让低版本gitlab焕新 —— 如何在低版本gitlab上实现高版本API功能
前言:本文主要记录了基于低版本gitlab(v3 api)实现in-line comment功能的过程中踩过的坑及相应的解决方案,理论上其他低版本gitlab不具备的API都可以参照此类方法进行实现(只要能通过页面操作抓取到相关接口),从而让低版本gitlab焕发新生~
背景
近期我们落地了AI Code review实践,在CICD流程中当merge request创建时,会基于MR的diff代码进行AICR并将问题以comment的形式提交,如下图所示:
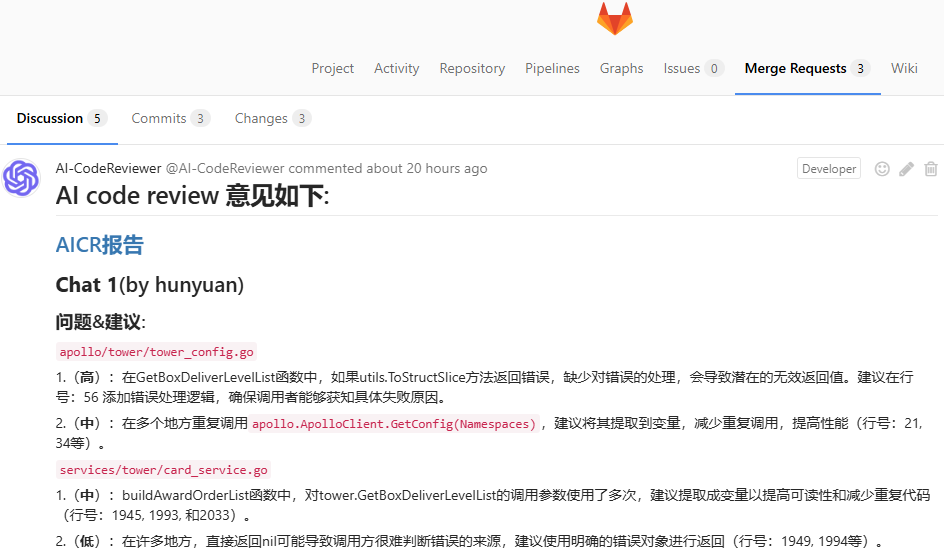
目前我们希望进一步改进体验:除了整体的comment,也希望能将所有问题分别以in-line comment的形式插入到对应代码片段的对应行号中,以便形成研发CR时边看代码边看问题的无缝体验(无需频繁在Discussion问题列表和代码Changes面板之间切换)
但因为一些历史原因,我们公司目前还存在新旧两套gitlab,其中旧的gitlab版本较低(8.16 v3 API),没有现成的in-line comment API。下文将分为两个阶段来陈述如何在低版本gitlab上实现in-line comment功能以及如何兼容一些特殊场景以增强用户体验
第一阶段(初步实现功能)
需求:
根据AI返回的行号,将对应问题in-line comment到代码changes面板上,方便开发CR代码时就能看到相关问题,期望效果如下图所示:
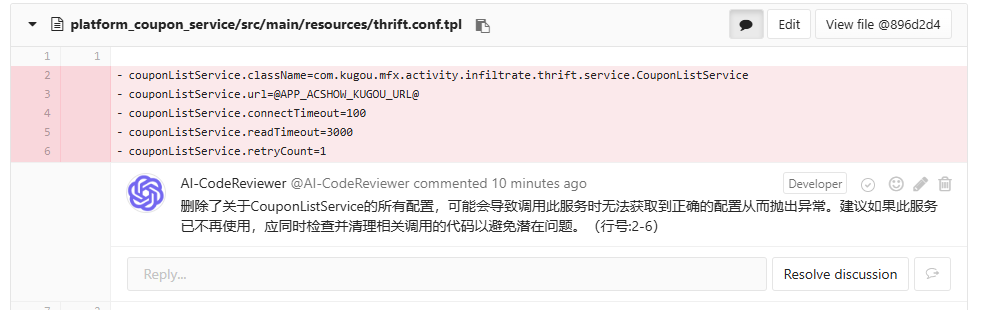
问题:
低版本gitlab没有in-line comment API
解决方案:
通过抓取页面操作相关接口,最终通过模拟登录态并获取所有所需参数,从而构造出与在web页面上操作等价的in-line comment请求
解决过程:
1)接口分析
通过抓取web页面上的in-line comment请求,发现有一个notes请求。经过分析与回放尝试,发现有如下必传参数是需要根据情况动态获取的:
- merge_request_diff_head_sha (head_sha)
- target_id (Merge Request 的唯一 ID)
- note[noteable_id] (与target_id一致)
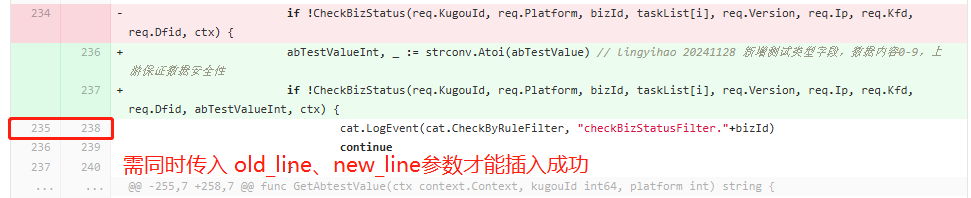
- note[position] (新/旧文件路径、base_sha、start_sha、head_sha、new_line、old_line等;其中因为new_line、old_line踩的坑最多,下文会提到)
- note[note] (评论的内容)
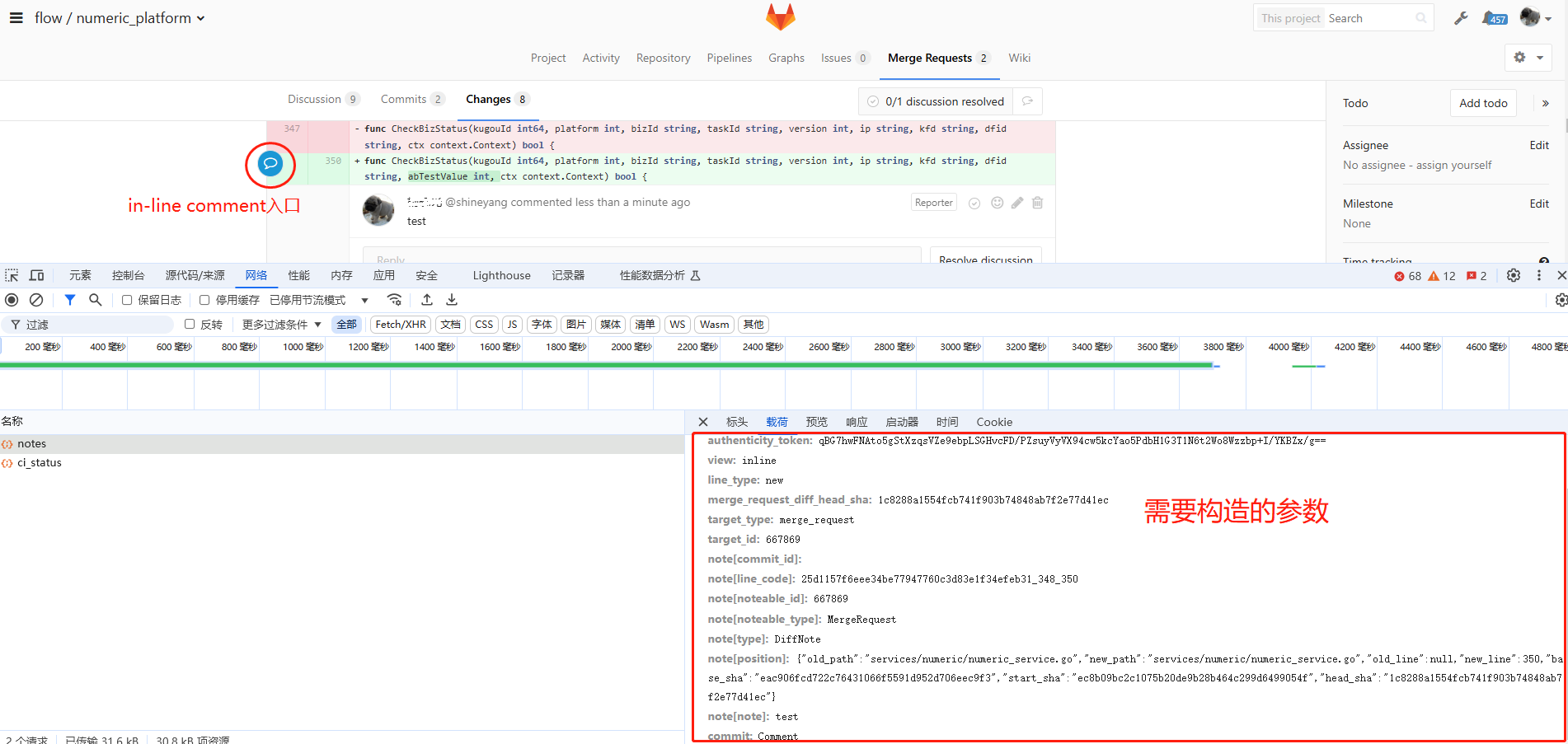
2)参数获取
