持续交付探索与实践(一):交付流水线的设计
一、前言
移动互联网时代,对于质量和效率的追求是永恒不变的目标,持续交付能力的建设则是提升效能和质量的重要的手段之一,自Jez Humble等人提出持续交付的理念以来,已经过去了10余年,随着微服务架构与云计算、容器化等新兴技术的发展,持续交付的概念又重新回到了大家的视野,各类相关的工具、产品和服务如雨后春笋般涌现。
虽然有了先驱者提出的先进思想和各大厂商的优秀工具,但是不同公司、不同产品、不同的技术栈、不同的开发与部署策略注定了持续交付的实施是因人而异的,很难有一种实践方式或工具能做到对所有业务场景的完美契合。所以,打造一套符合自身产品和业务特性的持续交付系统和最佳实践方案,就成了我们不断探索的方向。
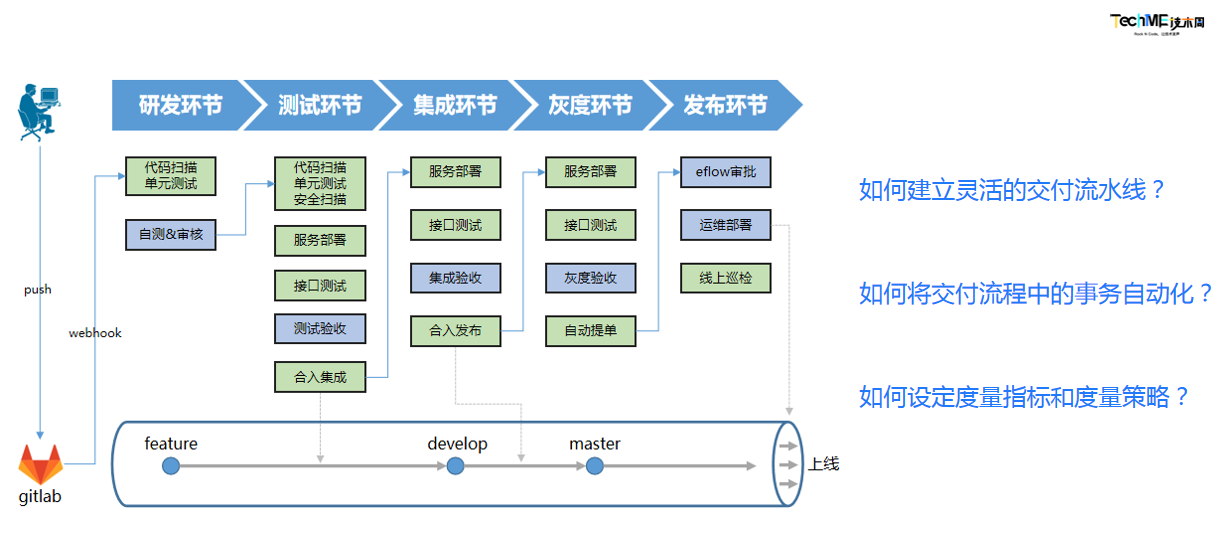
我们部门目前比较典型的交付流程如下图所示。可以看到,从开始研发到最终的项目上线,整个过程中需要进行大量的事务和活动,需要多个部门不同的角色参与其中,同时也会涉及到多套系统的操作。那么,如何建立灵活的交付流水线将这么多的事务和系统紧密连接起来?又如何将交付流程中的各项事务尽可能的自动化从而提升交付效率?以及如何设定合理的度量指标和度量策略,来更好的发现交付过程中所存在的问题并加以改进?
接下来我将通过一系列文章,来介绍下我们在这几个方向上的实践。
二、为什么要建立交付流水线?
