特征平台简介
特征平台(feature store)的定义:一个用于机器学习的数据管理层,允许共享和发现特征并创建更有效的机器学习管道。
1.特征平台业界实现
1.uber
其最早由uber于2017年提出,uber的feature store名为Michaelangelo,参考:Meet Michelangelo: Uber’s Machine Learning Platform

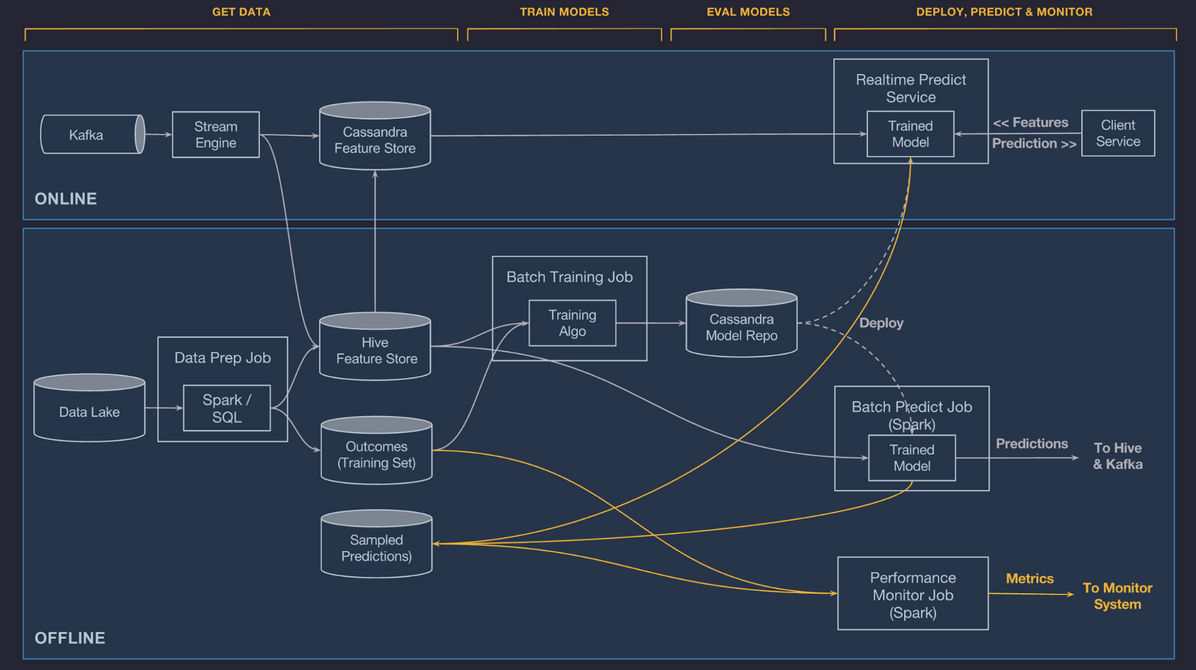
Michaelangelo主要提供以下6种特性,如下图所示:
- Manage data
- Train models
- Evaluate models
- Deploy models
- Make predictions
- Monitor predictions
2.美团
特征平台所能解决的一些问题:
- 特征迭代成本高:框架缺乏配置化管理,新特征上线需要同时改动离线侧和在线侧代码,迭代周期较长。
- 特征复用困难:外卖不同业务线间存在相似场景,使特征的复用成为可能,但框架缺乏对复用能力的很好支撑,导致资源浪费、特征价值无法充分发挥。
- 平台化能力缺失:框架提供了特征读写的底层开发能力,但缺乏对特征迭代完整周期的平台化追踪和管理能力。
其他美团的文章:美团配送实时特征平台建设实践
3.字节跳动
特征存储所解决的一些问题:
- 存储原始特征:由于在线特征抽取在特征调研上的低效率,我们期望能够存储原始特征;
- 离线调研能力:在原始特征的基础上,可以进行离线调研,从而提升特征调研效率;
- 支持特征回填:支持特征回填,在调研完成后,可以将历史数据全部刷上调研好的特征;
- 降低存储成本:充分利用数据分布的特殊性,降低存储成本,腾出资源来存储原始特征;
- 降低训练成本:训练时只读需要的特征,而非全量特征,降低训练成本;
- 提升训练速度:训练时尽量降低数据的拷贝和序列化反序列化开销。
2.特征拼接问题
1.离线拼接(离线特征)
以天级的batch任务来实现特征和曝光/点击的join,比如
曝光流,假设用户A在10点1分30秒,用户B在10点2分30秒刷到了文章1和文章2
| 用户id | 文章id | 时间戳 |
| A | 1 | 2022-01-01 10:01:30 |
| A | 2 | 2022-01-01 10:01:30 |
| B | 1 | 2022-01-01 10:02:30 |
| B | 2 | 2022-01-01 10:02:00 |
点击流,假设用户A在10点2分的时候点击了文章1,用户B在10点3分的时候点击了文章2
| 用户id | 文章id | 时间戳 |
| A | 1 | 2022-01-01 10:02:00 |
| B | 2 | 2022-01-01 10:03:00 |
join曝光流和点击流,得到可用于计算CTR的曝光点击表
| 用户id | 文章id | 曝光时间戳 | 点击时间戳 | label(0没点击/1点击) |
| A | 1 | 2022-01-01 10:01:30 | 2022-01-01 10:02:00 | 1 |
| A | 2 | 2022-01-01 10:01:30 | 0 | |
| B | 1 | 2022-01-01 10:02:30 | 0 | |
| B | 2 | 2022-01-01 10:02:30 | 2022-01-01 10:03:00 | 1 |
用户离线特征表,包含2个特征:年龄和性别
| 用户id | 用户年龄 | 用户性别 |
| A | 30 | 男 |
| B | 20 | 女 |
