特征预处理——异常值处理
pandas是python特征预处理常用的框架
1.查看数据
加载数据
#-*- coding: utf-8 -*-
import pandas as pd
train_data = pd.read_csv("./data/train.csv")
print(train_data)

pandas显示DataFrame数据的所有列,set_option其他参数参考:Pandas函数set_option()学习笔记
pd.set_option('expand_frame_repr', False) # 不换行
#pd.set_option('display.width', 200) # 列最多显示多少字符后换行
pd.set_option('display.min_rows', 20) # 至少显示20行数据
pd.set_option('display.max_columns', None) # 显示所有列
print(train_data)
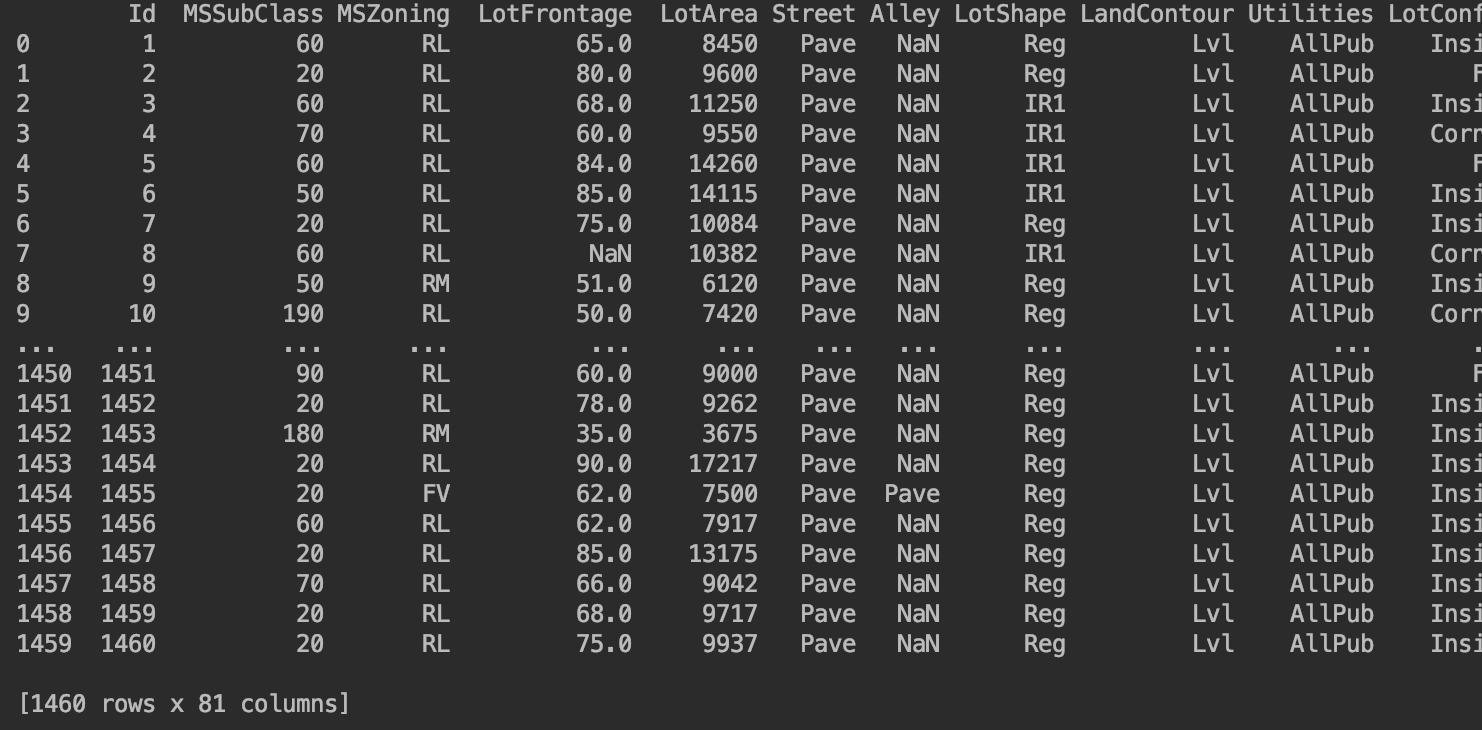
2.查看空值
在pandas中的空值为NaN,isna()等同于isnull()
print(train_data.isna()) # 判断所有值是否是na,转换成boolean值
对于csv字符串NA,用pandas读取的时候,会转换成NaN,对于字符串None,则不是NaN
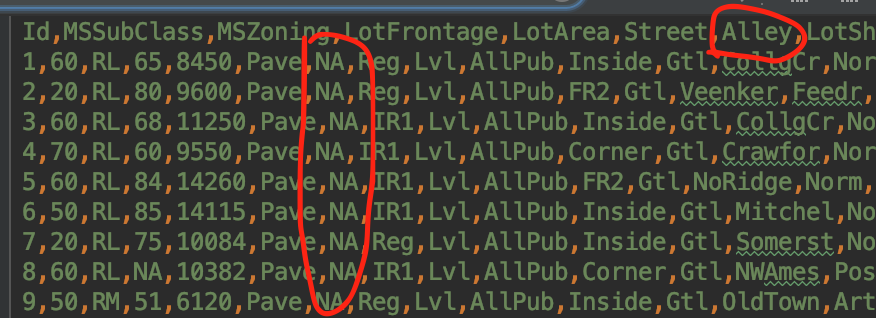
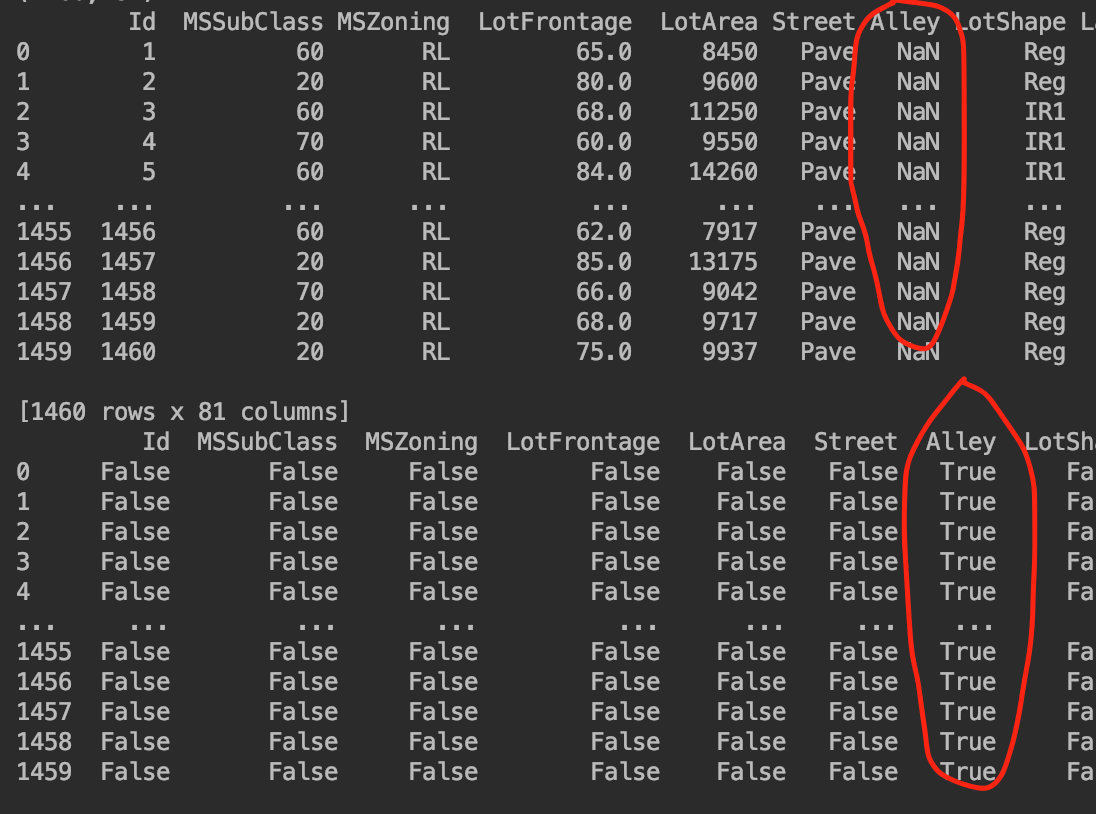
统计字段中Nan空值的总数
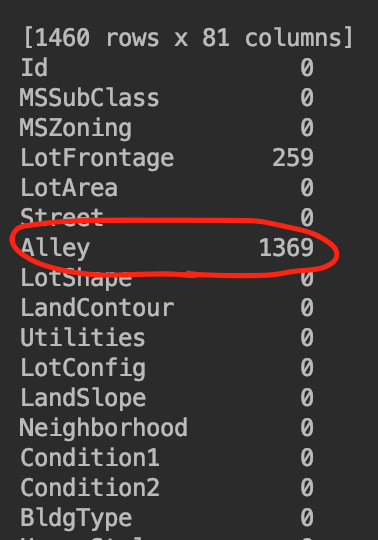
print(train_data.isna().sum())
查看某列是NaN的行
print(train_data[train_data.MiscFeature.isnull()])
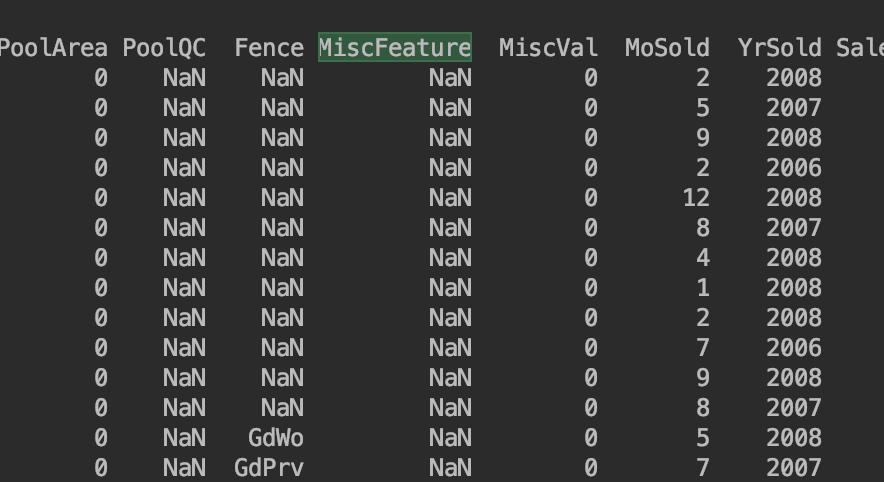
查看有NaN值的列名