20世纪初福特开创了首个汽车生产流水线,带来了汽车生产效率的革命性提升,最终让福特汽车开进了千家万户;软件行业也是如此,要想实现持续、快速的交付,交付流水线是核心。它就像一个故事的主线,贯穿整个研发流程,衔接并展示了从代码提交、构建、部署、测试直至最终发布的整个过程,为团队提供状态可视化和即时反馈的能力。
所谓状态可视化,就是能直观的看到分支、项目、版本等维度的进展及相应的问题,提升信息的透明度以便更好的对整个项目进行把控;而即时反馈,主要是为了将整个研发过程中不必要的损耗降至最低,比如研发提交新的代码后立即触发相应的构建,分支提测后立即通知测试进行介入等。通过流水线将关联事项紧密连接,可以最大程度的减少过程等待;同时,交付流水线通过与一系列工具链的结合,我们还相当于无形之中建立了一套统一的标准和流程。
随着业务的不断发展,我们的持续交付流水线主要经历了以下几个阶段。
三、交付流水线的架构演进
1)1.0时代:基于UI配置的流水线
平台建设初期,我们主要是通过jenkins的UI配置job,这种方式主要是通过jenkins web页面配置的方式来定义构建流程,同时结合相应的插件来实现一定流水线控制,比如通过multi job来实现多个子job的并行和串联,通过trigger插件传递当前构建的参数并触发下一个job,如:
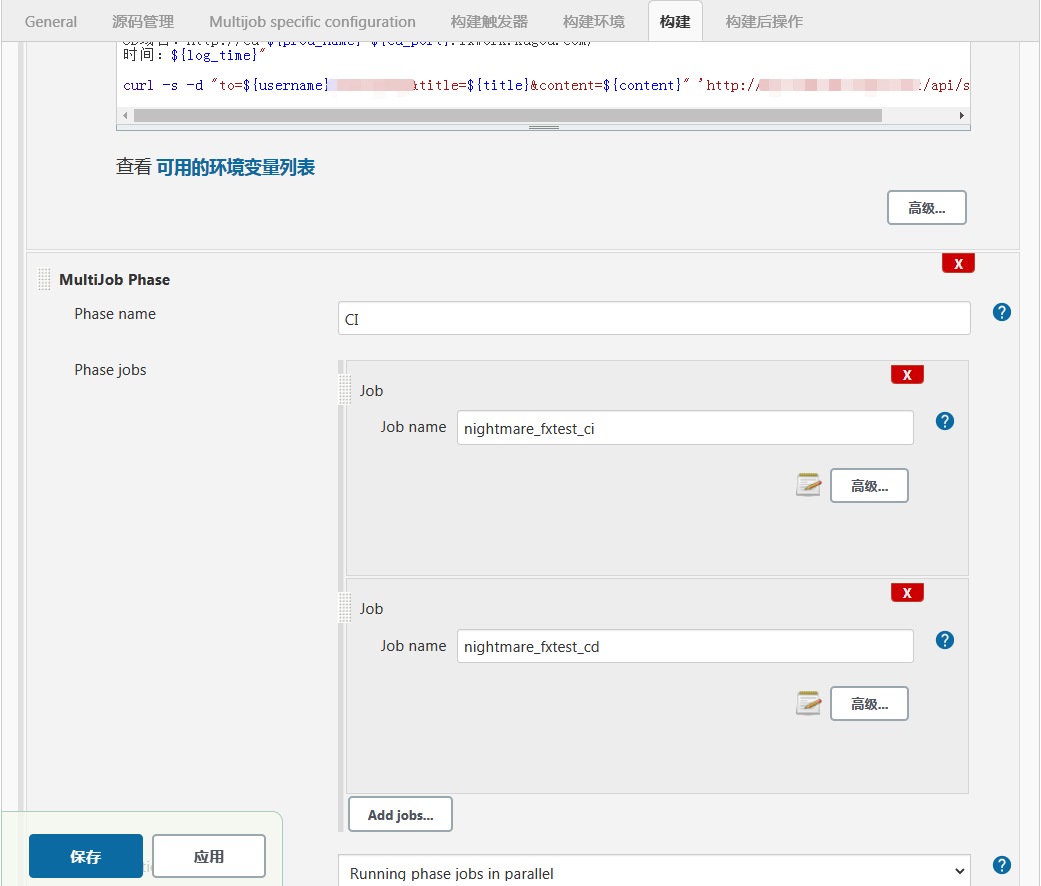
这种方式在我们平台建设初期应对简单的业务流程是完全够用的,但随着接入业务线的增加,该方式存在的问题和痛点逐渐暴露,比如:
- 每个业务线需要独立配置相应的流程,当基础流程发生变化时,所有的业务线都需要进行相应的调整,配置工作量较大
- 另外,由于对应的构建命令和脚本都是都是直接配置并应用在对应的job中的,新的配置应用会直接覆盖旧有的配置,若出现问题无法便捷的回滚
