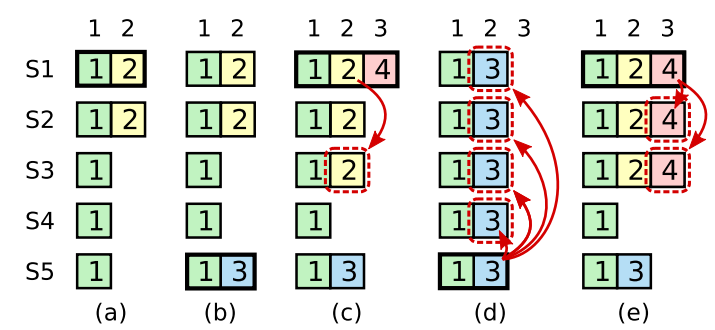
- 在阶段a,term为2,S1是Leader,且S1写入日志(term, index)为(2, 2),并且日志被同步写入了S2;
- 在阶段b,S1离线,触发一次新的选主,此时S5被选为新的Leader,此时系统term为3,且写入了日志(term, index)为(3, 2);
- S5尚未将日志推送到Followers变离线了,进而触发了一次新的选主,而之前离线的S1经过重新上线后被选中变成Leader,此时系统term为4,此时S1会将自己的日志同步到Followers,按照上图就是将日志(2, 2)同步到了S3,而此时由于该日志已经被同步到了多数节点(S1, S2, S3),因此,此时日志(2,2)可以被commit了(即更新到状态机);
- 在阶段d,S1又很不幸地下线了,系统触发一次选主,而S5有可能被选为新的Leader(这是因为S5可以满足作为主的一切条件:1. term = 5 > 4,2. 最新的日志为(3,2),比大多数节点(如S2/S3/S4的日志都新),然后S5会将自己的日志更新到Followers,于是S2、S3中已经被提交的日志(2,2)被截断了,这是致命性的错误,因为一致性协议中不允许出现已经应用到状态机中的日志被截断。
为了避免这种错误,Raft要求只有Leader当前term里的日志可以被提交。当然,由于日志匹配特性,之前的日志条目也会被提交。这样的话由于term被更新,就不会出现4里面说的S5会被选为leader的情况了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号