Kaggle学习笔记——房屋价格预测
Kaggle的房价数据集使用的是Ames Housing dataset,是美国爱荷华州的艾姆斯镇2006-2010年的房价
1.特征探索和分析
1.了解特征的含义
首先使用Python的pandas加载一下训练样本和测试样本,数据的格式是csv格式的,且第一列是特征的名称

查看一下特征的维度
import pandas as pd
# 加载数据
train_data = pd.read_csv("./raw_data/train.csv")
# 去掉id和售价,只看特征
data: DataFrame = train_data.drop(columns=["Id", "SalePrice"])
print(data.shape)
输出如下,除去Id和SalePrice,总共有79维的特征
(1460, 79)
翻译一下给的房屋数据的特征,这里定义了一个dict,方便理解每个特征的含义
dict = {
"MSSubClass": "参与销售住宅的类型:有年代新旧等信息",
"MSZoning": "房屋类型:农用,商用等",
"LotFrontage": "距离街道的距离",
"LotArea": "房屋的面积",
"Street": "通向房屋的Street是用什么铺的",
"Alley": "通向房屋的Alley是用什么铺的",
"LotShape": "房屋的户型,规整程度",
"LandContour": "房屋的平坦程度",
"Utilities": "设施,通不通水电气",
"LotConfig": "死路,处于三岔口等",
"LandSlope": "坡度",
"Neighborhood": "邻居",
"Condition1": "",
"Condition2": "",
"BldgType": "住宅类型,住的家庭数,是否别墅等",
"HouseStyle": "住宅类型,隔断等",
"OverallQual": "房屋的质量",
"OverallCond": "房屋位置的质量",
"YearBuilt": "建造的时间",
"YearRemodAdd": "改造的时间",
"RoofStyle": "屋顶的类型",
"RoofMatl": "屋顶的材料",
"Exterior1st": "外观覆盖的材质",
"Exterior2nd": "如果超过一种,则有第二种材质",
"MasVnrType": "表层砌体类型",
"MasVnrArea": "表层砌体面积",
"ExterQual": "外观材料质量",
"ExterCond": "外观材料情况",
"Foundation": "地基类型",
"BsmtQual": "地下室质量",
"BsmtCond": "地下室的基本情况",
"BsmtExposure": "地下室采光",
"BsmtFinType1": "地下室的完成情况比例",
"BsmtFinSF1": "地下室的完成面积",
"BsmtFinType2": "如果有多个地下室的话",
"BsmtFinSF2": "如果有多个地下室的话",
"BsmtUnfSF": "未完成的地下室面积",
"TotalBsmtSF": "地下室面积",
"Heating": "供暖类型",
"HeatingQC": "供暖质量",
"CentralAir": "是否有中央空调",
"Electrical": "电气系统",
"_1stFlrSF": "1楼面积",
"_2ndFlrSF": "2楼面积",
"LowQualFinSF": "低质量完成的面积(楼梯占用的面积)",
"GrLivArea": "地面以上居住面积",
"BsmtFullBath": "地下室都是洗手间",
"BsmtHalfBath": "地下室一半是洗手间",
"FullBath": "洗手间都在一层以上",
"HalfBath": "一半洗手间在一层以上",
"BedroomAbvGr": "卧室都在一层以上",
"KitchenAbvGr": "厨房在一层以上",
"KitchenQual": "厨房质量",
"TotRmsAbvGrd": "所有房间都在一层以上",
"Functional": "房屋的功能性等级",
"Fireplaces": "壁炉位置",
"FireplaceQu": "壁炉质量",
"GarageType": "车库类型",
