Mysql查询优化器之关于JOIN的优化
连接查询应该是比较常用的查询方式,连接查询大致分为:内连接、外连接(左连接和右连接)、自然连接
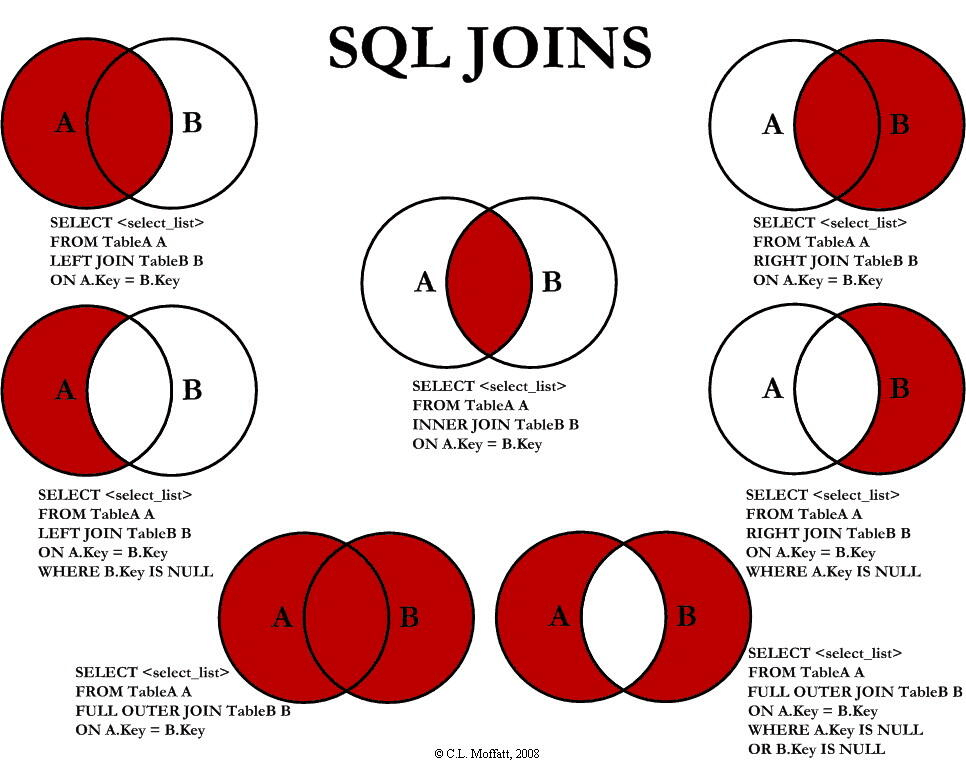
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
内连接
以下三种写法都是内连接:
mysql> select * from t1 join t2 on t1.a = t2.a; mysql> select * from t1 inner join t2 on t1.a = t2.a; mysql> select * from t1 cross join t2 on t1.a = t2.a;
图解:

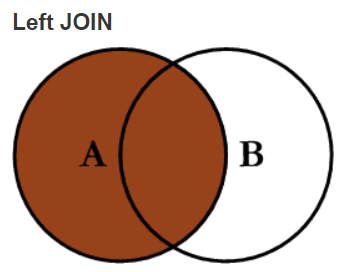
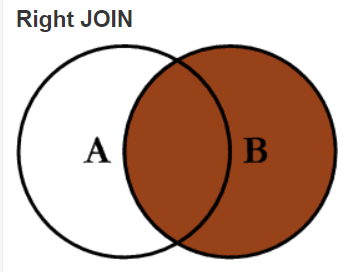
左连接、右连接
左连接:
mysql> select * from t1 left join t2 on t1.a = t2.a;
右连接:
mysql> select * from t1 right join t2 on t1.a = t2.a;
连接的原理
不管是内连接还是左右连接,都需要一个驱动表和一个被驱动表,对于内连接来说,选取哪个表为驱动表都没关系,而外连接的驱动表是固定的,也就是说左连接的驱动表就是左边的那个表,右连接的驱动表就是右边的那个表。
连接的大致原理是:
1. 选取驱动表,使用与驱动表相关的过滤条件,选取代价最低的访问形式来执行对驱动表的单表查询。
2. 对上一步骤中查询驱动表得到的结果集中每一条记录,都分别到被驱动表中查找匹配的记录。
对应伪代码就是:
for each row in t1 { //此处表示遍历满足对t1单表查询结果集中的每一条记录
for each row in t2 { //此处表示对于某条t1表的记录来说,遍历满足对t2单表查询结果集中的每一条记录
// 判断是否符合join条件
}
}
嵌套循环连接(Nested-Loop Join)
上面的过程就像是一个嵌套的循环,所以这种驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数的连接执行方式称之为嵌套循环连接(Nested-Loop Join),这是最简单,也是最笨拙的一种连接查询算法;
比如对于下面这个sql:
select * from t1 join t2 on t1.a = t2.a where t1.b in (1,2);
先会执行:
mysql> select * from t1 where t1.b in (1,2); +---+------+------+------+------+ | a | b | c | d | e | +---+------+------+------+------+ | 1 | 1 | 1 | 1 | a | | 2 | 2 | 2 | 2 | b | | 5 | 2 | 3 | 5 | e | +---+------+------+------+------+ 3 rows in set (0.00 sec)
得到三条记录。
然后分别执行:
mysql> select * from t2 where t2.a = 1; mysql> select * from t2 where t2.a = 2; mysql> select * from t2 where t2.a = 5;
