
机器学习——非均衡分类问题
在机器学习的分类问题中,我们都假设所有类别的分类代价是一样的。但是事实上,不同分类的代价是不一样的,比如我们通过一个用于检测患病的系统来检测马匹是否能继续存活,如果我们把能存活的马匹检测成患病,那么这匹马可能就会被执行安乐死;如果我们把不能存活的马匹检测成健康,那么就会继续喂养这匹马。一个代价是错杀一只昂贵的动物,一个代价是继续喂养,很明显这两个代价是不一样的。
1.性能度量
衡量模型泛化能力的评价标准,就是性能度量。除了基于错误率来衡量分类器任务的成功程度的。错误率指的是在所有测试样例中错分的样例比例。但是,这样却掩盖了样例如何被错分的事实。在机器学习中,有一个普遍试用的称为混淆矩阵(confusion matrix)的工具,可以帮助人们更好地了解分类的错误。

利用混淆矩阵就可以更好地理解分类中的错误了。如果矩阵中的非对角元素均为0,就会得到一个完美的分类器。
2.正确率(Precision)、召回率(Recall)

正确率P = TP/(TP+FP),给出的是预测为正例的样本中的真正正例的比例。
召回率R = TP/(TP+FN),给出的是预测为正例的真实正例占所有真实正例的比例。
3.ROC曲线
另一个用于度量分类中的非均衡性的工具是ROC曲线(ROC curve),ROC代表接收者操作特征"Receiver Operating Characteristic"
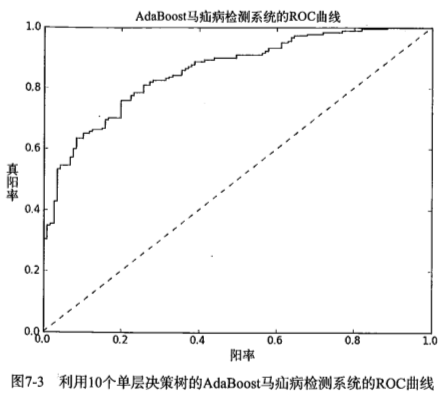
ROC曲线的纵轴是“真正例率”,TPR=TP/(TP+FN)
横轴是“假正例率”,FPR=FP/(TN+FP)
在理想的情况下,最佳的分类器应该尽可能地处于左上角,这就意味着分类器在假正例率很低的同时,获得了很高的真正例率。
4.AUC(曲线下的面积)
对不同的ROC曲线进行比较的一个指标就是曲线下的面积(AUC),AUC给出的是分类器的平均性能值。一个完美的分类器的AUC是1,而随机猜测的AUC则为0.5。
若一个学习器的ROC曲线能把另一个学习器的ROC曲线完全包住,则这个学习器的性能比较好。
为什么要使用AUC曲线
因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。AUC对样本的比例变化有一定的容忍性。AUC的值通常在0.6-0.85之间。
def plotROC(predStrengths, classLabels): #ROC曲线的绘制及AUC计算函数
import matplotlib.pyplot as plt
cur = (1.0,1.0) #cursor
ySum = 0.0 #variable to calculate AUC
numPosClas = sum(array(classLabels)==1.0)
yStep = 1/float(numPosClas); xStep = 1/float(len(classLabels)-numPosClas)
sortedIndicies = predStrengths.argsort()#get sorted index, it's reverse
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
#loop through all the values, drawing a line segment at each point
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0; delY = yStep;
else:
delX = xStep; delY = 0;
ySum += cur[1]
#draw line from cur to (cur[0]-delX,cur[1]-delY)
ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY], c='b')
cur = (cur[0]-delX,cur[1]-delY)
ax.plot([0,1],[0,1],'b--')
plt.xlabel('False positive rate'); plt.ylabel('True positive rate')
plt.title('ROC curve for AdaBoost horse colic detection system')
ax.axis([0,1,0,1])
plt.show()
print "the Area Under the Curve is: ",ySum*xStep
mian.py
# coding:utf-8
# !/usr/bin/env python
import adaboost
if __name__ == '__main__':
datMat,classLabels = adaboost.loadDataSet("horseColicTraining2.txt")
weakClassArr,aggClassEst = adaboost.adaBoostTrainDS(datMat,classLabels,40)
# datMat1,classLabels1 = adaboost.loadDataSet("horseColicTest2.txt")
aggClassEst,sign = adaboost.adaClassify(datMat,weakClassArr)
print aggClassEst.T
adaboost.plotROC(aggClassEst.T, classLabels)

基于代价函数的分类器决策控制
为权衡不同类型错误所造成的不同损失,可为错误赋予“非均等代价”。

在“代价矩阵”中,将-1错判成+1的代价(50),比把+1错判成-1的代价(1)要高。
处理非均衡问题的数据抽样方法
另外一种针对非均衡问题调节分类器的方法,就是对分类器的训练数据进行改造。这可以通过欠抽样或者过抽样来实现。
过抽样意味着复制样例,而欠抽样意味着删除样例。
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/6198283.html

