

Flink学习笔记——Flink Mongo CDC
1.Flink CDC介绍
Flink CDC提供了一系列connector,用于从其他数据源获取变更数据(change data capture)
官方文档
1 | https://ververica.github.io/flink-cdc-connectors/release-2.3/content/about.html |
官方github
1 | https://github.com/ververica/flink-cdc-connectors |
各种数据源使用案例,参考:
基于 AWS S3、EMR Flink、Presto 和 Hudi 的实时数据湖仓 – 使用 EMR 迁移 CDH
2.Flink Mongo CDC
1.snapshot阶段支持checkpoint(断点续传)
这个具体值的是如果在snapshot阶段,某次checkpoint failed,或者停掉flink job,然后从最新的checkpoint重新flink job,都是能实现断点续传的,使用的话只需要添加如下配置
1 | scan.incremental.snapshot.enabled = true |

2.snapshot阶段支持并发同步
1 | /usr/lib/flink/bin/flink run -t yarn-session -p 10 ... |

bucket_write阶段的并发度由 write.tasks 参数决定
compact_task阶段的并发度由 compaction.tasks 参数决定
其他参数参考:flink-quick-start-guide 和 数据湖架构Hudi(五)Hudi集成Flink案例详解
1 | Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster |
3.mongo snapshot的split策略
作者介绍其使用了3种split策略,分别是 SampleBucketSplitStrategy,SplitVector split和 MongoDBChunkSplitter,参考:Flink CDC MongoDB Connector 的实现原理和使用实践
为了在snapshot阶段支持并发,所以在snapshot阶段同步的时候,会使用 SnapshotSplitAssigner 对Mongo的collection进行切分
1 | https://github.com/ververica/flink-cdc-connectors/blob/release-2.3.0/flink-cdc-base/src/main/java/com/ververica/cdc/connectors/base/source/assigner/SnapshotSplitAssigner.java |
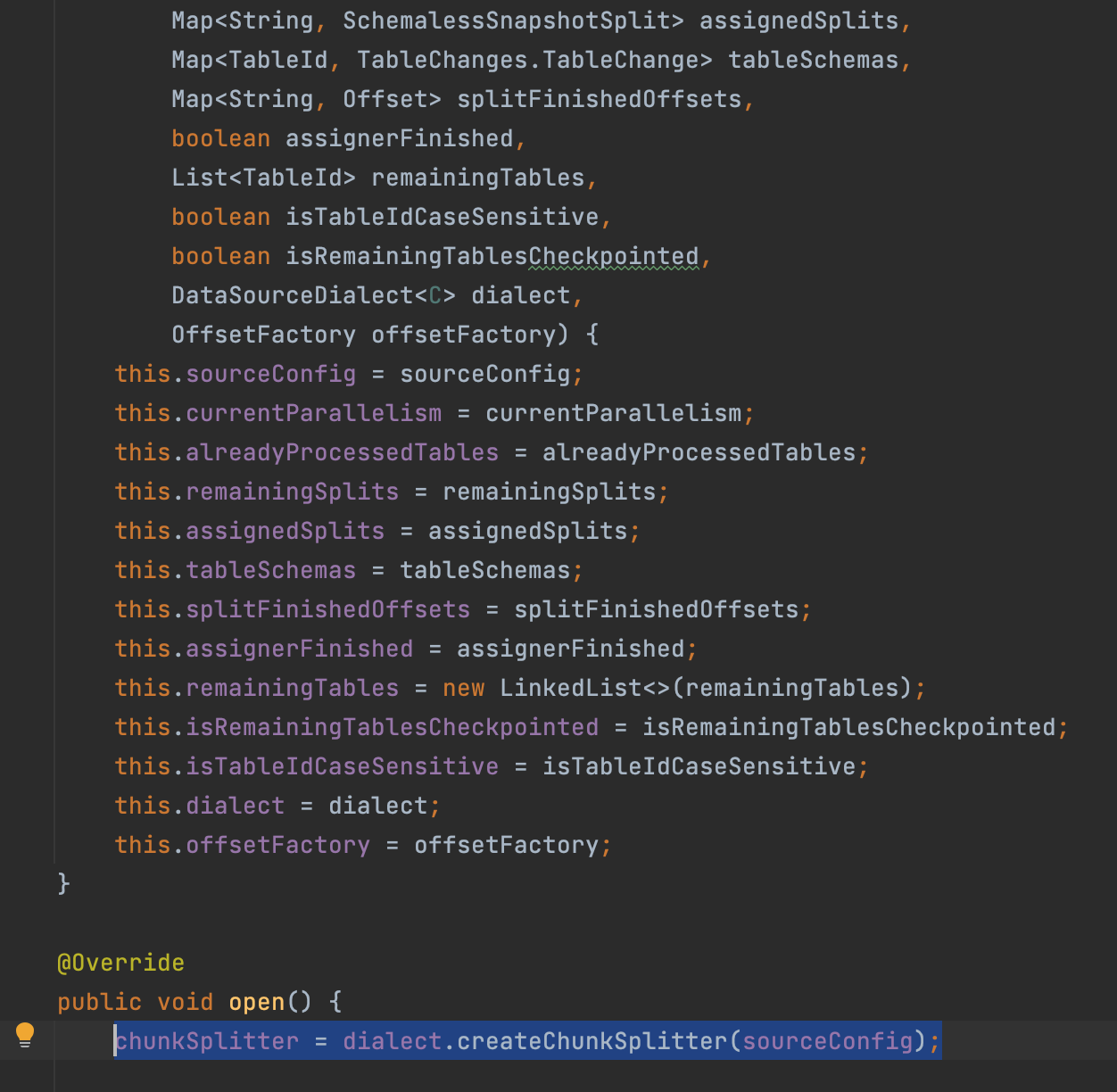
dialect实现的类为MongoDBDialect
1 | https://github.com/ververica/flink-cdc-connectors/blob/release-2.3.0/flink-connector-mongodb-cdc/src/main/java/com/ververica/cdc/connectors/mongodb/source/dialect/MongoDBDialect.java |

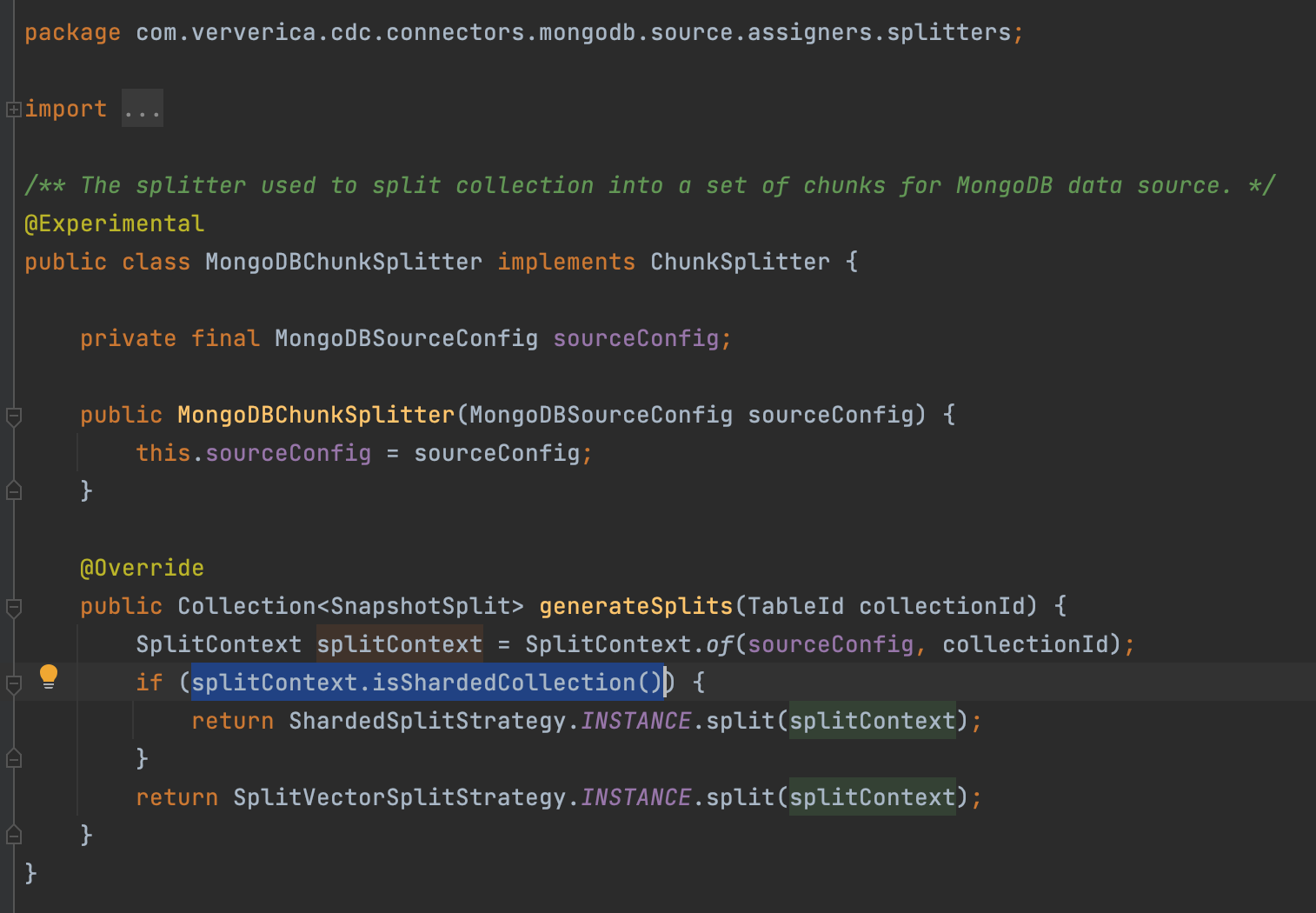
在 MongoDBChunkSplitter 类中,对于sharded collection,会使用 ShardedSplitStrategy 策略来对mongo进行切分,否则会使用 SplitVectorSplitStrategy 策略进行切分
1 | https://github.com/ververica/flink-cdc-connectors/blob/release-2.3.0/flink-connector-mongodb-cdc/src/main/java/com/ververica/cdc/connectors/mongodb/source/assigners/splitters/MongoDBChunkSplitter.java |