"GarageYrBlt": "车库建造时间",
"GarageFinish": "车库的室内装修",
"GarageCars": "车库的汽车容量",
"GarageArea": "车库面积",
"GarageQual": "车库质量",
"GarageCond": "车库情况",
"PavedDrive": "铺路的材料",
"WoodDeckSF": "木地板面积",
"OpenPorchSF": "露天门廊面积",
"EnclosedPorch": "独立门廊面积",
"_3SsnPorch": "three season门廊面积",
"ScreenPorch": "纱门门廊面积",
"PoolArea": "游泳池面积",
"PoolQC": "游泳池质量",
"Fence": "栅栏质量",
"MiscFeature": "上面不包含其他功能",
"MiscVal": "上面不包含其他功能的价格",
"MoSold": "月销量",
"YrSold": "年销量",
"SaleType": "销售方式",
"SaleCondition": "销售情况"
}
2.查看特征是离散特征还是连续特征
# 查看特征是离散特征还是连续特征 train_data.info()
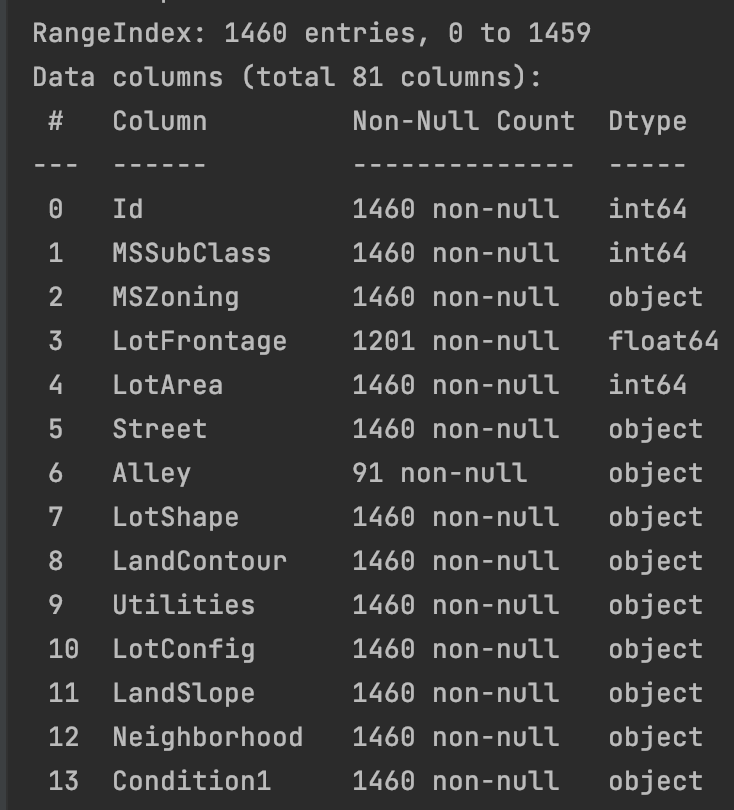
3.查看特征的统计指标
# 查看特征的统计指标
pd.set_option('expand_frame_repr', False) # 不换行
pd.set_option('display.max_columns', None) # 显示所有列
train_data_statistic = train_data.describe()
print(train_data_statistic)
读取了数据之后先describe一下,查看均值,样本标准偏差,最小值和最大值等,参考:Python Pandas 常用统计数据方法汇总(求和,计数,均值,中位数,分位数,最大/最小,方差,标准差等)
其中count(非空值数)、unique(去重后的个数)、top(频数最高者)、freq(最高频数)
可以发现MasVnrType这个特征出现最多的是None,有864/1460都是None字符串,这个特征在后面需要进行删除处理
Id MSSubClass MSZoning LotFrontage LotArea Street Alley LotShape LandContour Utilities LotConfig LandSlope Neighborhood Condition1 Condition2 BldgType HouseStyle OverallQual OverallCond YearBuilt YearRemodAdd RoofStyle RoofMatl Exterior1st Exterior2nd MasVnrType MasVnrArea ExterQual ExterCond Foundation BsmtQual BsmtCond BsmtExposure BsmtFinType1 BsmtFinSF1 BsmtFinType2 BsmtFinSF2 BsmtUnfSF TotalBsmtSF Heating HeatingQC CentralAir Electrical 1stFlrSF 2ndFlrSF LowQualFinSF GrLivArea BsmtFullBath BsmtHalfBath FullBath HalfBath BedroomAbvGr KitchenAbvGr KitchenQual TotRmsAbvGrd Functional Fireplaces FireplaceQu GarageType GarageYrBlt GarageFinish GarageCars GarageArea GarageQual GarageCond PavedDrive WoodDeckSF OpenPorchSF EnclosedPorch 3SsnPorch ScreenPorch PoolArea PoolQC Fence MiscFeature MiscVal MoSold YrSold SaleType SaleCondition SalePrice count 1460.000000 1460.000000 1460 