- base_sha、start_sha、head_sha 等参数可以通过 `/projects/:id/merge_requests/:merge_request_id/versions` 接口获取
- old_path、new_path等参数可以通过 `/projects/:id/merge_requests/:merge_request_id/changes` 接口获取
- authenticity_token 需要访问被操作页面,然后从页面中解析获取(可结合BeautifulSoup对页面结构进行解析)
- 同时还需要构造登录态(基于有权限的账号登录后保存session,然后结合requests.Session()进行后续请求)
- new_line这一阶段是直接使用AI提供的行号(old_line没有传,因为测试场景是纯新增代码old_line不传也能成功,后来才发现是坑)
3)请求构造
按相关结构组装这些参数,构造与页面操作等价的in-line comment请求。
至此,便完成了基础的in-line comment功能
主要代码:
- in-line comment请求
def gitlab_v3_in_line_comment(self, project_id, mr_id, mr_iid, comment, file_name, old_line, new_line):
'''gitlab低版本无现成的in-line comment API,故通过页面抓取的接口曲线进行(需要模拟登录态并构造相关参数)
comment: 要备注的内容,即代码问题描述
file_name: AI返回的文件名
code_line: AI返回的行号
'''
# 获取gitlab session
session = self.gitlab_v3_get_login_session()
# Step 3: 重新提取评论页面的 authenticity_token(不能沿用登录页面的authenticity_token)
path_with_namespace = self.gitlab_get_project_by_id(project_id).get('path_with_namespace', '')
comment_page = session.get(f"https://git.kugou.net/{path_with_namespace}/merge_requests/{mr_iid}")
soup = BeautifulSoup(comment_page.text, "html.parser")
authenticity_token = soup.find("input", {"name": "authenticity_token"})["value"]