文章离线特征表,包含2个特征:标签和来源
| 文章id | 文章标签 | 文章来源 |
| 1 | 体育 | NBA |
| 2 | 政治 | BBC |
拼接特征得到训练样本
| 用户id | 用户年龄 | 用户性别 | 文章id | 文章标签 | 文章来源 | 曝光时间戳 | 点击时间戳 | label(0没点击/1点击) |
| A | 30 | 男 | 1 | 体育 | NBA | 2022-01-01 10:01:30 | 2022-01-01 10:02:00 | 1 |
| A | 30 | 男 | 2 | 政治 | BBC | 2022-01-01 10:01:30 | 0 | |
| B | 20 | 女 | 1 | 体育 | NBA | 2022-01-01 10:02:30 | 0 | |
| B | 20 | 女 | 2 | 政治 | BBC | 2022-01-01 10:02:30 | 2022-01-01 10:03:00 | 1 |
这时候就获得了一张可以用于训练的训练集,但是该方案的问题也很明显,训练的周期是天级别的,无法支持在线学习(即实时特征),join的计算量大
2.实时拼接(离线特征+实时特征)
如果想添加一些实时特征的话,比如
用户实时特征流,包含1个特征:用户最近10分钟看的文章的数量
| 用户id | 用户最近10分钟看的文章的数量 | 时间戳 |
| A | 10 | 2022-01-01 10:00:00 |
| B | 20 | 2022-01-01 10:00:00 |
文章实时特征流,包含1个特征:最近10分钟文章的点赞数量
| 文章id | 最近10分钟文章的点赞数量 | 时间戳 |
| 1 | 100 | 2022-01-01 10:00:00 |
| 2 | 200 | 2022-01-01 10:00:00 |
可以使用flink进行双流join,在窗口10分钟内,把点击流,曝光流,实时用户特征流,实时文章特征流进行join,得到
| 特征时间戳 | 用户id | 用户最近10分钟看的文章的数量 | 文章id | 最近10分钟文章的点赞数量 | 曝光时间戳 | 点击时间戳 | label(0没点击/1点击) |
| 2022-01-01 10:00:00 | A | 10 | 1 | 100 | 2022-01-01 10:01:30 | 2022-01-01 10:02:00 | 1 |
| 2022-01-01 10:00:00 | A | 10 | 2 | 200 | 2022-01-01 10:01:30 | 0 | |
| 2022-01-01 10:00:00 | B | 20 | 1 | 100 | 2022-01-01 10:02:30 | 0 | |
| 2022-01-01 10:00:00 | B | 20 | 2 | 200 | 2022-01-01 10:02:30 | 2022-01-01 10:03:00 | 1 |
注意这里使用的实时特征的窗口是离曝光时间戳最近的特征时间戳,否则会产生特征穿越问题
然后使用flink的lookup table join(详解flink中Look up维表的使用)补齐离线特征(会消耗比较大的KV缓存资源),或者在实时用户流和实时文章流中join上离线特征(会消耗比较大的kafka资源),得到训练样本
| 特征时间戳 | 用户id | 用户最近10分钟看的文章的数量 | 用户年龄 | 用户性别 | 文章id | 最近10分钟文章的点赞数量 | 文章标签 | 文章来源 | 曝光时间戳 | 点击时间戳 | label(0没点击/1点击) |
