

Spark基础:(七)Spark Streaming入门
介绍
1、是spark core的扩展,针对实时数据流处理,具有可扩展、高吞吐量、容错.
数据可以是来自于kafka,flume,tcpsocket,使用高级函数(map reduce filter ,join , windows),
处理的数据可以推送到database,hdfs,针对数据流处理可以应用到机器学习和图计算中。
内部,spark接受实时数据流,分成batch(分批次)进行处理,最终在每个batch终产生结果stream.
2.discretized stream or DStream,
离散流,表示的是连续的数据流。
通过kafka、flume等输入数据流产生,也可以通过对其他DStream进行高阶变换产生。
在内部,DStream是表现为RDD序列。
体验
依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.0</version>
</dependency>scalaDeno
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object SparkStreamingDemo {
def main(args: Array[String]): Unit = {
//local[n] n > 1
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//创建Spark流上下文,批次时长是1s
val ssc = new StreamingContext(conf, Seconds(1))
//创建socket文本流
val lines = ssc.socketTextStream("localhost", 9999)
//压扁
val words = lines.flatMap(_.split(" "))
//变换成对偶
val pairs = words.map((_,1));
val count = pairs.reduceByKey(_+_) ;
count.print()
//启动
ssc.start()
//等待结束
ssc.awaitTermination()
}
}1.启动nc服务器
[win7]
cmd>nc -lL -p 9999
2.启动spark Streaming程序
3.在nc的命令行输入单词.
hello world
4.观察spark计算结果。
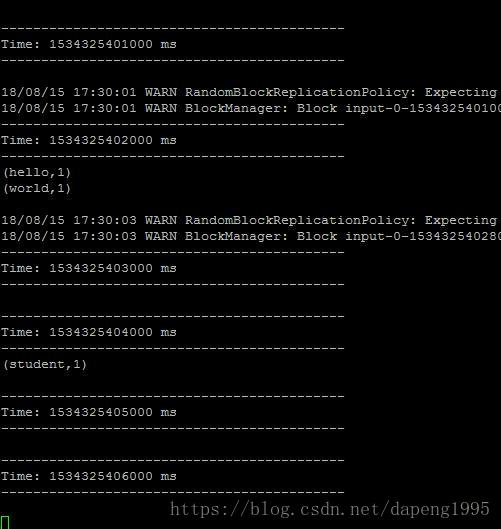
同样的丢到
希望在知识中书写人生的代码

