

垃圾回收机制及循环引用
原文链接:
python的垃圾回收机制及循环引用 - libochou - 博客园 https://www.cnblogs.com/libochou/p/10150048.html
[转]java垃圾回收之循环引用 - kkmm - 博客园 https://www.cnblogs.com/lihaozy/archive/2013/06/08/3125974.html
3. Recycling techniques — Memory Management Reference 4.0 documentation
https://www.memorymanagement.org/mmref/recycle.html
python的垃圾回收机制及循环引用
引用计数
Python语言默认采用的垃圾收集机制是『引用计数法 Reference Counting』,该算法最早George E. Collins在1960的时候首次提出,50年后的今天,该算法依然被很多编程语言使用,『引用计数法』的原理是:每个对象维护一个ob_ref字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数ob_ref加1,每当该对象的引用失效时计数ob_ref减1,一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。它的缺点是需要额外的空间维护引用计数,这个问题是其次的,不过最主要的问题是它不能解决对象的“循环引用”,因此,也有很多语言比如Java并没有采用该算法做来垃圾的收集机制。
什么是循环引用?A和B相互引用而再没有外部引用A与B中的任何一个,它们的引用计数虽然都为1,但显然应该被回收,例子:
a= { } #对象A的引用计数为 1
del语句后,A、B对象已经没有任何引用指向这两个对象,但是这两个对象各包含一个对方对象的引用,虽然最后两个对象都无法通过其它变量来引用这两个对象了,这对GC来说就是两个非活动对象或者说是垃圾对象,但是他们的引用计数并没有减少到零。因此如果是使用引用计数法来管理这两对象的话,他们并不会被回收,它会一直驻留在内存中,就会造成了内存泄漏(内存空间在使用完毕后未释放)。为了解决对象的循环引用问题,Python引入了标记-清除和分代回收两种GC机制。标记清除
『标记清除(Mark—Sweep)』算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,第二阶段是把那些没有标记的对象『非活动对象』进行回收。那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
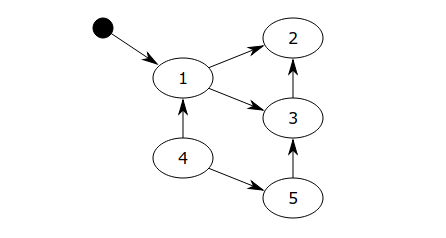
在上图中,我们把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象。
参考:
- http://www.memorymanagement.org/mmref/recycle.html#tracing-collectors
- 《垃圾回收的算法与实现》
- 《Python源码剖析》
java垃圾回收之循环引用
工作原理:为每个内存对象维护一个引用计数。
当有新的引用指向某对象时就将该对象的引用计数加一,当指向该对象的引用被销毁时将该计数减一,当计数归零时,就回收该对象所占用的内存资源。
缺陷:在每次内存对象被引用或引用被销毁的时候都必须修改引用计数,这类操作被称为footprint。引用计数的footprint是很高的。这使得程序整体的性能受到比较大的影响。因此多数现代的程序语言都不适用引用计数作为垃圾收集的实现算法。
另外,引用计数还有一个致命的缺陷,当程中出现序循环引用时,引用计数算法无法检测出来,被循环引用的内存对象就成了无法回收的内存。从而引起内存泄露。
举例说明就是:
class A{ public B b; } class B{ public A a; } public class Main{ public static void main(String[] args){ A a = new A(); B b = new B(); a.b=b; b.a=a; } }
在函数的结尾,a和b的计数均为2
先撤销a,然后a的计数为1,在等待b.a对a的引用的撤销,也就是在等待b的撤销
对于b来讲,也是同理
两个对象都在等待对方撤销,所有这两个资源均不能释放
垃圾回收技术(Recycling techniques)
自动内存管理器有很多方法可以确定不再需要哪些内存。基本上,垃圾回收依赖于确定哪些块未被任何程序变量指向。下面简要介绍了一些用于执行此操作的技术,但是存在许多潜在的陷阱,并且可能有许多改进。这些技术通常可以结合使用。
There are many ways for automatic memory managers to determine what memory is no longer required. In the main, garbage collection relies on determining which blocks are not pointed to by any program variables. Some of the techniques for doing this are described briefly below, but there are many potential pitfalls, and many possible refinements. These techniques can often be used in combination.