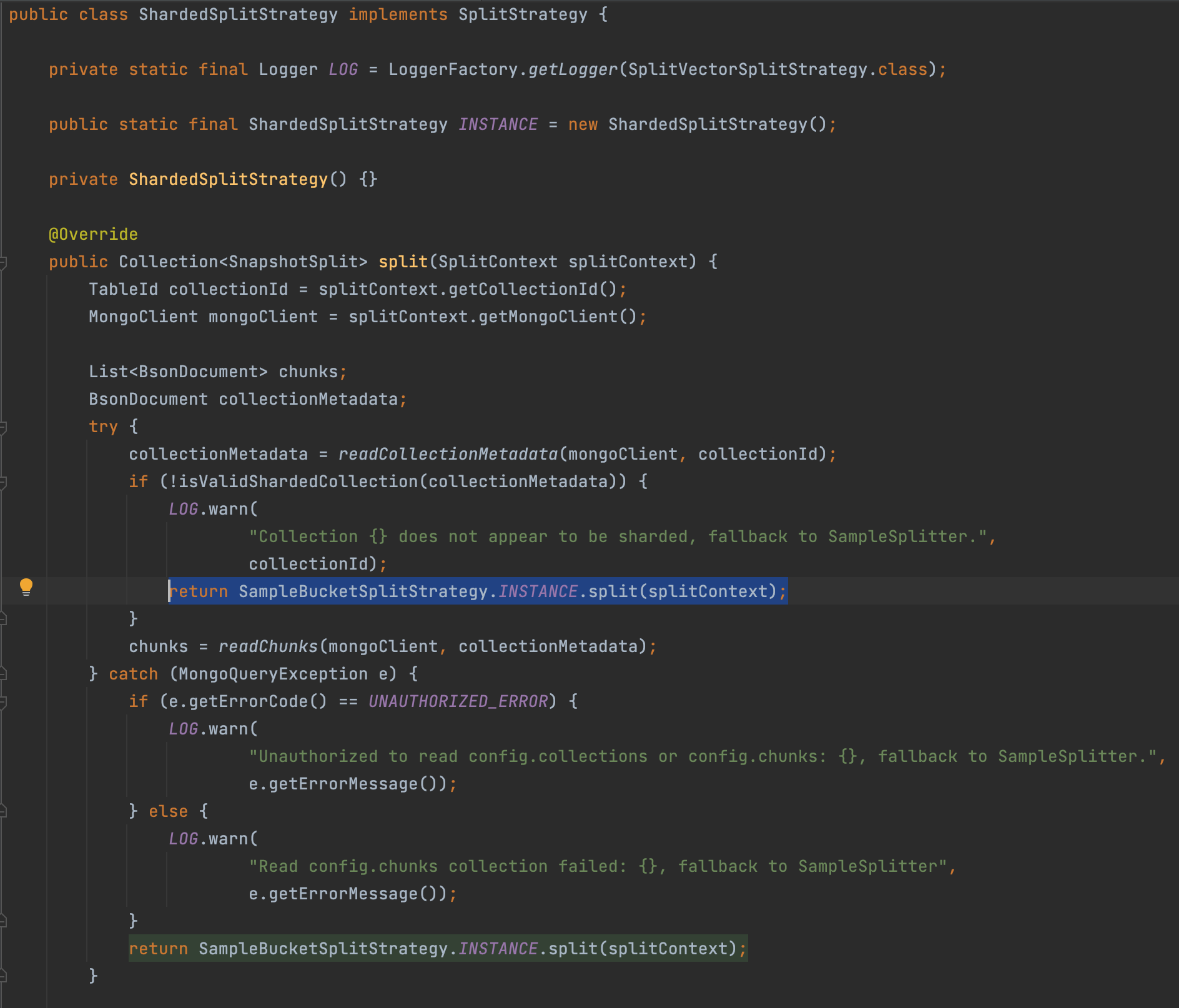
如果是sharded collection,当验证sharded collection失败或者没有config.collection或者config.chunks权限的时候,则会使用 SampleBucketSplitStrategy 策略进行切分
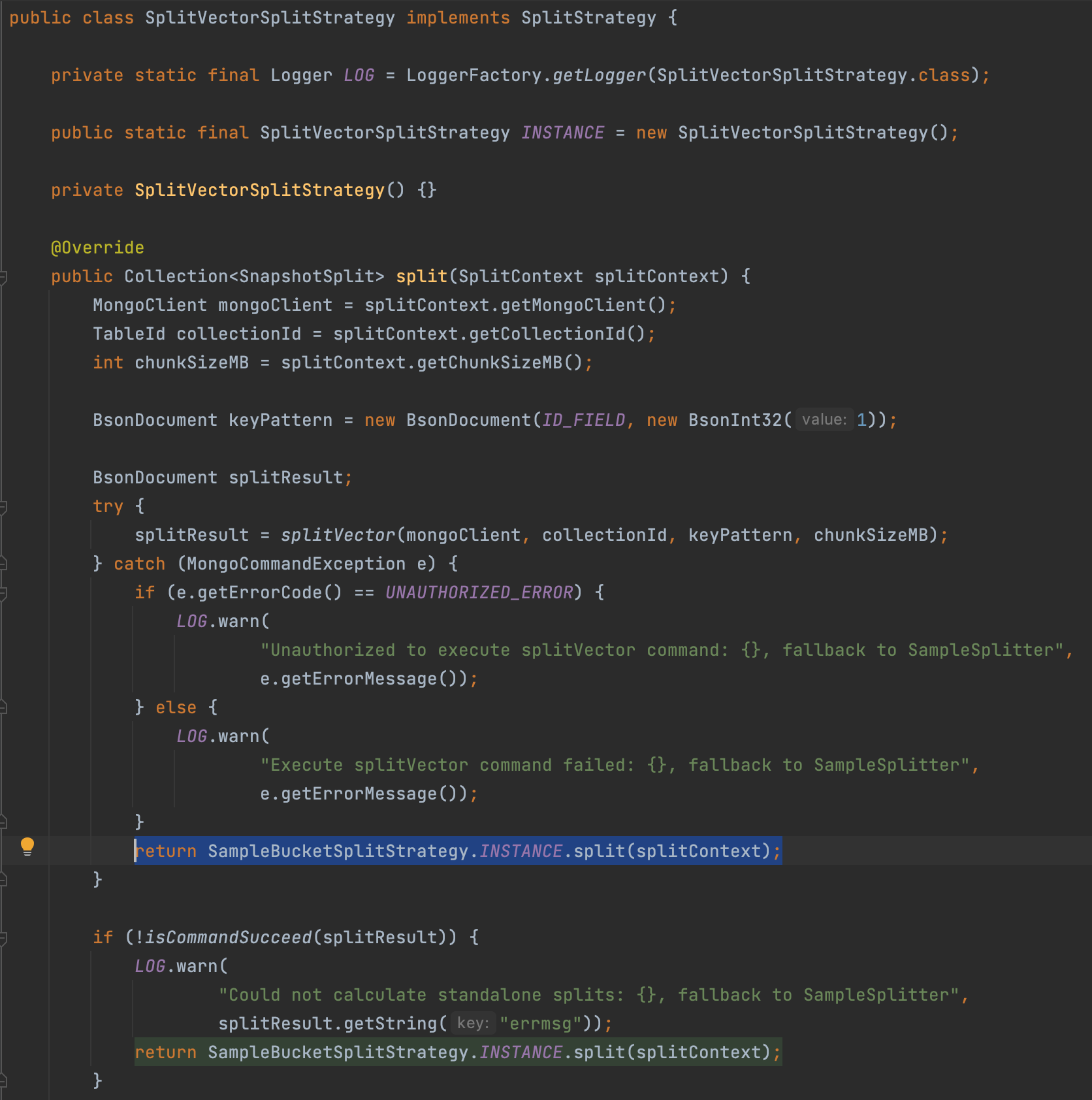
如果不是sharded collection,当没有 splitVector 权限或者无法切分collection的话,则会使用 SampleBucketSplitStrategy 策略进行切分
4.Flink Mongo CDC遇到的报错处理方法
1.Caused by: com.mongodb.MongoQueryException: Query failed with error code 280 and error message 'cannot resume stream; the resume token was not java.lang.RuntimeException: One or more fetchers have encountered exception
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:225) at org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:169) at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:130) at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:385) at org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:519) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:804) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:753) at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:948) at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:927) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:741) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563) at java.lang.Thread.run(Thread.java:750)Caused by: java.lang.RuntimeException: SplitFetcher thread 6 received unexpected exception while polling the records at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:150) at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:105) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 moreCaused by: org.apache.flink.util.FlinkRuntimeException: Read split SnapshotSplit{tableId=xxx.xxx, splitId='xxxx.xx:661', splitKeyType=[`_id` INT], splitStart=[{"_id": 