print(train_data.columns[train_data.isnull().any()].tolist()) ['LotFrontage', 'Alley', 'MasVnrType', 'MasVnrArea', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'Electrical', 'FireplaceQu', 'GarageType', 'GarageYrBlt', 'GarageFinish', 'GarageQual', 'GarageCond', 'PoolQC', 'Fence', 'MiscFeature']
对有Nan值的列的空值比例进行排序
total = train_data.isna().sum().sort_values(ascending=False)
percent = (train_data.isna().sum() / train_data.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
print(missing_data.head(20))
Total Percent
PoolQC 1453 0.995205
MiscFeature 1406 0.963014
Alley 1369 0.937671
Fence 1179 0.807534
FireplaceQu 690 0.472603
LotFrontage 259 0.177397
GarageYrBlt 81 0.055479
GarageCond 81 0.055479
GarageType 81 0.055479
GarageFinish 81 0.055479
GarageQual 81 0.055479
BsmtFinType2 38 0.026027
BsmtExposure 38 0.026027
BsmtQual 37 0.025342
BsmtCond 37 0.025342
BsmtFinType1 37 0.025342
MasVnrArea 8 0.005479
MasVnrType 8 0.005479
Electrical 1 0.000685
Id 0 0.000000
3.删除和替换空值
删除某一列为NaN值的行,只要有一列是NaN,该行数据就会被删除
print(train_data.dropna(how='any'))
删除subset中某一列为NaN值的行,只要有一列是NaN,该行数据就会被删除