- 最后,复杂的流程配置较为繁琐,比如要用到multi job等一系列插件来进行串行、并行流程控制
2)2.0时代:基于jenkins pipeline的流水线管控
为了解决上述痛点,我们引入了jenkins pipeline。所谓Pipeline,就是一套运行于Jenkins上的工作流框架,将原本独立运行于单个或多个节点的任务连接起来,实现单个任务难以完成的复杂发布流程。
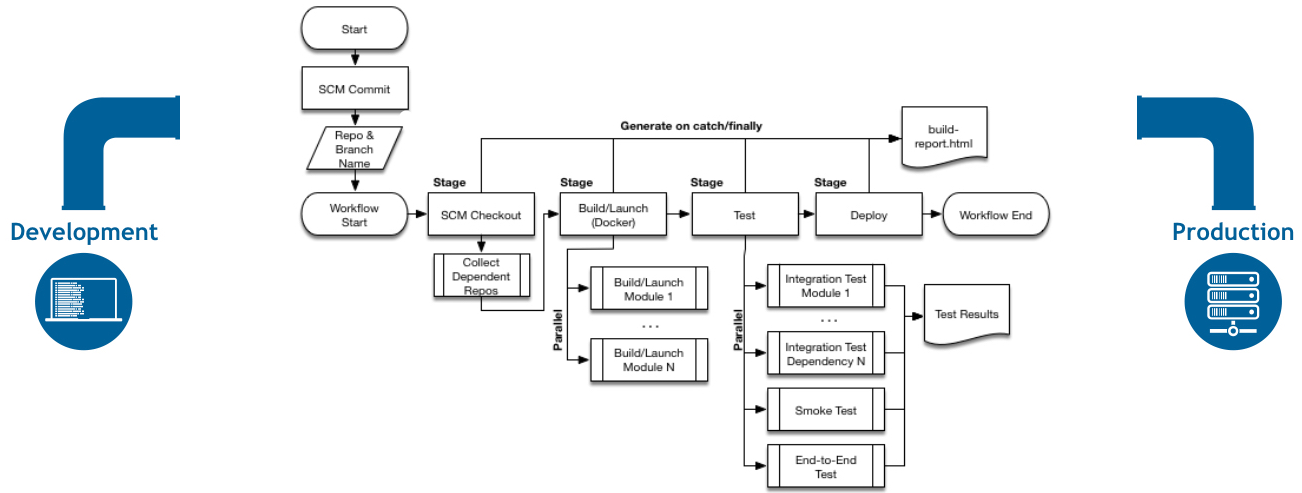
Pipeline的实现方式是一套基于Groovy的DSL(类似Gradle),任何发布流程都可以表述为一段Groovy脚本,并且支持从代码库直接读取,我们当时比较典型的构建pipeline结构示例如下:
pipeline {
agent {
label 'pipeline'
}
stages {
stage('代码扫描&单元测试') {
agent {
label 'sonar'
}
steps {
parallel '代码检测':{
script{
//省略...
}
},
'单元测试':{
script {
//省略...
}
}
}
}
stage('自动部署') {
when {
expression { env.skips.indexOf('deploy')<0 }
}
agent {
label 'make'
}
steps {
script {
//省略...
}
}
}
stage('接口自动化') {
when {
expression { env.skips.indexOf('iface')<0 }
}
agent {
label 'junit'
}
steps {
script {
//省略...
