
机器学习——利用K-均值聚类算法对未标注数据分组
聚类是一种无监督的学习,它将相似的对象归到同一簇中。它有点像全自动分类。聚类方法几乎可以应用到所有对象,簇内的对象越相似,聚类的效果越好。
K-均值(K-means)聚类算法,之所以称之为K-均值是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。
簇识别(cluster identification)给出簇类结果的含义。假定有一些数据,现在将相似数据归到一起,簇识别会告诉我们这些簇到底都是些什么。
K-均值聚类算法
优点:容易实现
缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢
使用数据类型:数值型数据
K-均值是发现给定数据集的k个簇的算法。簇个数k是用户给定的,每一个簇通过其质心(centroid),即簇中所有点的中心来描述。
K-均值算法的工作流程是:
1.随机确定k个初始点作为质心
2.然后将数据集中的每个点分配到一个簇中,具体来讲,为每个点找到其最近的质心,并将其分配给该质心所对应的簇。
3.完成之后,每个簇的质心更新为该簇所有点的平均值。

原数据

from numpy import *
def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float,curLine) #map all elements to float()
dataMat.append(fltLine)
return dataMat
def plotBestFit(file,clusterAssment): #画出数据集
import matplotlib.pyplot as plt
dataMat=loadDataSet(file) #数据矩阵和标签向量
dataArr = array(dataMat) #转换成数组
n = shape(dataArr)[0]
xcord1 = []; ycord1 = [] #声明两个不同颜色的点的坐标
xcord2 = []; ycord2 = []
for i in range(n): #绘出两个簇的聚类图
if (clusterAssment[i,0] == 0):
xcord1.append(dataArr[i,0]); ycord1.append(dataArr[i,1])
elif (clusterAssment[i,0] == 1):
xcord2.append(dataArr[i,0]); ycord2.append(dataArr[i,1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='green', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='red')
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
def distEclud(vecA, vecB): #计算两个向量的欧氏距离
return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB)
def randCent(dataSet, k): #为给定数据集构建一个包含k个随机质心的集合
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))
for j in range(n): #在n维向量中选出k个随机质心
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[:,j]) - minJ) #分别求出X轴和Y轴的最大最小值之差
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))
return centroids #返回k×n矩阵
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent): #K-均值聚类算法
m = shape(dataSet)[0] #取得数据集的数量
clusterAssment = mat(zeros((m,2))) #簇分配结果矩阵,第一列记录簇索引值,第二列存储误差
centroids = createCent(dataSet, k) #生成初始质心
clusterChanged = True
while clusterChanged:
clusterChanged = False #停止条件
for i in range(m): #把每一个点分配到最近的簇中
minDist = inf; minIndex = -1
for j in range(k): #比较每一个点到两个簇的距离,把所有的点分成两个簇
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: #只要有一个点被分配到另一个簇中,就重新计算质心后再次分配
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
#print centroids
for cent in range(k): #重新计算质心
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]] #取得给定簇的所有点
centroids[cent,:] = mean(ptsInClust, axis=0) #计算每个簇的均值,axis=0表示沿矩阵列方向进行均值计算
return centroids, clusterAssment #返回两个簇的质心、K-聚类结果以及误差
k=2,k-均值算法

