浅析代码圈复杂度及认知复杂度
写在开始
圈复杂度用来描述一段代码“可测性”很好(可测性这里指需要构建完善的覆盖全面的单元测试需要付出多少代价),但它的设计模型很难得出一个很好的“可读性&可维护性”的测量结果
新版soanrqube引入了认知复杂度的概念,这个复杂度指标弥补了圈复杂度的一些不足,能更准确的反映一段代码的理解成本,以及维护这段代码的困难程度。
下面就简要的描述下,为何认知复杂度更适合用来评价一段代码的可读性及可维护性。
什么是圈复杂度?
圈复杂度(Cyclomatic complexity)是一种代码复杂度的衡量标准,在1976年由Thomas J. McCabe, Sr. 提出,目标是为了指导程序员写出更具可测性和可维护性的代码。
它可以用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径条数,也可以理解为覆盖所有可能的情况最少需要的测试用例数量。
代码圈复杂度的计算方法
通常采用的计算方法为点边计算法(当然还有节点判定法),计算公式为:
V(G) = e – n + 2
e 代表在控制流图中的边的数量(对应代码中顺序结构的部分),n 代表在控制流图中的节点数量,包括起点和终点(注:所有终点只计算一次,即便有多个return或者throw;节点对应代码中的分支语句)
假定有如下这样一段代码:
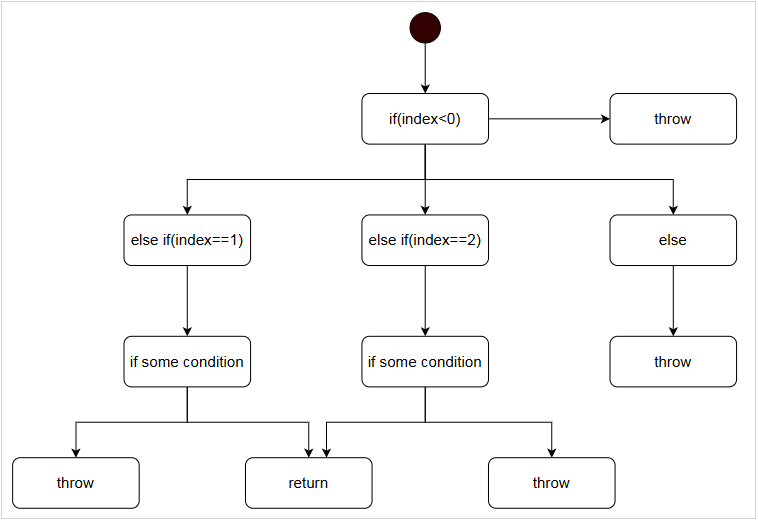
根据公式 V(G) = e – n + 2 = 12 – 8 + 2 = 6 ,上图的圈复杂段为6。
注:说明一下为什么n = 8,虽然图上的真正节点有12个,但是其中有5个节点为throw、return,这样的节点为end节点,只能记做一个
为什么要引入认知复杂度?
圈复杂度最初的目的是用来识别“难以测试和维护的软件模块”,它能算出最少的全覆盖的测试用例量,但是不能测出一个让人满意的“理解难度”。
这是因为同样圈复杂度的代码,不一定会具有相同的可维护性,我们看看下面的两个例子:

上面这两段代码具有相同的圈复杂度,但显然不具有相同的可读性和可维护性性,这就是圈复杂度的不足之处。
因为圈复杂度理论是在1976年提出的,它不包含一些现代的语言结构,比如try-catch、lambda。
并且,每个方法都默认有一个最小圈复杂度1,这就让我们无从得知,一个给定的类如果圈复杂度很高,它是一个大的易维护的类,还是一个很小很复杂的类。
为了解决上述这些问题,所以引入了“认知复杂度”,它将一段代码被阅读和理解时的复杂程度,估算成一个具体数字
认知复杂度如何评判?
认知复杂度评定基本原则
- 对线性的代码逻辑中,出现一个打断逻辑的东西,复杂度+1;
- 当打断逻辑的是一个嵌套时,复杂度+1;
- 忽略简写:把多句代码缩写为一句可读的代码,复杂度不会额外增加;
上面这种描述可能有点抽象,具体一点说,以下控制流结构会导致认知复杂度增加:
for, while, do while, 三元运算符, if/elif/else, catch语句, 跳转语句(goto/break/continue), 以及嵌套的控制流(每一层嵌套复杂度递增)
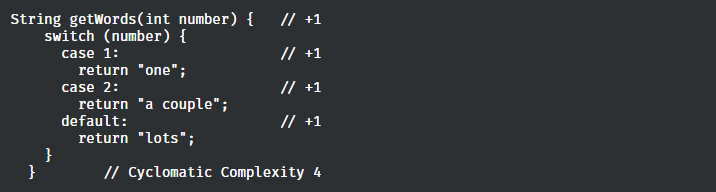
我们继续拿上面提到的两个例子举例:
圈复杂度对于getWord方法本身会默认有1的复杂度,每多一个case复杂度+1,所以最终圈复杂度为4
而认知复杂度,对于整个 switch 结构只增加1的复杂度,因为从可理解、可维护程度来说,多几个case并不会导致其增加(当然,大量的case也是我们应当尽力去避免的)
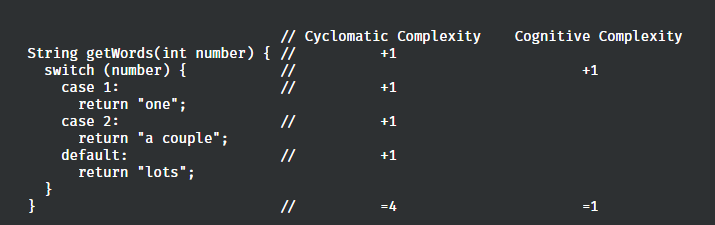
我们接着看另外一个例子:

如你所看到的,认知复杂度考虑到了使这个方法比前面提到的getWords()方法更难理解的因素——嵌套以及跳转语句
因此,虽然这两个方法的圈复杂度是一样的,但是它们的认知复杂度数据很好的反映了它们两者在可理解性/可维护性上的差异。
另外,相对于圈复杂度默认所有方法至少有1的复杂度,认知复杂度并没有这样一个评定规则,这对于entity等简单类的复杂度评判会更加友好和客观:
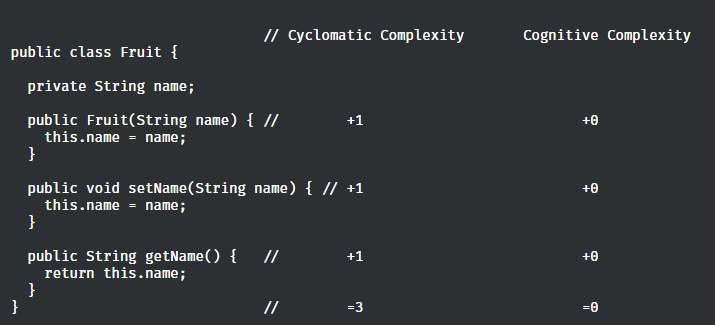
综上所述,认知复杂度作为代码的“可读性/可维护性”评定指标会更加合适。
附、代码复杂度与软件质量关系

以上复杂度数值可以理解为方法粒度,即如果某一个方法复杂度>30,那这个方法的可读性和可维护性就很低了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号