}
}
}
}
post {
always {
script {
sh "curl -X POST 'http://***.net/ci/api/commmon/fast_result/' -d 'env=${env.env}&branch=${env.ref}'"
}
}
}
}说明:
- Jenkinsfile : 是Pipeline的定义文件,由Stage,Node,Step组成,一般存放于代码库根目录下
- Stage : 一个Pipeline可以划分为若干个Stage,每个Stage代表一组操作。
- Node: 一个Node就是一个Jenkins节点,或者是Master,或者是Agent,是执行Step的具体运行期环境。
- Step: Step是最基本的操作单元,小到创建一个目录,大到构建一个Docker镜像,由各类Jenkins Plugin提供。
最终的构建流水线如下:
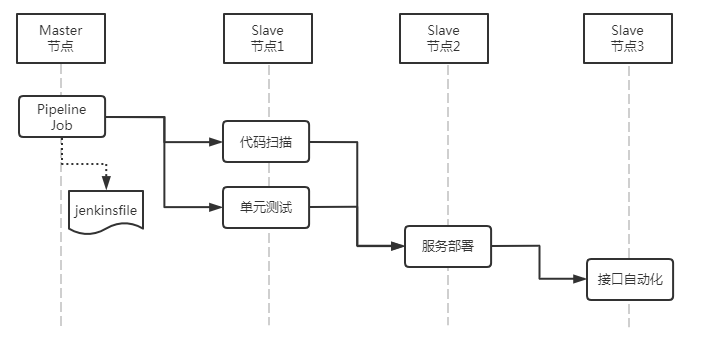
可以看到,基于这种方式能很方便的定义不同构建步骤的执行顺序、串联或并行状态、以及对应构建的所运行机器节点,相比1.0时代基于web化的配置主要有以下优点:
- 工作流配置代码化:改变原先手动配置每个jenkins job的方式,通过代码仓库的jenkinsfile控制整个构建流程,方便通过gitlab等版本控制系统去管理配置,无论是后续配置更新、回滚、还是批量复制创建都更加灵活方便,做到真正的pipeline as code;
- 工作流配置可下发:基于jenkinsfile的定制化流程配置职责可下发给对应的业务团队,对于持续交付平台来说只是读取不同仓库的jenkinsfile执行统一的pipeline job即可,避免了原先集中化配置任务带来的管理维护成本高的问题;
- 支持更复杂的工作流:有着更灵活的构建流程控制,方便顺序/并行执行,执行节点分配等。相比普通job,不用再去配置一堆前置、后置条件及对应的multijob。
3)3.0时代:自研的可编排、可视化事务流