所以实际上对于上面的步骤,实际上都是针对单表的查询,所以都可以使用索引来帮助查询。
基于块的嵌套循环连接(Block Nested-Loop Join)
扫描一个表的过程其实是先把这个表从磁盘上加载到内存中,然后从内存中比较匹配条件是否满足。现实生活中的表可不像t1、t2这种只有几条记录,可能会有成千上万的数据。内存里可能并不能完全存放的下表中所有的记录,所以在扫描表前边记录的时候后边的记录可能还在磁盘上,等扫描到后边记录的时候可能内存不足,所以需要把前边的记录从内存中释放掉。我们前边又说过,采用嵌套循环连接算法的两表连接过程中,被驱动表可是要被访问好多次的,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读好几次这个表,这个I/O代价就非常大了,所以我们得想办法:尽量减少访问被驱动表的次数。
当被驱动表中的数据非常多时,每次访问被驱动表,被驱动表的记录会被加载到内存中,在内存中的每一条记录只会和驱动表结果集的一条记录做匹配,之后就会被从内存中清除掉。然后再从驱动表结果集中拿出另一条记录,再一次把被驱动表的记录加载到内存中一遍,周而复始,驱动表结果集中有多少条记录,就得把被驱动表从磁盘上加载到内存中多少次。所以我们可不可以在把被驱动表的记录加载到内存的时候,一次性和多条驱动表中的记录做匹配,这样就可以大大减少重复从磁盘上加载被驱动表的代价了。
join buffer
Mysql中有一个叫做join buffer的概念,join buffer就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和join buffer中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价。
最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。这种加入了join buffer的嵌套循环连接算法称之为基于块的嵌套连接(Block Nested-Loop Join)算法。
这个join buffer的大小是可以通过启动参数或者系统变量join_buffer_size进行配置,默认大小为262144字节(也就是256KB),最小可以设置为128字节。当然,对于优化被驱动表的查询来说,最好是为被驱动表加上效率高的索引,如果实在不能使用索引,并且自己的机器的内存也比较大可以尝试调大join_buffer_size的值来对连接查询进行优化。
另外需要注意的是,驱动表的记录并不是所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样可以在join buffer中放置更多的记录。
外连接消除
内连接的驱动表和被驱动表的位置可以相互转换,而左连接和右连接的驱动表和被驱动表是固定的。这就导致内连接可能通过优化表的连接顺序来降低整体的查询成本,而外连接却无法优化表的连接顺序。
外连接和内连接的本质区别就是:对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL值填充;而内连接的驱动表的记录如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录会被舍弃
案例:下图中可以发现驱动表和被驱动表发生了变化,实际上加上了is not null之后被优化成了内连接,就可以利用查询优化器选择最优的连接顺序了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号