| 2022-01-01 10:00:00 | A | 10 | 30 | 男 | 1 | 100 | 体育 | NBA | 2022-01-01 10:01:30 | 2022-01-01 10:02:00 | 1 |
| 2022-01-01 10:00:00 | A | 10 | 30 | 男 | 2 | 200 | 政治 | BBC | 2022-01-01 10:01:30 | 0 | |
| 2022-01-01 10:00:00 | B | 20 | 20 | 女 | 1 | 100 | 体育 | NBA | 2022-01-01 10:02:30 | 0 | |
| 2022-01-01 10:00:00 | B | 20 | 20 | 女 | 2 | 200 | 政治 | BBC | 2022-01-01 10:02:30 | 2022-01-01 10:03:00 | 1 |
3.使用支持partial update的存储
比如HBase和Hudi,把两表Join过程转化为两表写入数据库的过程
美团最终的流式样本生成方案如下图:
- 特征快照中只包含流式、即时特征
- 特征快照写入Kafka
- 曝光/点击流以Insert形式写入HBase
- 特征快照在Kafka中延迟N分钟后,以Update形式写入HBase,并在写入过程中,二次访问Feature Store完成批式特征补录
- 从HBase中抽取样本供在线/离线训练使用
参考:模型样本构建方案演进之路 和 外卖广告大规模深度学习模型工程实践 | 美团外卖广告工程实践专题连载
3.特征的生成方式
1.特征回填(Backfilling Data)
2.特征快照(Snapshot)
3.特征请求快照(Request Snapshot)
4.Embedding特征
特征数据除了可以分成离线特征和实时特征之外,还可以按特征的稀疏程度进行分类,比如文本类,用户标签之类的特征就属于稀疏特征(Sparse Feature),而各种隐因子模型产出的特征,就属于稠密特征(Dense Feature),即Embedding特征。
对于稠密特征向量,例如各种隐因子向量,Embedding 向量,可以考虑文件存储,采用内存映射的方式,会更加高效地读取和使用。
5.正排和倒排
正排特征就使用的是用户ID或者文章ID来作为查询的主键,正排用于将用户特征+文章特征+曝光点击数据,拼凑成训练样本用于离线模型训练;同时在推荐系统或者广告系统中也会用于模型的online serving或者过滤(比如说基于规则、黑白名单、广告主预算 pacing 过滤等)。由于查询层需要支持按一些特定的字段进行筛选过滤,所以在选择反序列化方案的时候,就需要考虑性能问题,参考:推荐系统倒排索引 和 广告召回系统的演进
倒排特征则是使用特征作为查询的主键,比如用户的标签,倒排用于召回候选集的时候,比如已知用户的个人标签,要用个人标签召回新闻,那么就需要提前准备好标签对应的新闻文章的倒排索引,最后再通过itemId去正排里拉取详情。
这两种形态的特征数据,需要用不同的数据库存储。正排特征如果是用于离线模型训练,一般是存在Hive或者Hudi表中;正排特征如果是用于模型的online serving或者filter的话,则需要用列式数据库存储,比如HBase 和 Cassandra;倒排索引需要用 KV 数据库存储比如 Redis 或 Memcached。
参考:30 | 推荐系统服务化、存储选型及API设计 和 推荐系统从0到1
6.特征穿越问题
1.什么是特征穿越
特征穿越指的是特征的时间戳和label的时间戳不匹配,特征穿越一般发生在实时特征上面
错误的join