# print("MR页面authenticity_token", authenticity_token)
# step 4: 获取MR相关信息
base_sha, start_sha, head_sha = self.gitlab_v3_get_mr_diff_versions(project_id, mr_id) # 获取MR的diff版本信息
# 根据AI返回的文件名,获取old_path、new_path
result = self.gitlab_v3_get_single_mr_changes(project_id, mr_id, file_name)
if result:
old_path = result[0].get('old_path', '')
new_path = result[0].get('new_path', '')
else:
old_path = new_path = file_name
# Step 5: 构造评论请求
comment_url = f"https://git.kugou.net/{path_with_namespace}/notes"
comment_payload = {
"utf8": "✓",
"authenticity_token": authenticity_token,
"view": "inline",
"line_type": "", # 新增代码传new,已有代码传空(但是都为空也能成功)
"merge_request_diff_head_sha": head_sha,
"target_type": "merge_request",
"target_id": f"{mr_id}", # Merge Request 的唯一 ID
"note[commit_id]": "",
# "note[line_code]": "25d1157f6eee34be77947760c3d83e1f34efeb31_235_238", # 页面锚点id_oldline_newline,非必须参数
"note[noteable_id]": f"{mr_id}", # [必须]与 target_id 一致
"note[noteable_type]": "MergeRequest",
"note[type]": "DiffNote",
# "note[position]": '{"old_path":"GuessSongActivityService.java","new_path":"GuessSongActivityService.java","new_line":55,"base_sha":"29f230c853e957e049c7ef3cf8ba7435f82479ef","start_sha":"29f230c853e957e049c7ef3cf8ba7435f82479ef","head_sha":"3160984ed116026742a911ec7d8cf332e4fd4c3c"}',
"note[position]": json.dumps({