1}, {"_id": "0MowwELT"}], splitEnd=[{"_id": 1}, {"_id": "0MoxTSHT"}], highWatermark=null} error due to Query failed with error code 280 and error message 'cannot resume stream; the resume token was not found. {_data: "82646B6EBA00000C5D2B022C0100296E5A1004B807779924DA402AB13486B3F67B6102463C5F6964003C306D483170686A75000004"}' on server xxxx:27017. at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceScanFetcher.checkReadException(IncrementalSourceScanFetcher.java:181) at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceScanFetcher.pollSplitRecords(IncrementalSourceScanFetcher.java:128) at com.ververica.cdc.connectors.base.source.reader.IncrementalSourceSplitReader.fetch(IncrementalSourceSplitReader.java:73) at org.apache.flink.connector.base.source.reader.fetcher.FetchTask.run(FetchTask.java:58) at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:142) ... 6 moreCaused by: com.mongodb.MongoQueryException: Query failed with error code 280 and error message 'cannot resume stream; the resume token was not found. {_data: "82646B6EBA00000C5D2B022C0100296E5A1004B807779924DA402AB13486B3F67B6102463C5F6964003C306D483170686A75000004"}' on server cxxxx:27017 at com.mongodb.internal.operation.QueryHelper.translateCommandException(QueryHelper.java:29) at com.mongodb.internal.operation.QueryBatchCursor.lambda$getMore$1(QueryBatchCursor.java:282) at com.mongodb.internal.operation.QueryBatchCursor$ResourceManager.executeWithConnection(QueryBatchCursor.java:512) at com.mongodb.internal.operation.QueryBatchCursor.getMore(QueryBatchCursor.java:270) at com.mongodb.internal.operation.QueryBatchCursor.tryHasNext(QueryBatchCursor.java:223) at com.mongodb.internal.operation.QueryBatchCursor.lambda$tryNext$0(QueryBatchCursor.java:206) at com.mongodb.internal.operation.QueryBatchCursor$ResourceManager.execute(QueryBatchCursor.java:397) at