1201.000000 1460.000000 1460 91 1460 1460 1460 1460 1460 1460 1460 1460 1460 1460 1460.000000 1460.000000 1460.000000 1460.000000 1460 1460 1460 1460 1452 1452.000000 1460 1460 1460 1423 1423 1422 1423 1460.000000 1422 1460.000000 1460.000000 1460.000000 1460 1460 1460 1459 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460 1460.000000 1460 1460.000000 770 1379 1379.000000 1379 1460.000000 1460.000000 1379 1379 1460 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 7 281 54 1460.000000 1460.000000 1460.000000 1460 1460 1460.000000 unique NaN NaN 5 NaN NaN 2 2 4 4 2 5 3 25 9 8 5 8 NaN NaN NaN NaN 6 8 15 16 4 NaN 4 5 6 4 4 4 6 NaN 6 NaN NaN NaN 6 5 2 5 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 4 NaN 7 NaN 5 6 NaN 3 NaN NaN 5 5 3 NaN NaN NaN NaN NaN NaN 3 4 4 NaN NaN NaN 9 6 NaN top NaN NaN RL NaN NaN Pave Grvl Reg Lvl AllPub Inside Gtl NAmes Norm Norm 1Fam 1Story NaN NaN NaN NaN Gable CompShg VinylSd VinylSd None NaN TA TA PConc TA TA No Unf NaN Unf NaN NaN NaN GasA Ex Y SBrkr NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN TA NaN Typ NaN Gd Attchd NaN Unf NaN NaN TA TA Y NaN NaN NaN NaN NaN NaN Gd MnPrv Shed NaN NaN NaN WD Normal NaN freq NaN NaN 1151 NaN NaN 1454 50 925 1311 1459 1052 1382 225 1260 1445 1220 726 NaN NaN NaN NaN 1141 1434 515 504 864 NaN 906 1282 647 649 1311 953 430 NaN 1256 NaN NaN NaN 1428 741 1365 1334 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 735 NaN 1360 NaN 380 870 NaN 605 NaN NaN 1311 1326 1340 NaN NaN NaN NaN NaN NaN 3 157 49 NaN NaN NaN 1267 1198 NaN mean 730.500000 56.897260 NaN 70.049958 10516.828082 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 6.099315 5.575342 1971.267808 1984.865753 NaN NaN NaN NaN NaN 103.685262 NaN NaN NaN NaN NaN NaN NaN 443.639726 NaN 46.549315 567.240411 1057.429452 NaN NaN NaN NaN 1162.626712 346.992466 5.844521 1515.463699 0.425342 0.057534 1.565068 