k=4,k-均值算法
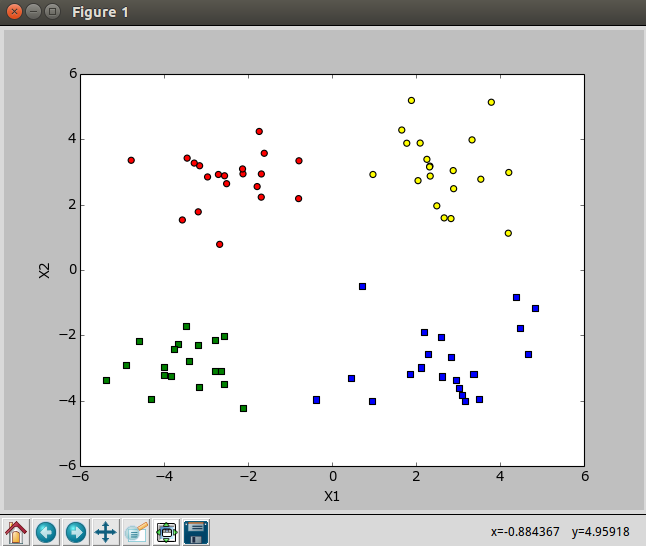
聚类的过程,较大的点表示质心




使用后处理来提高聚类性能
K-均值聚类中簇的数目k是一个用户预先定义的参数,用户需要知道怎么选取k值是正确的。
在包含簇分配结果的矩阵中保存这每个点的误差,即该点到簇质心的距离平方值,可以利用这个误差来评价聚类的质量。
一种用于度量聚类效果的指标是SSE(Sum of Squared Error,误差平方和)。SSE值越小表示数据点越接近于它们的质心,聚类效果也越好。因为对误差取了平方,因此桁架重视那些远离中心的点。
聚类的目标是在保持簇数不变的情况下提高簇的质量。
1.可以对生成的簇进行后处理,一种方式将具有最大SSE值的簇划分成两个簇。具体实现的时候,可以将最大簇包含的点过滤出来并在这些点上运行K-均值算法,其中的k设为2。
2.为了保持簇总数不变,可以将某两个簇进行合并。合并的方法是合并最近的质心,或者合并两个使得SSE增幅最小的质心。量化的方法有两种:
第一种思路是通过计算所有质心之间的距离,然后合并距离最近的两个点来实现。
第二种方法需要合并两个簇然后计算总SSE值。
必须在所有可能的两个簇上重复上述处理过程,知道找到合并最佳的两个簇为止。
二分K-均值算法
为克服K-均值算法收敛于局部最小值的问题,有人提出了另一个称为二分K-均值(bisecting K-mean)的算法。该算法首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否可以最大程度降低SSE的值。上述基于SSE的划分过程不断重复,直达得到用户指定的簇数目为止。
另一种做法是选择SSE最大的簇进行划分,知道簇数目达到用户指定的数目为止。
def biKmeans(dataSet, k, distMeas=distEclud): #二分K-均值聚类算法 m = shape(dataSet)[0] clusterAssment = mat(zeros((m,2))) centroid0 = mean(dataSet, axis=0).tolist()[0] #计算每个簇的均值,axis=0表示沿矩阵列方向进行均值计算,并矩阵转换成列表 centList =[centroid0] #生成一个列表,存放初始质心(所有点的均值) for j in range(m): #计算初始平方误差和 clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2 while (len(centList) < k): #当质心的数量还未达到用户设定的数量时 lowestSSE = inf for i in range(len(centList)): #循环所有的簇,选取其中SSE最大的簇继续进行划分 ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] #取得每一簇,初始只有一簇 centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas) #对每一簇进行2划分,centroidMat是质心,splitClustAss是划分索引 sseSplit = sum(splitClustAss[:,1]) #求SSE最大的簇进行2划分后的SSE和 sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) #求除SSE最大的簇之外的所有簇的SSE和 print "sseSplit, and notSplit: ",sseSplit,sseNotSplit if (sseSplit + sseNotSplit) < lowestSSE: #把SSE最大的簇2划分之后的SSE总和与原来的SSE和进行比较 bestCentToSplit = i bestNewCents = centroidMat bestClustAss = splitClustAss.copy() lowestSSE = sseSplit + sseNotSplit bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #取出等于1的索引,令其等于新的簇,change 1 to 3,4, or whatever bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit #取出等于0的索引,令其等于SSE最大的簇 print 'the bestCentToSplit is: ',bestCentToSplit print 'the len of bestClustAss is: ', len(bestClustAss) print clusterAssment.T raw_input() centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0] #replace a centroid with two best centroids centList.append(bestNewCents[1,:].tolist()[0]) clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss#reassign new clusters, and SSE return mat(centList), clusterAssment
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/6221652.html