com.mongodb.internal.operation.QueryBatchCursor.tryNext(QueryBatchCursor.java:205) at com.mongodb.internal.operation.ChangeStreamBatchCursor$3.apply(ChangeStreamBatchCursor.java:102) at com.mongodb.internal.operation.ChangeStreamBatchCursor$3.apply(ChangeStreamBatchCursor.java:98) at com.mongodb.internal.operation.ChangeStreamBatchCursor.resumeableOperation(ChangeStreamBatchCursor.java:195) at com.mongodb.internal.operation.ChangeStreamBatchCursor.tryNext(ChangeStreamBatchCursor.java:98) at com.mongodb.client.internal.MongoChangeStreamCursorImpl.tryNext(MongoChangeStreamCursorImpl.java:78) at com.ververica.cdc.connectors.mongodb.source.reader.fetch.MongoDBStreamFetchTask.execute(MongoDBStreamFetchTask.java:116) at com.ververica.cdc.connectors.mongodb.source.reader.fetch.MongoDBScanFetchTask.execute(MongoDBScanFetchTask.java:183) at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceScanFetcher.lambda$submitTask$0(IncrementalSourceScanFetcher.java:94) ... 5 more |
这是由于flink mongo cdc 2.3.0 及其以下版本的bug导致,可以考虑自行打包2.4 snapshot分支来进行fix,参考作者官方的fix:https://github.com/ververica/flink-cdc-connectors/pull/1938
resume token 用来描述一个订阅点,本质上是 oplog 信息的一个封装,包含 clusterTime、uuid、documentKey等信息,当订阅 API 带上 resume token 时,MongoDB Server 会将 token 转换为对应的信息,并定位到 oplog 起点继续订阅操作。
参考:MongoDB 4.2 内核解析 - Change Stream
2.java.lang.NoSuchMethodError: org.apache.commons.cli.Option.builder(Ljava/lang/String;)Lorg/apache/commons/cli/Option$Builder
1 2 3 4 | java.lang.NoSuchMethodError: org.apache.commons.cli.Option.builder(Ljava/lang/String;)Lorg/apache/commons/cli/Option$Builder; at org.apache.flink.yarn.cli.FlinkYarnSessionCli.<init>(FlinkYarnSessionCli.java:197) at org.apache.flink.yarn.cli.FlinkYarnSessionCli.<init>(FlinkYarnSessionCli.java:173) at org.apache.flink.yarn.cli.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:836) |