"old_path": old_path, # 旧文件路径,通过gitlab_v3_get_single_mr_changes接口获取
"new_path": new_path, # 新文件路径,同上
"old_line": old_line, # 若是新旧行号不一致的情况,old_line/new_line均必传,否则会报错(采用页面解析方案获取,第一阶段未传该参数踩坑了)
"new_line": new_line, # 针对新增的代码进行in-line comment,只需要传入该参数即可,old_line可不传
"base_sha": base_sha, # MR的diff版本信息,通过gitlab_v3_get_mr_diff_versions接口获取
"start_sha": start_sha, # 与base_sha获取方法一致
"head_sha": head_sha # 与base_sha获取方法一致
}),
"note[note]": comment, # 具体的评论内容
"commit": "Comment"
}
# print('\n -----构造的评论参数----- ', comment_payload)
# Step 6: 发送评论请求
response = session.post(comment_url, data=comment_payload)
# print('评论结果 : ', response.status_code, response.text)
return response- gitlab session处理
def gitlab_v3_get_login_session(self):
'''
gitlab登录态
若缓存中的session数据未失效,则直接从缓存中获取相关数据并构造session
若已失效,则重新登录获取session,并缓存
'''
SESSION_CACHE_KEY = "gitlab_session_for_AICR"
SESSION_TIMEOUT = 3600 * 8
# 获取已认证的session,如果缓存存在则直接使用
session_data = cache.get(SESSION_CACHE_KEY)
if session_data:
# 从缓存恢复session
session = requests.Session()
session.cookies.update(session_data.get("cookies", {}))
session.headers.update(session_data.get("headers", {}))
return session
# 如果缓存不存在,重新登录并缓存
# Step 1: 获取登录页面并提取 authenticity_token
login_url = "https://git.kugou.net/users/sign_in"
session = requests.Session()