随着公司业务不断的发展,各业务线研发管控流程的不断优化、细化,我们发现Pipeline流水线也逐渐显现出了它的局限性,已经无法满足各业务线日益增长的定制化需求了,比如:
1)自动化流程中穿插人工审核节点:针对涉及金钱及核心业务的需求我们往往需要更严格的审核流程,有时需要在自动化节点间增加额外的人工Code review确认节点
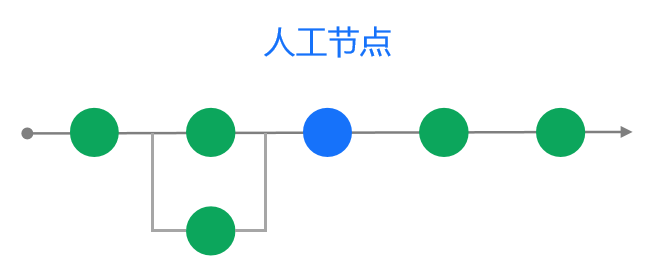
2)流程错误重跑希望只跑部分节点:当流程中的某个节点执行失败后,基于效率考虑我们只希望重跑特定的节点而非重新执行整个pipeline
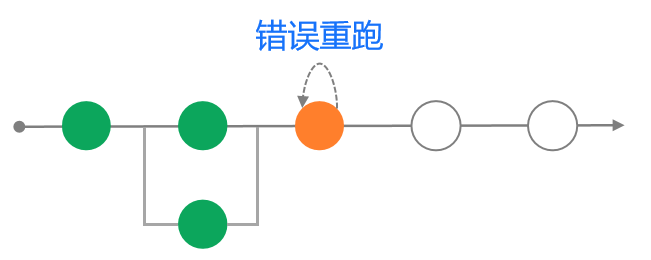
3)下游节点关联上游节点状态:比如冒烟测试失败后,我们希望将整个流程自动打回到提测前的状态

针对以上场景,如果基于jenkins pipeline来实现会有较大成本,而且也不便于拓展;为此,实现一套具有高度可定制化和可拓展性的交付流水线便被提上了日程,最终我们决定自研流水线底层组件并设计上层流水线模型,替代 Jenkins pipeline插件,以提供更加灵活的流水线编排和调度能力,核心模块设计方案如下:
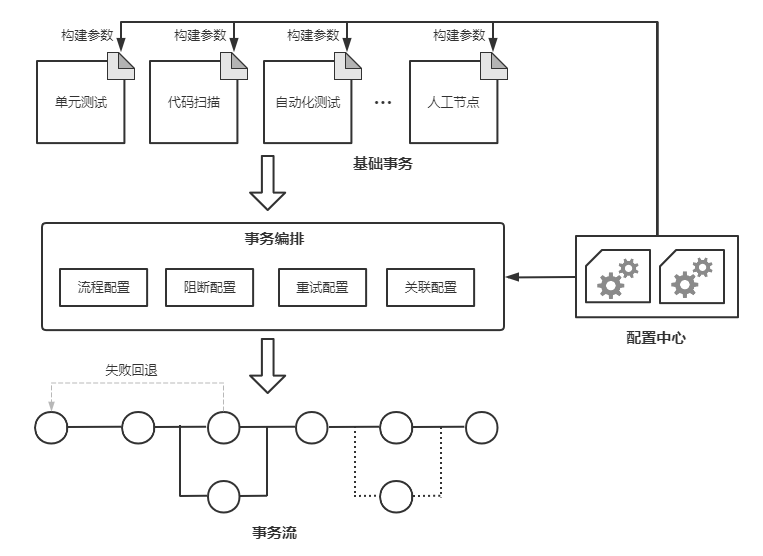
上述方案通过定义基础事务并细化事务关系配置实现了对事务的精细化编排,赋予了事务流更高的定制化能力。对于不同的业务线,无非就是基于基础事务传入不同的构建参数,同时结合业务自身要求对各类事务的构建顺序、构建关系进行定制化编排即可,较好的满足了各业务线差异化、特性化的研发交付流程
如果说1.0时代通过UI配置流水线的方式是雕刻版印刷术的话,那么3.0时代就是活字印刷术,每一类构建任务就好比一个个的字块,通过配置中心的事务编排能力就能实现不同的排列组合。很好的做到了可编排、可复用。

四、交付过程的可视化应用—让风险可以被看见
在完成上述的交付流水线改造后,我们又在此基础上封装了各个维度的自定义视图,并通过打通交付过程中所涉及到的其他外部系统,最终形成了目前的这套可视化的持续交付平台。系统部分截图如下:
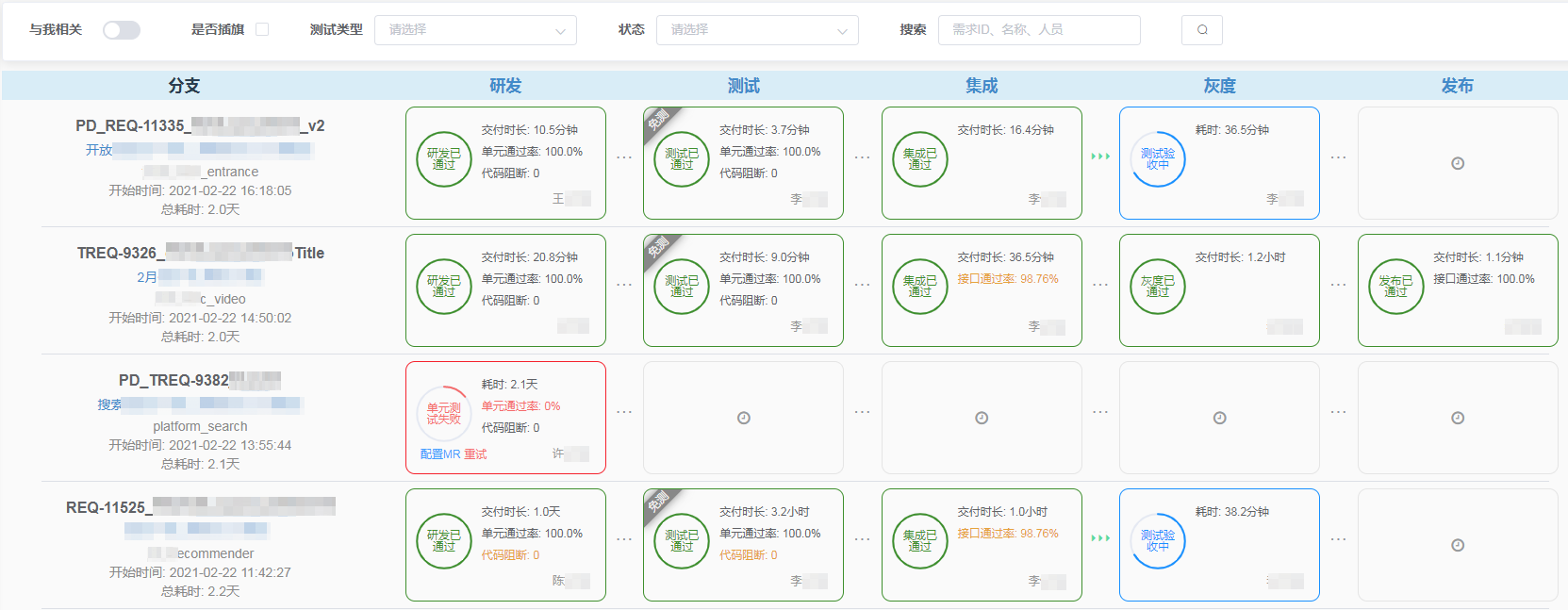
卡片化的整体视图,方便观察各需求对应分支的整体进展及相关核心数据,整个流水线按照我们的研发流程分为5个环节——研发、测试、集成、灰度、发布,每个环节对应实际研发流程中的特定阶段
结合各类筛选条件能较直观的看到哪些分支有质量问题阻断、对应的需求总体进展如何、某个版本有哪些需求进度偏慢,做到信息透明度的提升以便更好的对整个项目的进度和质量进行把控。
点击卡片,便可进入对应的环节视图,如下所示:
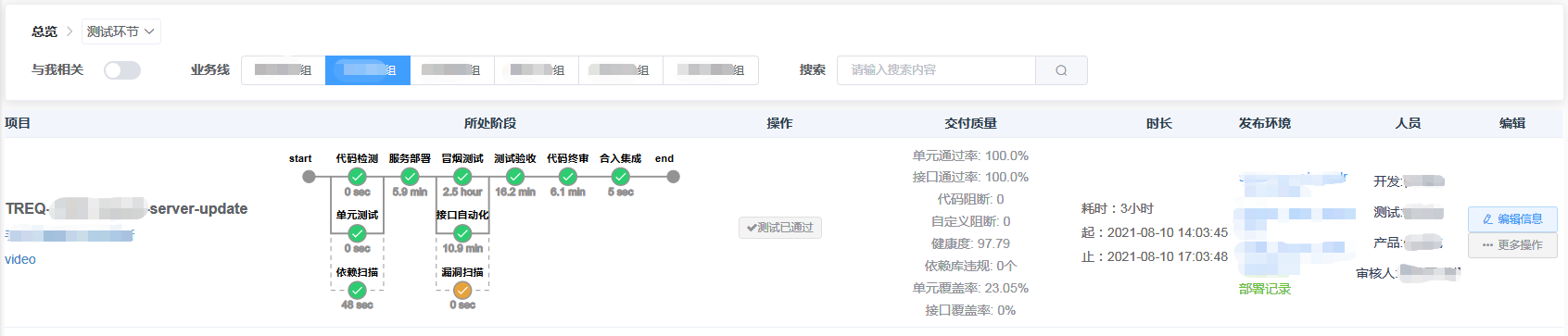
流水线化的环节视图,方便跟进对应环节的交付进展及对应的交付质量、交付效率情况,环节视图主要展示元素有:
- 流水线视图:重新设计的类blue ocean的视图,相比原生插件所提供的功能,我们能更方便的定制展示样式和交互方式,比如展示每个节点的构建时长、日志查看改为点击对应节点后弹窗展示等;
- 质量校验阀:针对所有需求设定对应的质量阀,达到一定的质量标准才允许通过。比如单元/接口通过率达到100%,代码规范问题为0,增量代码健康度>80等,能直观的看到当前分支存在哪些阻断问题;
- 需求信息:展示需求相关的关键信息,如项目管理平台需求单、分支对应的gitlab merge request、发布系统对应的申请单等等,方便查看相关信息并及时跟进;
- 流程操作:流程中需要人工节参与的环节所对应的操作项,如测试验收通过/不通过、代码审核通过/不通过等,通过打通研发流程中涉及的其他第三方系统,使得对应的操作入口统一,无需多系统切换。
五、交付流程中的多平台打通—打破组织间的墙
另外,整个研发交付过程中也会涉及到多个组织、多套系统,我们通过打通交付过程中所涉及到的其他外部系统,形成了整个研发流程的一站式体验;
比如,我们通过打通gitlab和项目管理平台,使得研发同学可以直接在系统上进行分支创建、合入以及技术方案的审核等;通过打通灰度系统和eflow流程系统,能直接在系统上进行灰度发布提单、灰度策略的调整以及结果查看等等。