这是由于commons-cli包版本过低导致的,从1.2.升级到1.5.0可以解决这个问题
3.Caused by: com.mongodb.MongoCursorNotFoundException: Query failed with error code -5 and error message 'Cursor 7652758736186712320 not found on server xxxx:27017' on server xxxx:27017
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | java.lang.RuntimeException: One or more fetchers have encountered exception at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:225) at org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:169) at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:130) at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:385) at org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:519) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:804) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:753) at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:948) at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:927) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:741) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563) at java.lang.Thread.run(Thread.java:750)Caused by: java.lang.RuntimeException: SplitFetcher thread 0 received unexpected exception while polling the records at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:150) at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:105) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 moreCaused by: org.apache.flink.util.FlinkRuntimeException: Read split SnapshotSplit{tableId=xxxx.xxxx, splitId='xxxx.xxxx:134146', splitKeyType=[`_id` INT], splitStart=[{"_id": 1}, {"_id": "0mWXDXGK"}], splitEnd=[{"_id": 1}, {"_id": "0mWXkf7v"}], highWatermark=null} error due to Query failed with error code -5 and error message 'Cursor 7652758736186712320 not found on server xxxx:27017' on server xxxx:27017. at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceScanFetcher.checkReadException(IncrementalSourceScanFetcher.java:181) at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceScanFetcher.pollSplitRecords(IncrementalSourceScanFetcher.java:128) at com.ververica.cdc.connectors.base.source.reader.IncrementalSourceSplitReader.fetch(IncrementalSourceSplitReader.java:73) at org.apache.flink.connector.base.source.reader.fetcher.FetchTask.run(FetchTask.java:58) at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:142) ... 6 moreCaused by: com.mongodb.MongoCursorNotFoundException: Query failed with error code -5 and error message 'Cursor 7652758736186712320 not found on server xxxx:27017' on server xxxx:27017 at com.mongodb.internal.operation.QueryHelper.translateCommandException(QueryHelper.java:27) at com.mongodb.internal.operation.QueryBatchCursor.lambda$getMore$1(QueryBatchCursor.java:282) at com.mongodb.internal.operation.QueryBatchCursor$ResourceManager.executeWithConnection(QueryBatchCursor.java:512) at com.mongodb.internal.operation.QueryBatchCursor.getMore(QueryBatchCursor.java:270) at com.mongodb.internal.operation.QueryBatchCursor.doHasNext(QueryBatchCursor.java:156) at com.mongodb.internal.operation.QueryBatchCursor$ResourceManager.execute(QueryBatchCursor.java:397) at com.mongodb.internal.operation.QueryBatchCursor.hasNext(QueryBatchCursor.java:143) at com.mongodb.client.internal.MongoBatchCursorAdapter.hasNext(MongoBatchCursorAdapter.java:54) at com.ververica.cdc.connectors.mongodb.source.reader.fetch.MongoDBScanFetchTask.execute(MongoDBScanFetchTask.java:120) at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceScanFetcher.lambda$submitTask$0(IncrementalSourceScanFetcher.java:94) ... 5 more |