login_page = session.get(login_url)
soup = BeautifulSoup(login_page.text, "html.parser")
auth_token_input = soup.find('input', {'name': 'authenticity_token', 'type': 'hidden'})
if auth_token_input:
authenticity_token = auth_token_input['value']
else:
return ''
# Step 2: 登录
login_payload = {
"user[login]": settings.AICR_USER, # AI-CodeReviewer用户名
"user[password]": settings.AICR_PASS, # AI-CodeReviewer密码
"authenticity_token": authenticity_token # 登录页面的authenticity_token
}
response = session.post(login_url, data=login_payload)
# 检查是否登录成功(根据 GitLab 的页面返回内容或状态码判断)
if response.status_code != 200 or "Sign in" in response.text:
logger.error("gitlab Login failed. Please check credentials.")
else:
# 缓存session(Session对象无法直接序列化,需要提取cookies和headers,以便后续构造)
session_data = {
"cookies": session.cookies.get_dict(),
"headers": dict(session.headers)
}
cache.set(SESSION_CACHE_KEY, session_data, timeout=SESSION_TIMEOUT)
return session
第二阶段(特殊场景兼容)
问题:
第一阶段功能上线运行一段时间后,我们发现很多AICR问题没有成功提交in-line comment,经过分析主要是以下两种原因:
- AI返回的行号在gitlab MR changes面板上被隐藏折叠了(我们默认情况下是没法在web页面选中这个行号的,自然也是没法基于该行号提交comment)
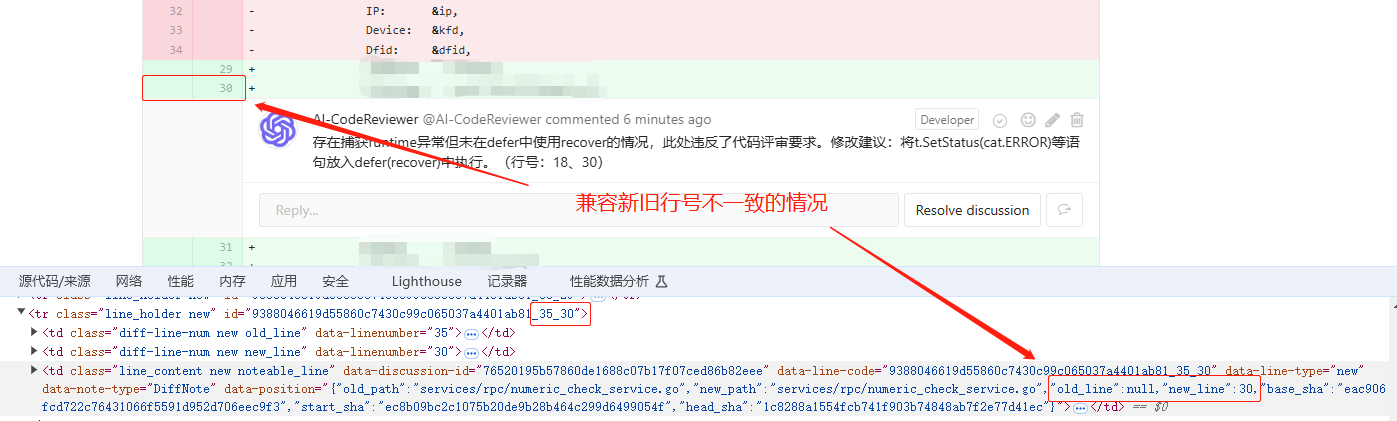
- 针对变更的代码,会存在old_line、new_line不一致的场景,这种情况下需要同时传对新/旧行号才能成功添加comment(而新旧行号只有页面上能获取到,也没有对应api可以获取)
预期需求:
针对上述问题,我们希望达成如下效果,以改进用户体验