正确的join

为了让大家能够理解什么叫特征穿越,上图给出了一个简单例子,来展现这个问题。
图左上表是用户的一个行为特征,表达了在不同时间节点,对于一个给定 ID 的用户,在最近两分钟内的点击数。这个点击数可能帮助我们推理用户是否会点击某个广告。为了用这些特征去做训练,通常需要将特征拼接到用户带有 Label 的一些数据集上。
图左下表展现的是一个用户实际有没有点击广告的一些正样本和负样本的数据集,标注了在不同的时间点,用户所产生的正样本或负样本。为了将这两个数据集中的特征拼接起来,形成训练用的数据集,通常需要根据用户 ID 作为 key 进行特征拼接。如果只是简单地进行 Table Join,不考虑时间戳,就可能产生特征穿越问题。 例如在 6:03 分时,用户最近 2 分钟点击数应该是 10,但拼接得到的特征值可能是来自 7:00 分时的 6。这种特征穿越会带来实际推理效果的下降。参考:流批一体的实时特征工程平台建设实践
2.point-in-time correct join
SQL的思路就是先将曝光点击表和特征表进行inner join,曝光点击表的时间戳取曝光时间戳event_timestamp,特征表的时间戳为feature_timestamp
曝光点击表
| 用户id | 文章id | 曝光时间戳(event_timestamp) | 点击时间戳 | label(0没点击/1点击) |
| A | 1 | 2022-01-01 10:01:30 | 2022-01-01 10:02:00 | 1 |
| A | 2 | 2022-01-01 10:01:30 | 0 | |
| B | 1 | 2022-01-01 10:02:30 | 0 | |
| B | 2 | 2022-01-01 10:02:30 | 2022-01-01 10:03:00 | 1 |

特征表
| 特征时间戳(每10分钟一个窗口、feature_timestamp) | 用户id | 用户最近10分钟看的文章的数量 | 文章id | 最近10分钟文章的点赞数量 |
| 2022-01-01 09:40:00 | B | 5 | 1 | 5 |
| 2022-01-01 09:50:00 | A | 20 | 1 | 10 |
| 2022-01-01 09:50:00 | B | 10 | 2 | 50 |
| 2022-01-01 10:00:00 | A | 10 | 1 | 100 |
| 2022-01-01 10:00:00 | A | 10 | 2 | 200 |
| 2022-01-01 10:00:00 | B | 20 | 1 | 100 |
| 2022-01-01 10:00:00 | B | 20 | 2 | 200 |

使用用户id和文章id进行inner join,得到如下表
CREATE VIEW feature_data AS
select feature_timestamp,
t1.user_id,
view_num_10_mins,
t1.doc_id,
doc_like_num_10_mins,
event_timestamp,
click_timestamp,
label
from (select * from click_view) t1
inner join
(select * from feature_table) t2
on t1.user_id = t2.user_id and t1.doc_id = t2.doc_id
可以看到由于特征有多个版本(例子里面有3个版本),所以join出来的结果会比较多,但是我们需要取得离event_timestamp最近的特征(红色标记),所以需要进行DeDuplicate操作
| 特征时间戳(每10分钟一个窗口、feature_timestamp) | 用户id | 用户最近10分钟看的文章的数量 | 文章id | 最近10分钟文章的点赞数量 | 曝光时间戳(event_timestamp) | 点击时间戳 | label(0没点击/1点击) |
| 2022-01-01 09:40:00 | B | 5 | 1 | 5 | 2022-01-01 10:02:30 | 0 | |
| 2022-01-01 09:50:00 | A | 20 | 1 | 10 | 2022-01-01 10:01:30 | 2022-01-01 10:02:00 | 1 |
| 2022-01-01 09:50:00 | B | 10 | 2 | 50 | 2022-01-01 10:02:30 | 2022-01-01 10:03:00 | 1 |
| 2022-01-01 10:00:00 | A | 10 | 1 | 100 | 2022-01-01 10:01:30 | 2022-01-01 10:02:00 | 1 |
| 2022-01-01 10:00:00 | A | 10 | 2 | 200 | 2022-01-01 10:01:30 | 0 | |
| 2022-01-01 10:00:00 | B | 20 | 1 | 100 | 2022-01-01 10:02:30 | 0 | |
| 2022-01-01 10:00:00 | B | 20 | 2 | 200 | 2022-01-01 10:02:30 | 2022-01-01 10:03:00 | 1 |

DeDuplicate操作
将event_timestamp,user_id和doc_id进行group by,找到最大的feature_timestamp时候的user_id和doc_id,
然后inner join上feature_data表,找到离event_timestamp最近的feature_timestamp的特征,从而实现point-in-time correct join
select
t1.feature_timestamp,
t1.user_id,
view_num_10_mins,
t1.doc_id,
doc_like_num_10_mins,
event_timestamp,
click_timestamp,
label
from (select * from feature_data) t1
inner join
(select max(feature_timestamp) as feature_timestamp,user_id,doc_id from feature_data group by event_timestamp, user_id, doc_id) t2
on t1.feature_timestamp = t2.feature_timestamp and t1.user_id = t2.user_id and t1.doc_id = t2.doc_id

参考:Point-in-Time Correct Join:Feast Spark版实现 和 Feast on AWS 解决方案
7.离在线一致性问题
参考:特征平台
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/5535732.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号