通过上述实践,使得这套系统从单纯的交付流水线平台逐渐转变为了综合性的研发协作平台
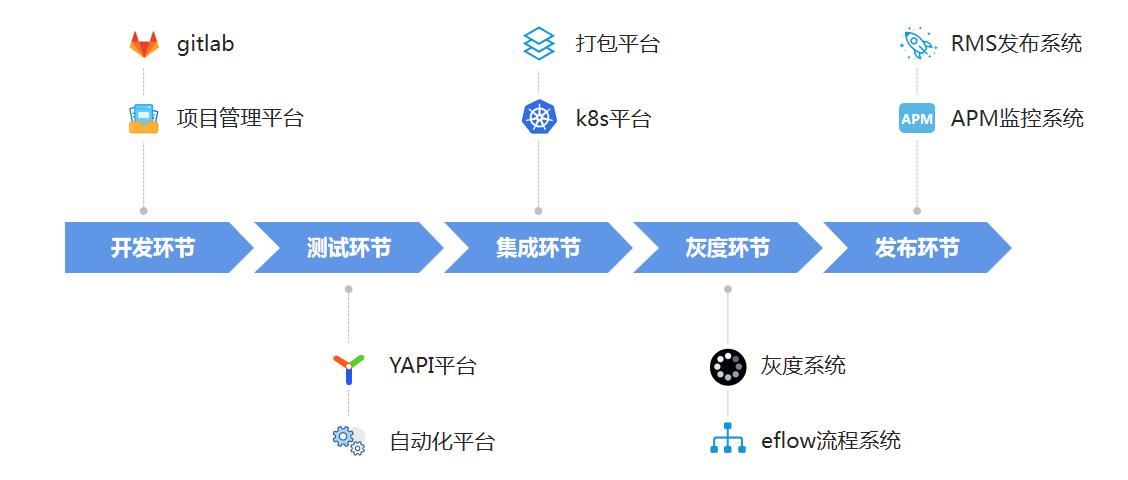
通过建立以上标准化、可视化的交付流水线并搭建相应的协作平台,我们主要解决了如下几类问题:
- 质量标准不透明,无法及时反馈
从代码提交到最终的发布上线,会经历多个环节,每个环节又存在多项测试验收等动作,每个业务每个环节的质量标准也不尽相同。原先结果的收集汇总和通知反馈都是对应的需求跟进人或版本负责人进行人工收集和反馈,存在信息不透明、反馈不及时的问题。现在通过结合流程的质量阀建立相应的质量标准,并结合大盘的可视化展示和及时通知,有效的解决了沟通层面的低效以及信息传递过程中的损耗,也能较直观的看到版本、需求、分支等维度的进展,方便PM及相关负责人及时跟进并解决相关问题,从而促进了整体交付效率的提升。
- 环节流转不够紧密,需要人工参与
对于整个交付流程来说,只要有人工参与的地方就势必会存在效率方面的损耗。我们通过结合上面提到的质量标准,通过系统自动计算当前的质量数据来判定是否可以进行环节的流转,比如是否达到提测条件、是否达到合入集成分支条件,从而尽可能的排除人为因素导致的流程流转中的耗时,做到更加的准确和及时,大大减少了过程等待。
- 交付过程不顺畅,涉及多个站点
我们通过打通交付过程中涉及到的其他外部系统,使得原本需要去不同平台操作的动作直接在持续交付平台上就可以完成,无需在多个系统之间频繁切换,形成了一站式体验,使得整个交付过程中的操作体验更加的顺畅
六、结语
以上就是我们在持续交付流水线设计方面所进行的一些改进和实践。当然,这套系统目前还有很多值得改进和优化的地方,对应的实践方案也不一定适合所有的公司,这里主要是分享一下我们在建设过程所中碰到的问题、痛点以及相应的改进思路,希望能给想建设或正在着手建设持续交付平台的朋友们提供一些有益的参考。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号