0.382877 2.866438 1.046575 NaN 6.517808 NaN 0.613014 NaN NaN 1978.506164 NaN 1.767123 472.980137 NaN NaN NaN 94.244521 46.660274 21.954110 3.409589 15.060959 2.758904 NaN NaN NaN 43.489041 6.321918 2007.815753 NaN NaN 180921.195890 std 421.610009 42.300571 NaN 24.284752 9981.264932 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 1.382997 1.112799 30.202904 20.645407 NaN NaN NaN NaN NaN 181.066207 NaN NaN NaN NaN NaN NaN NaN 456.098091 NaN 161.319273 441.866955 438.705324 NaN NaN NaN NaN 386.587738 436.528436 48.623081 525.480383 0.518911 0.238753 0.550916 0.502885 0.815778 0.220338 NaN 1.625393 NaN 0.644666 NaN NaN 24.689725 NaN 0.747315 213.804841 NaN NaN NaN 125.338794 66.256028 61.119149 29.317331 55.757415 40.177307 NaN NaN NaN 496.123024 2.703626 1.328095 NaN NaN 79442.502883 min 1.000000 20.000000 NaN 21.000000 1300.000000 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 1.000000 1.000000 1872.000000 1950.000000 NaN NaN NaN NaN NaN 0.000000 NaN NaN NaN NaN NaN NaN NaN 0.000000 NaN 0.000000 0.000000 0.000000 NaN NaN NaN NaN 334.000000 0.000000 0.000000 334.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 NaN 2.000000 NaN 0.000000 NaN NaN 1900.000000 NaN 0.000000 0.000000 NaN NaN NaN 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 NaN NaN NaN 0.000000 1.000000 2006.000000 NaN NaN 34900.000000 25% 365.750000 20.000000 NaN 59.000000 7553.500000 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 5.000000 5.000000 1954.000000 1967.000000 NaN NaN NaN NaN NaN 0.000000 NaN NaN NaN NaN NaN NaN NaN 0.000000 NaN 0.000000 223.000000 795.750000 NaN NaN NaN NaN 882.000000 0.000000 0.000000 1129.500000 0.000000 0.000000 1.000000 0.000000 2.000000 1.000000 NaN 5.000000 NaN 0.000000 NaN NaN 1961.000000 NaN 1.000000 334.500000 NaN NaN NaN 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 NaN NaN NaN 0.000000 5.000000 2007.000000 NaN NaN 