1.扫描收集器(Tracing collectors)
Automatic memory managers that follow pointers to determine which blocks of memory are reachable from program variables (known as the root set) are known as tracing collectors. The classic example is the mark-sweep collector.
- 标记-清除(Mark-sweep collection)
此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
In a mark-sweep collection, the collector first examines the program variables; any blocks of memory pointed to are added to a list of blocks to be examined. For each block on that list, it sets a flag (the mark) on the block to show that it is still required, and also that it has been processed. It also adds to the list any blocks pointed to by that block that have not yet been marked. In this way, all blocks that can be reached by the program are marked.
In the second phase, the collector sweeps all allocated memory, searching for blocks that have not been marked. If it finds any, it returns them to the allocator for reuse.

Five memory blocks, three of which are reachable from program variables.
In the diagram above, block 1 is directly accessible from a program variable, and blocks 2 and 3 are indirectly accessible. Blocks 4 and 5 cannot be reached by the program. The first step would mark block 1, and remember blocks 2 and 3 for later processing. The second step would mark block 2. The third step would mark block 3, but wouldn’t remember block 2 as it is already marked. The sweep phase would ignore blocks 1, 2, and 3 because they are marked, but would recycle blocks 4 and 5.
The two drawbacks of simple mark-sweep collection are:
---it must scan the entire memory in use before any memory can be freed;
---it must run to completion or, if interrupted, start again from scratch.
If a system requires real-time or interactive response, then simple mark-sweep collection may be unsuitable as it stands, but many more sophisticated garbage collection algorithms are derived from this technique.
- 复制(Copying collection)
After many memory blocks have been allocated and recycled, there are two problems that typically occur:
1、the memory in use is widely scattered in memory, causing poor performance in the memory caches or virtual memory systems of most modern computers (known as poor locality of reference);
2、it becomes difficult to allocate large blocks because free memory is divided into small pieces, separated by blocks in use (known as external fragmentation).
One technique that can solve both these problems is copying garbage collection. A copying garbage collector may move allocated blocks around in memory and adjust any references to them to point to the new location. This is a very powerful technique and can be combined with many other types of garbage collection, such as mark-sweep collection.
The disadvantages of copying collection are:
---it is difficult to combine with incremental garbage collection (see below) because all references must be adjusted to remain consistent;
---it is difficult to combine with conservative garbage collection (see below) because references cannot be confidently adjusted;
---extra storage is required while both new and old copies of an object exist;
---copying data takes extra time (proportional to the amount of live data).
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。次算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现"碎片"问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
- 标记-整理(Mark-Compact)
此算法结合了"标记-清除"和"复制"两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象"压缩"到堆的其中一块,按顺序排放。此算法避免了"标记-清除"的碎片问题,同时也避免了"复制"算法的空间问题。
- 增量收集(Incremental collection)
实施垃圾回收算法,即:在应用进行的同时进行垃圾回收。不知道什么原因JDK5.0中的收集器没有使用这种算法的。
Older garbage collection algorithms relied on being able to start collection and continue working until the collection was complete, without interruption. This makes many interactive systems pause during collection, and makes the presence of garbage collection obtrusive.
Fortunately, there are modern techniques (known as incremental garbage collection) to allow garbage collection to be performed in a series of small steps while the program is never stopped for long. In this context, the program that uses and modifies the blocks is sometimes known as the mutator. While the collector is trying to determine which blocks of memory are reachable by the mutator, the mutator is busily allocating new blocks, modifying old blocks, and changing the set of blocks it is actually looking at.
Incremental collection is usually achieved with either the cooperation of the memory hardware or the mutator; this ensures that, whenever memory in crucial locations is accessed, a small amount of necessary bookkeeping is performed to keep the collector’s data structures correct.