print(train_data.dropna(subset=['Fence', 'MiscFeature'], how='any'))
删除所有列都是NaN值的行
print(train_data.dropna(how='all'))
删除subset中所有列都是NaN值的行
print(train_data.dropna(subset=['Fence', 'MiscFeature'], how='all'))
其他
df.dropna(axis=1) #丢弃有缺失值的列 df.dropna(axis=1, how = 'all') #丢弃所有列中所有值均缺失的列 df.dropna(axis=0, subset=['name', 'age'])#丢弃name和age这两列中有缺失值的行
替换某列中的Nan值
train_data['Alley'].fillna(value='Not Found', inplace=True) print(train_data)
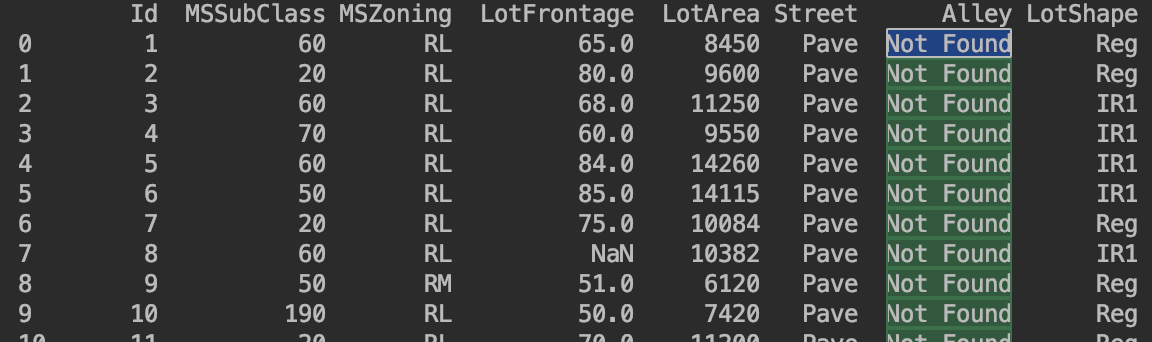
替换None字符串
print(train_data.replace('None', np.nan))
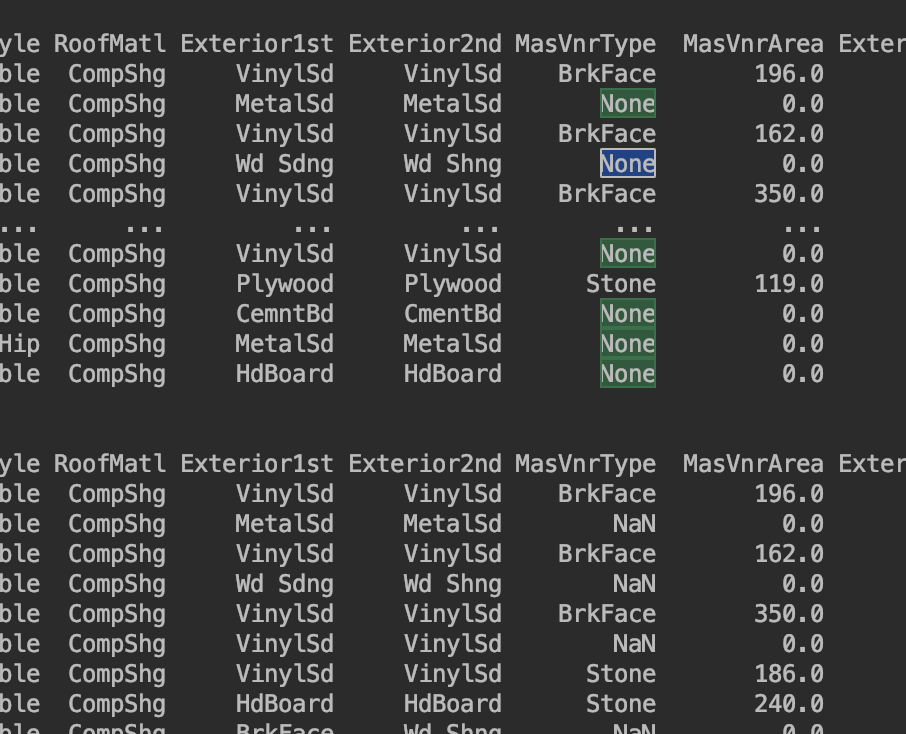
替换字符串的时候,如果替换改变原数据的值
train_data.replace('None', np.nan, inplace=True)
4.缺失值填充
参考:数据转化
也可以使用sklearn对特征的缺失值进行填充,方法有2种:
- 单变量:对第 i 个特征中的缺失值只使用该特征的某些信息来进行填充(impute.SimpleImputer)
- 多变量:对第 i 个特征中的缺失值使用整个数据集的信息来填充(impute.IterativeImputer)
数值型单变量缺失值填充
import numpy as np from sklearn.impute import SimpleImputer # 数值型单变量缺失值填充 imp = SimpleImputer(missing_values=np.nan, strategy='mean') imp.fit([[1, 2], [np.nan, 3], [7, 6]]) >> SimpleImputer() # 缺失值填充 (1+7)/2=4和(2+3+6)/3=3.66666667 X = [[np.nan, 2], [6, np.nan], [7, 6]] print(imp.transform(X)) [[4. 2. ] [6. 3.66666667] [7. 6. ]]
标称型单变量缺失值填充
import numpy as np
from sklearn.impute import SimpleImputer
import pandas as pd
# 标称型变量缺失值填充
df = pd.DataFrame([["a", "x"],
[np.nan, "y"],
["a", np.nan],
["b", "y"]], dtype="category")
# 使用出现次数最多的值来填充缺失值
imp = SimpleImputer(strategy="most_frequent")
print(imp.fit_transform(df))
[['a' 'x']
['a' 'y']
['a' 'y']
['b' 'y']]
多变量填充
多变量填充是使用全部数据建模的方式进行填充缺失值:含有缺失值的特征被视为 y,而其他特征当作 x,对 (x, y)拟合回归模型,然后利用这个模型来预测 y 中的缺失值:
from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputer imp = IterativeImputer(max_iter=10, random_state=0) imp.fit([[1, 2], [3, 6], [4, 8], [np.nan, 3], [7, np.nan]]) >> IterativeImputer(random_state=0) # 拟合出第2个变量是第1个变量的2倍 X_test = [[np.nan, 2], [6, np.nan], [np.nan, 6]] print(np.round(imp.transform(X_test))) [[ 1. 2.] [ 6. 12.] [ 3. 6.]]
最近邻填充
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/6298290.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号