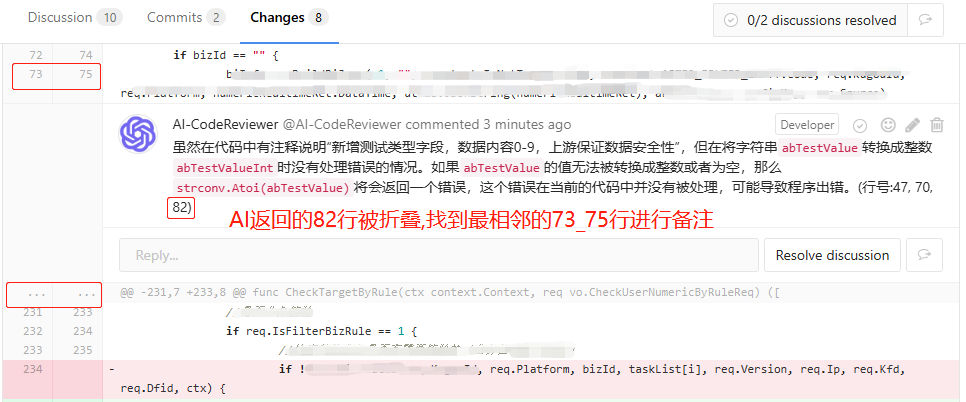
1)当AI返回的行号在MR changes面板被隐藏折叠时,将相关AICR问题备注到最相邻的那一行,如下所示
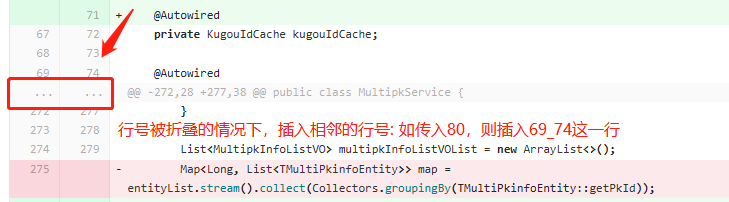
2)针对变更代码 old_line、new_line不一致的情况,获取页面上实际展示的新/旧行号构造请求
解决方案:
1)构造登录态请求diffs.json接口,拿到所有diff文件的html源码
2)结合BeautifulSoup解析步骤1拿到的html源码,找到对应文件的div,然后拿到所有行号的data-position信息
3)构造line_mapping_dict,用来判断传入的行号参数的有效性,并做兼容性处理
解决过程:
1)页面分析
MR Changes面板每一个文件就是一个大的div块,其中每一行代码对应一个tr,然后每个tr中有相关行号信息,我们只需要解析整个页面然后获取相关行号即可
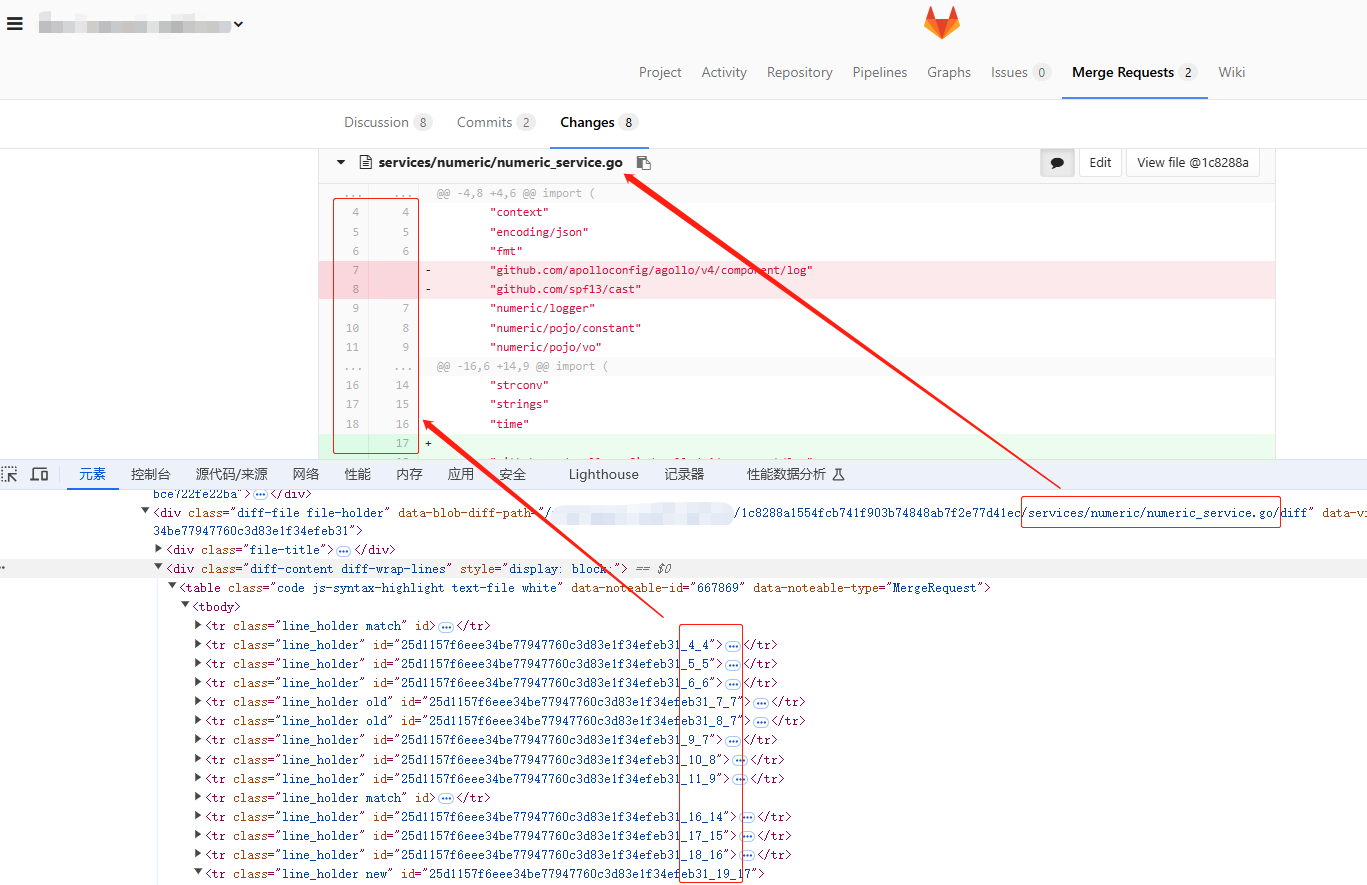
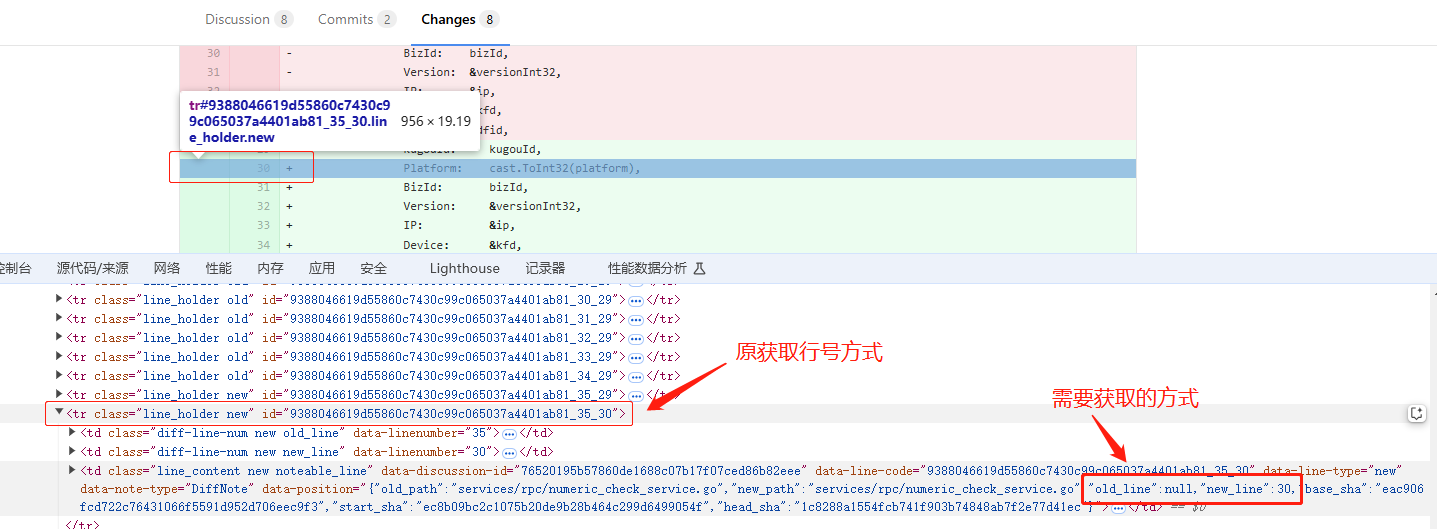
过程中还有一个小插曲:实际应用中发现行号在MR页面上不展示的情况下,对应in-line comment的行号参数也必须传null,如果传了<tr>标签中展示的原行号也会报错... 故继续在页面上找规律,发现在<td>标签中的data-position属性符合需求(页面上不展示的行号其值为null),故进一步调整解析逻辑
2)动态接口信息获取及解析
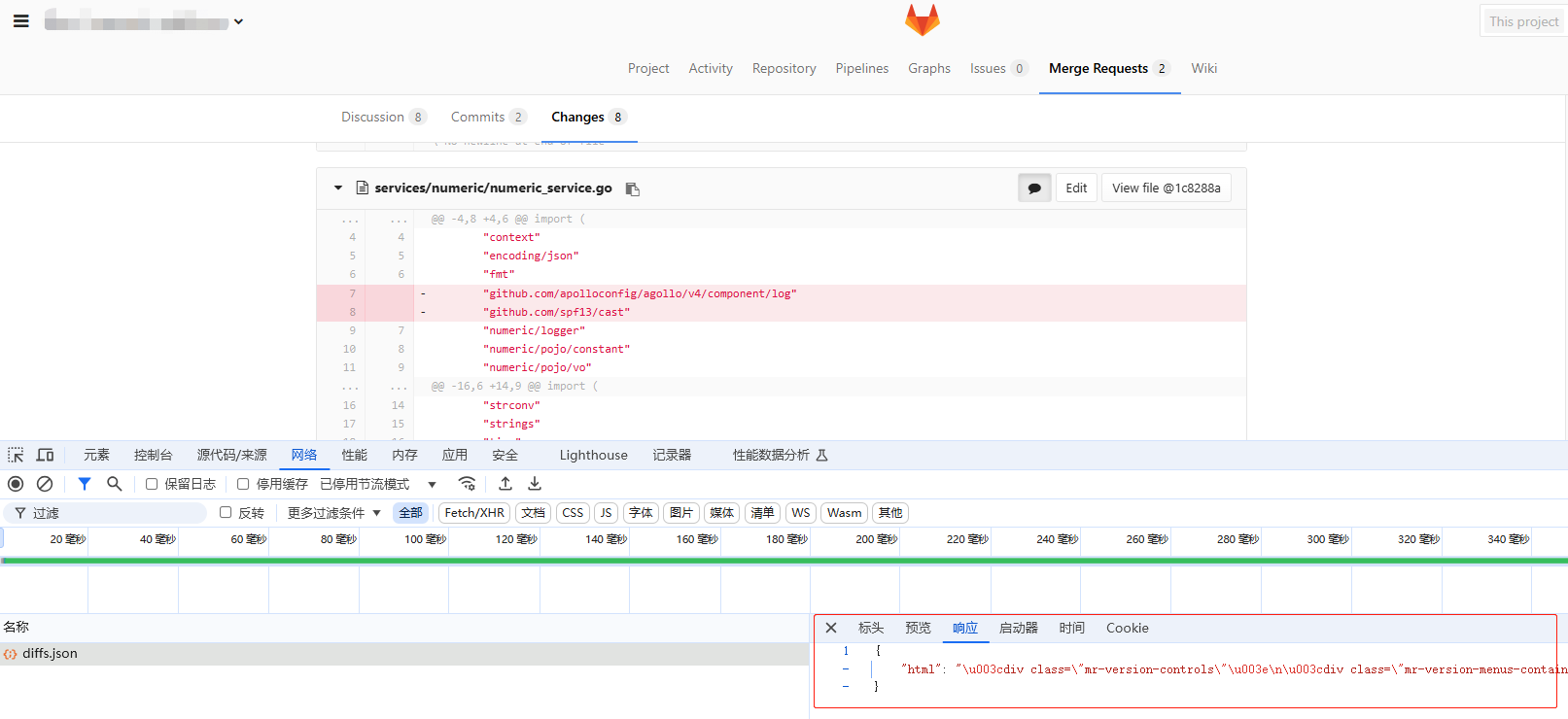
另外过程中还发现MR的change页面不是一个纯静态页面,代码diff信息是通过接口动态获取的。故没法直接通过访问MR的URL来拿到代码diff内容,需要调用相应的diffs.json接口获取,所以我们需要解析该接口的返回内容(好在接口返回内容也是html格式,可以结合BeautifulSoup快速处理)
3)根据AI给定的行号判定有效的新/旧行号
将每个文件在页面上展示的新/旧行号都存储下来,然后基于AI给定的行号进行有效性判定:
- 若给定的行号不存在,则返回最页面上展示的最相邻的新/旧行号
- 若存在,则直接返回对应的新/旧行号
踩完各种坑之后,最终效果如下:
主要代码:
- gitlab MR changes页面-代码片段行号信息获取
def get_mr_changefile_display_lines(self, project_id, mr_iid, file_name):
'''
获取MR changes板块对应文件的所有展示出来的行号,用于后续处理兼容以下特殊情况:
1. AI返回的行号在MR changes板块被折叠隐藏
2. 修改代码的情况下,代码行号发生变化,in-line comment的行号需要同时传对应的old_line和new_line