- 分代(Generational Collecting)
基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青代、年老代、持久代,对不同生命周期的对象使用不同的算法(上述方式中的一个)进行回收。现在的垃圾回收器(从J2SE1.2开始)都是使用此算法的。
-
保守式GC(Conservative garbage collection)
Although garbage collection was first invented in 1958, many languages have been designed and implemented without the possibility of garbage collection in mind. It is usually difficult to add normal garbage collection to such a system, but there is a technique, known as conservative garbage collection, that can be used.
The usual problem with such a language is that it doesn’t provide the collector with information about the data types, and the collector cannot therefore determine what is a pointer and what isn’t. A conservative collector assumes that anything might be a pointer. It regards any data value that looks like a pointer to or into a block of allocated memory as preventing the recycling of that block.
Note that, because the collector does not know for certain which memory locations contain pointers, it cannot readily be combined with copying garbage collection. Copying collection needs to know where pointers are in order to update them when blocks are moved.
You might think that conservative garbage collection could easily perform quite poorly, leaving a lot of garbage uncollected. In practice, it does quite well, and there are refinements that improve matters further.
2.引用计数(Reference counts)
A reference count is a count of how many references (that is, pointers) there are to a particular memory block from other blocks. It is used as the basis for some automatic recycling techniques that do not rely on tracing.
2.1. Simple reference counting
In a simple reference counting system, a reference count is kept for each object. This count is incremented for each new reference, and is decremented if a reference is overwritten, or if the referring object is recycled. If a reference count falls to zero, then the object is no longer required and can be recycled.
Reference counting is frequently chosen as an automatic memory management strategy because it seems simple to implement using manual memory management primitives. However, it is hard to implement efficiently because of the cost of updating the counts. It is also hard to implement reliably, because the standard technique cannot reclaim objects connected in a loop. In many cases, it is an inappropriate solution, and it would be preferable to use tracing garbage collection instead.
Reference counting is most useful in situations where it can be guaranteed that there will be no loops and where modifications to the reference structure are comparatively infrequent. These circumstances can occur in some types of database structure and some file systems. Reference counting may also be useful if it is important that objects are recycled promptly, such as in systems with tight memory constraints.
2.2. Deferred reference counting
The performance of reference counting can be improved if not all references are taken into account. In one important technique, known as deferred reference counting, only references from other objects are counted, and references from program variables are ignored. Since most of the references to the object are likely to be from local variables, this can substantially reduce the overhead of keeping the counts up to date. An object cannot be reclaimed as soon as its count has dropped to zero, because there might still be a reference to it from a program variable. Instead, the program variables (including the control stack) are periodically scanned, and any objects which are not referenced from there and which have zero count are reclaimed.
Deferred reference counting cannot normally be used unless it is directly supported by the compiler. It’s more common for modern compilers to support tracing garbage collectors instead, because they can reclaim loops. Deferred reference counting may still be useful for its promptness—but that is limited by the frequency of scanning the program variables.
2.3. One-bit reference counting
Another variation on reference counting, known as the one-bit reference count, uses a single bit flag to indicate whether each object has either “one” or “many” references. If a reference to an object with “one” reference is removed, then the object can be recycled. If an object has “many” references, then removing references does not change this, and that object will never be recycled. It is possible to store the flag as part of the pointer to the object, so no additional space is required in each object to store the count. One-bit reference counting is effective in practice because most actual objects have a reference count of one.
2.4. Weighted reference counting
Reference counting is often used for tracking inter-process references for distributed garbage collection. This fails to collect objects in separate processes if they have looped references, but tracing collectors are usually too inefficient as inter-process tracing entails much communication between processes. Within a process, tracing collectors are often used for local recycling of memory.
Many distributed collectors use a technique called weighted reference counting, which reduces the level of communication even further. Each time a reference is copied, the weight of the reference is shared between the new and the old copies. Since this operation doesn’t change the total weight of all references, it doesn’t require any communication with the object. Communication is only required when references are deleted.
参考链接:
3. Recycling techniques — Memory Management Reference 4.0 documentation
https://www.memorymanagement.org/mmref/recycle.html#recycling-techniques

