
Linux内核 hlist_head/hlist_node结构解析
linux内核里面的双向循环链表和哈希链表有什么不同呢?1、双向循环链表是循环的,哈希链表不是循环的 2、双向循环链表不区分头结点和数据结点,都用list_head表示,而哈希链表区分头结点(hlist_head)和数据结点(hlist_node)。与哈希链表有关的两个数据结构如下:
struct hlist_head { struct hlist_node *first; //指向每一个hash桶的第一个结点的指针 }; struct hlist_node { struct hlist_node *next; //指向下一个结点的指针 struct hlist_node **pprev; //指向上一个结点的next指针的指针 };
int fz_divisor;
表示散列表fz_hash的容量,以及散列表桶的数目。
这个数据结构与一般的hash-list数据结构定义有以下的区别:
1) 首先,hash的头节点仅存放一个指针,也就是first指针,指向的是list的头结点,没有tail指针也就是指向list尾节点的指针,这样的考虑是为了节省空间——尤其在hash bucket很大的情况下可以节省一半的指针空间.
2) list的节点有两个指针,但是需要注意的是pprev是指针的指针,它指向的是前一个节点的next指针;其中首元素的pprev指向链表头的fist字段,末元素的next为NULL. (见下图).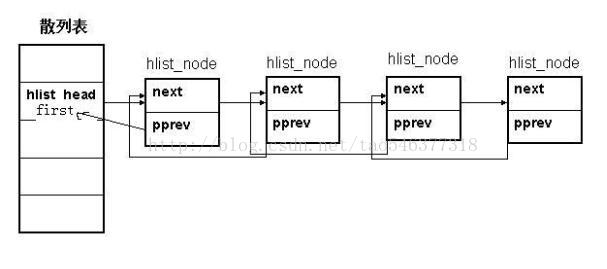
1、哈希链表为什么要区分头结点和数据结点?
头结点和数据结点如果都使用list_head的话,那岂不是更容易实现。内核list.h中描述得很明白:
/* * Double linked lists with a single pointer list head. * Mostly useful for hash tables where the two pointer list head is * too wasteful. * You lose the ability to access the tail in O(1). */
意思是说这种双向链表的头结点只有一个指针成员(即struct hlist_node *first),它主要使用在哈希表中。因为哈希表会有很多表项,每个表项如果使用list_head这样含有两个指针成员的数据结构的话,会造成内存空间的浪费。所以,为了尽可能的减少内存空间的浪费,就要使数据结构变得稍微复杂一些,鱼和熊掌不可兼得啊。
2、hlist_node的pprev成员为什么是struct hlist_node **类型的?
如果hlist_node的定义是下面这样的话
struct hlist_node { struct hlist_node *next; struct hlist_node *prev; };
第一个数据结点的prev成员应该指向头结点,但是因为prev成员指向的是hlist_node的数据类型的指针,而头结点的数据类型是hlist_head,所以无法实现。为了解决这样的问题,才有了下面的hlist_node的定义
struct hlist_node { struct hlist_node *next; struct hlist_node **pprev; };
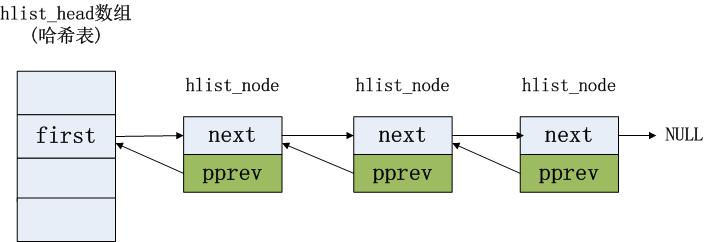
在上图中,第一个数据结点的pprev成员(数据类型struct hlist_node **)指向头结点的first成员(数据类型struct hlist_node *),第二个数据结点的pprev成员(数据类型struct hlist_node **)指向第一个数据结点的next成员(数据类型struct hlist_node *),从而对于第一个数据结点的操作和非第一个数据结点的操作就没有区别了,都统一起来了。这样就不用对第一个数据结点进行特殊处理了,为编写代码带来了极大的好处,这种设计有点小艺术。
其他的hlist的初始化、插入、删除、遍历请自行参阅list.h源文件,源文件是最好的老师。
现在疑问来了:为什么pprev不是prev也就是一个指针,用于简单的指向list的前一个指针呢?这样即使对于first而言,它可以将prev指针指向list的尾结点.
主要是基于以下几个考虑:
1) hash-list中的list一般元素不多(如果太多了一般是设计出现了问题),即使遍历也不需要太大的代价,同时需要得到尾结点的需求也不多.
2) 如果对于一般节点而言,prev指向的是前一个指针,而对于first也就是hash的第一个元素而言prev指向的是list的尾结点,那么在删除一个元素的时候还需要判断该节点是不是first节点进行处理.而在hlist提供的删除节点的API中,并没有带上hlist_head这个参数,因此做这个判断存在难度.
3) 以上两点说明了为什么不使用prev,现在来说明为什么需要的是pprev,也就是一个指向指针的指针来保存前一个节点的next指针--因为这样做即使在删除的节点是first节点时也可以通过*pprev = next;直接修改指针的指向.来看删除一个节点和修改list头结点的两个API:
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h) { struct hlist_node *first = h->first; n->next = first; if (first) first->pprev = &n->next; h->first = n; n->pprev = &h->first; //此时n是hash的first指针,因此它的pprev指向的是hash的first指针的地址 } static inline void __hlist_del(struct hlist_node *n) { struct hlist_node *next = n->next; struct hlist_node **pprev = n->pprev; *pprev = next; // pprev指向的是前一个节点的next指针,而当该节点是first节点时指向自己,因此两种情况下不论该节点是一般的节点还是头结点都可以通过这个操作删除掉所需删除的节点 if (next) next->pprev = pprev; }
原文链接:linux内核list分析三:哈希链表 | 周子江 https://zhouzijiang.github.io/2015/11/08/linux%E5%86%85%E6%A0%B8list%E5%88%86%E6%9E%90%E4%B8%89-%E5%93%88%E5%B8%8C%E9%93%BE%E8%A1%A8/
Linux内核 hlist_head/hlist_node结构解析 - tao546377318的博客 - CSDN博客 https://blog.csdn.net/tao546377318/article/details/60772209