return: line_mapping_dict eg: {4: (4, 4), 5: (5, 5), 357: (357, 360), 360: (357, 360)}
'''
session = self.gitlab_v3_get_login_session()
path_with_namespace = self.gitlab_get_project_by_id(project_id).get('path_with_namespace', '')
resp = session.get(f"https://git.kugou.net/{path_with_namespace}/merge_requests/{mr_iid}/diffs.json")
html_content = resp.json().get('html', '')
# 使用 BeautifulSoup解析HTML片段
soup = BeautifulSoup(html_content, 'html.parser')
# 定义目标文件的关键字
target_keyword = f"{file_name}/diff" # 如 services/numeric/numeric_service.go/diff
# 查找 data-blob-diff-path属性包含特定字符串的 div标签
target_div = soup.find(
'div',
attrs={"data-blob-diff-path": lambda value: value and target_keyword in value}
)
# 如果找到目标div,则进一步解析
if target_div:
# 查找该div下符合条件的所有class包含line_content和noteable_line的<td>,形如<td class="line_content new noteable_line old">
td_elements = target_div.find_all(
'td',
attrs={'class': lambda x: x and set(['line_content', 'noteable_line']).issubset(x.split())}
)
# 提取所有行号,并构造行号映射字典,形如:{4: (4, 4), 5: (5, 5), 357: (357, 360), 360: (357, 360)}
line_mapping_dict = {}
for td in td_elements:
# 获取 data-position 属性
data_position = td.get('data-position')
if data_position:
try:
# 将 JSON 字符串解析为字典
position_data = json.loads(data_position)