129975.000000 50% 730.500000 50.000000 NaN 69.000000 9478.500000 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 6.000000 5.000000 1973.000000 1994.000000 NaN NaN NaN NaN NaN 0.000000 NaN NaN NaN NaN NaN NaN NaN 383.500000 NaN 0.000000 477.500000 991.500000 NaN NaN NaN NaN 1087.000000 0.000000 0.000000 1464.000000 0.000000 0.000000 2.000000 0.000000 3.000000 1.000000 NaN 6.000000 NaN 1.000000 NaN NaN 1980.000000 NaN 2.000000 480.000000 NaN NaN NaN 0.000000 25.000000 0.000000 0.000000 0.000000 0.000000 NaN NaN NaN 0.000000 6.000000 2008.000000 NaN NaN 163000.000000 75% 1095.250000 70.000000 NaN 80.000000 11601.500000 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 7.000000 6.000000 2000.000000 2004.000000 NaN NaN NaN NaN NaN 166.000000 NaN NaN NaN NaN NaN NaN NaN 712.250000 NaN 0.000000 808.000000 1298.250000 NaN NaN NaN NaN 1391.250000 728.000000 0.000000 1776.750000 1.000000 0.000000 2.000000 1.000000 3.000000 1.000000 NaN 7.000000 NaN 1.000000 NaN NaN 2002.000000 NaN 2.000000 576.000000 NaN NaN NaN 168.000000 68.000000 0.000000 0.000000 0.000000 0.000000 NaN NaN NaN 0.000000 8.000000 2009.000000 NaN NaN 214000.000000 max 1460.000000 190.000000 NaN 313.000000 215245.000000 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 10.000000 9.000000 2010.000000 2010.000000 NaN NaN NaN NaN NaN 1600.000000 NaN NaN NaN NaN NaN NaN NaN 5644.000000 NaN 1474.000000 2336.000000 6110.000000 NaN NaN NaN NaN 4692.000000 2065.000000 572.000000 5642.000000 3.000000 2.000000 3.000000 2.000000 8.000000 3.000000 NaN 14.000000 NaN 3.000000 NaN NaN 2010.000000 NaN 4.000000 1418.000000 NaN NaN NaN 857.000000 547.000000 552.000000 508.000000 480.000000 738.000000 NaN NaN NaN 15500.000000 12.000000 2010.000000 NaN NaN 755000.000000
2.数据清洗和缺失值填充
1.处理缺失值
查看有无空值,pandas的空值为NaN(字符串"NA"),所以我们先统计一下NaN值,参考:特征预处理——异常值处理
# 对有Nan值的列的空值比例进行排序,并添加上特征的名字和类型
nan_total = data.isna().sum().sort_values(ascending=False)