old_line = position_data.get('old_line')
new_line = position_data.get('new_line')
# 以old_line、new_line作为key分别存储一次,方便后续可以根据任意匹配行号查询到相应的old_line、new_line对
if old_line: line_mapping_dict[old_line] = (old_line, new_line) # 避免存这种 None: (None, 357)
if new_line: line_mapping_dict[new_line] = (old_line, new_line)
except json.JSONDecodeError:
logger.error("Failed to decode JSON in data-position: %s", data_position)
# print(line_mapping_dict)
return line_mapping_dict
else:
# print(f"未找到包含{target_keyword}的div")
return None
- 行号有效性判定及兼容处理逻辑
def find_line_mapping(line_number, line_mapping_dict):
"""
根据AI提供的行号在line_mapping_dict中查找相关联的新/旧行号。
如果行号存在,直接返回;如果不存在,返回最接近的行号。
return: (old_line, new_line)
"""
if not line_number or not line_mapping_dict:
return None
# print("line_number : ", line_number)
if line_number in line_mapping_dict:
return line_mapping_dict[line_number]
# 获取所有行号并排序
sorted_lines = sorted(line_mapping_dict.keys())
# 找到最接近的行号
closest_line = None
min_diff = float('inf') # 初始设置为无穷大,以便首次比较
for line in sorted_lines:
diff = abs(line - line_number)
if diff < min_diff:
min_diff = diff
closest_line = line
return line_mapping_dict[closest_line]
以上就是在低版本gitlab上实现in-line comment全过程了,希望能对也有此类需求的朋友提供一个参考思路

 浙公网安备 33010602011771号
浙公网安备 33010602011771号