nan_percent = (data.isna().sum() / data.isnull().count()).sort_values(ascending=False)
feature_name = pd.Series(dict).T.sort_values(ascending=False)
feature_type = data.dtypes.sort_values(ascending=False)
missing_data = pd.concat(
[nan_total, nan_percent, feature_name, feature_type],
axis=1,
keys=['NanTotal', 'NanPercent', 'FeatureName', 'FeatureType']
)
print(missing_data.head(20))
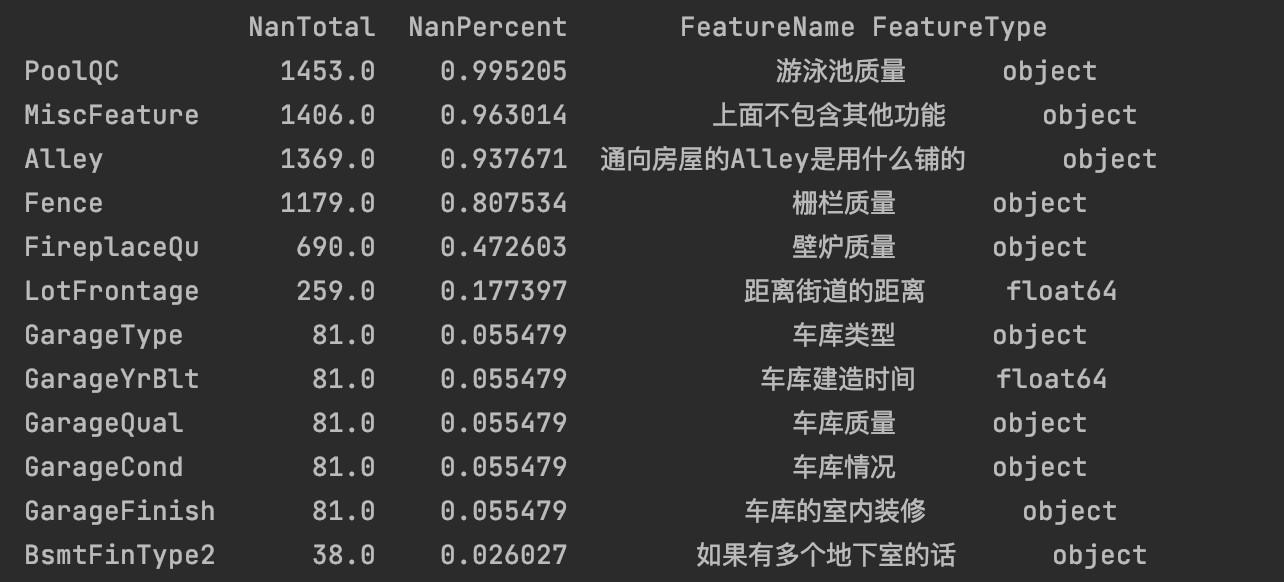
可以看出,PoolQC这一列有很多值是NaN,当空值比例远大于15%的时候,就可以考虑将这个特征删掉
# 删除NaN比例远超过15%的特征
train_data: DataFrame = train_data.drop(
columns=['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'MasVnrType', 'FireplaceQu']
)
print(train_data.shape)
还剩下73维特征
# 对LotFrontage进行双变量分析 sns.scatterplot(y=train_data['SalePrice'], x=train_data['LotFrontage']) plt.show()

可以使用删除红圈的离群点的LotFrontage的平均值来对缺失值进行填充
# 处理缺失值 # LotFrontage # sns.scatterplot(y=train_data['SalePrice'], x=data['LotFrontage']) # plt.show() train = data.drop(data[data['LotFrontage'] > 300].index) data['LotFrontage'] = data['LotFrontage'].fillna(train['LotFrontage'].mean())
处理其他缺失值
# GarageType # sns.scatterplot(y=train_data['SalePrice'], x=data['GarageType']) # plt.show() data['GarageType'].fillna(value='None', inplace=True) # GarageYrBlt # sns.scatterplot(y=train_data['SalePrice'], x=data['GarageYrBlt']) # plt.show() data['GarageYrBlt'] = data['GarageYrBlt'].fillna(data['GarageYrBlt'].mean()) # GarageFinish # sns.scatterplot(y=train_data['SalePrice'], x=data['GarageFinish']) # plt.show() data['GarageFinish'].fillna(value='None', inplace=True) # GarageQual # sns.scatterplot(y=train_data['SalePrice'], x=data['GarageQual']) # plt.show() data['GarageQual'].fillna(value='None', inplace=True) # GarageCond # sns.scatterplot(y=train_data['SalePrice'], x=data['GarageCond']) # plt.show() data['GarageCond'].fillna(value='None', inplace=True) # BsmtFinType2 # sns.scatterplot(y=train_data['SalePrice'], x=data['BsmtFinType2']) # plt.show() data['BsmtFinType2'].fillna(value='None', inplace=True) # BsmtExposure # sns.scatterplot(y=train_data['SalePrice'], x=data['BsmtExposure']) # plt.show() data['BsmtExposure'].fillna(value='None', inplace=True) # BsmtQual # sns.scatterplot(y=train_data['SalePrice'], x=data['BsmtQual']) # plt.show() data['BsmtQual'].fillna(value='None', inplace=True) # BsmtFinType1 # sns.scatterplot(y=train_data['SalePrice'], x=data['BsmtFinType1']) # plt.show() data['BsmtFinType1'].fillna(value='None', inplace=True) # BsmtCond # sns.scatterplot(y=train_data['SalePrice'], x=data['BsmtCond']) # plt.show() data['BsmtCond'].fillna(value='None', inplace=True) # MasVnrArea # sns.scatterplot(y=train_data['SalePrice'], x=data['MasVnrArea']) # plt.show() data['MasVnrArea'].fillna(value=0, inplace=True) # Electrical # sns.scatterplot(y=train_data['SalePrice'], x=data['Electrical']) # plt.show() data['Electrical'].fillna(value='SBrkr', inplace=True)
现在就将所有的缺失值填充好了
4.处理离群值
我们首先对需要预测的值进行离群值分析,首先绘制预测值SalePrice的箱型图
3.数据转换
5.特征分布处理
正态分布
4.特征选择
1.去掉变化小的特征
假设某特征的特征值只有0和1,并且在所有输入样本中,95%的实例的该特征取值都是1,那就可以认为这个特征作用不大。如果100%都是1,那这个特征就没意义了。参考:特征预处理——特征选择和特征理解
比如 Street 和 Utilities,unique是2且freq很高,应该去掉这类特征

# 删除变化小的特征
train_data: DataFrame = train_data.drop(
columns=['Street', 'Utilities']
)
2.相关性分析
先看一下房价的分布情况,15W刀左右的居多,可以看出这个数据集是很久以前的了

1.先分析数值型的特征,比如LotFrontage(通往房屋的street的距离)和LotArea(房子的建筑面积,包括车库院子啥的)
分析:因为距离有的值为NA的缘故,对其值为NA的处理成了距离为0。
按我们的思路,应该是距离越近价格越高(出行比较方便),可是事实上并不是这样子,可能是私家车在外国家庭的普及率问题,和street的距离同房价之间的关系并不是很明显

接下来分析房屋的建筑面积和房价之间的关系,为了直观些,我把单位从平方英尺转换成了平方米。
可以看到数据集中房屋的面积的峰值在900平方米左右,且房屋的建筑面积和房价是正相关的(废话)
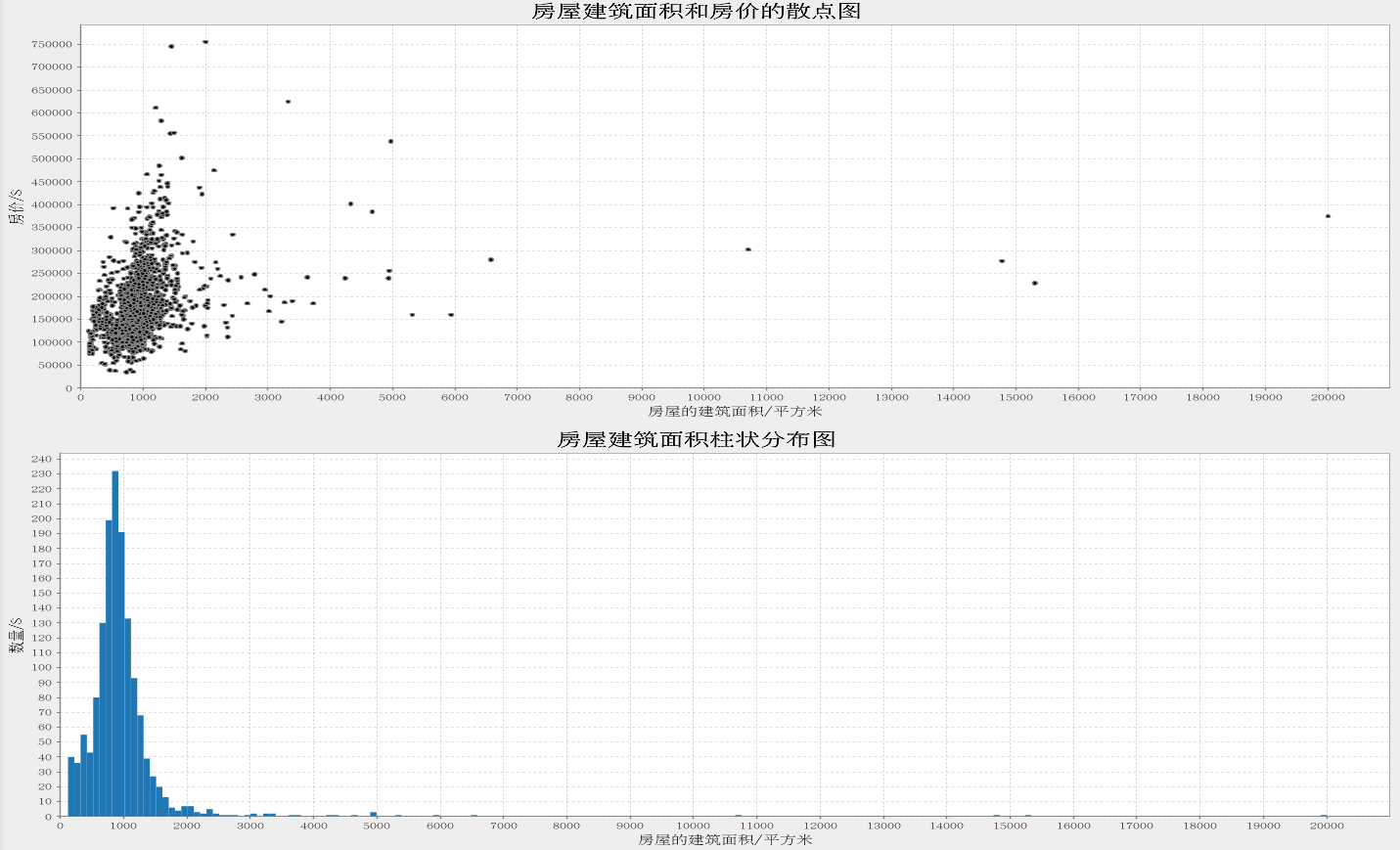
接下来再看看1层和2层面积和房价之间的关系
可以看到,1楼面积和2层面积(如果有的话),同房价之间的关系也很线性,除少数离群的点之外


本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/6916710.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号