mongo的cursor可以理解成为一个指针,使用这个指针可以访问mongo的文档,上面的报错的意思就是这个找不到这个指针
游标找不到的原因主要有2个:
- 客户端游标超时,被服务端回收,再用游标向服务器请求数据时就会出现游标找不到的情况。
- 在 mongo 集群环境下,可能会出现游标找不到的情况。游标由 mongo 服务器生成,在集群环境下,当使用 find() 相关函数时返回一个游标,假设此时该游标由 A 服务器生成,迭代完数据继续请求数据时,访问到了 B 服务器,但是该游标不是 B 生成的,此时就会出现游标找不到的情况。正常情况下,在 mongo 集群时,会将 mongo 地址以 ip1:port1,ip2:port2,ip3:port3 形式传给 mongo 驱动,然后驱动能够自动完成负载均衡和保持会话转发到同一台服务器,此时不会出现游标找不到的情况。但当我们自己搭建了负载均衡层,且用load balancer地址来连接时,就会出现游标找不到的情况。
游标找不到(仅考虑超时情况)的解决方案:
- 在服务端增大 mongo 服务器的游标超时时间。参数是 cursorTimeoutMillis,其默认是 10 min。修改后需重启 mongo 服务器。
- 在客户端一次性获取到全部符合条件的数据。也即将batch_size设置为很大的数,但次数若真的有很多数据的话,则对系统内存要求较高,同时如果数据量过大或处理过程过慢依旧会出现游标超时的情况。所以batch_size的评估是一个技术活。
- 客户端设置游标永不超时:
- 这种方式的缺点是如果程序意外停止或异常,该游标永远不会被释放,除非重启 mongo,否则会一直占用系统资源,属于危险操作。经过咨询DBA,一般很少对游标的数量进行监控,一般是由其引起的连锁反应如CPU/内存过高才能引起关注,一般的处理方式也就是重启mongo服务器,这样影响就比较大了。
- 经过查询,在mongo 3.6版本后,客户端就算把游标设置为永不超时。服务端仍然会在闲置30分钟后将其kill掉,所以大量查询若超过30分钟的话需要手动执行下refreshsession来防止超时。但在3.6以下版本则会一直存在。mongo文档。
参考:springboot mongo查询游标(cursor)不存在错误
即在mongo-cdc connection的配置中将cursor batch size的参数batch.size调小,默认值为1024,可以尝试调成100
mongodb游标超时报错:com.mongodb.MongoCursorNotFoundException: Query failed with error code -5的四种处理方式
4.java.lang.ArrayIndexOutOfBoundsException: 1 at org.apache.hudi.index.bucket.BucketIdentifier.lambda2(BucketIdentifier.java:74)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | java.lang.ArrayIndexOutOfBoundsException: 1 at org.apache.hudi.index.bucket.BucketIdentifier.lambda$getHashKeysUsingIndexFields$2(BucketIdentifier.java:74) at java.util.stream.Collectors.lambda$toMap$58(Collectors.java:1321) at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:482) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:566) at org.apache.hudi.index.bucket.BucketIdentifier.getHashKeysUsingIndexFields(BucketIdentifier.java:74) at org.apache.hudi.index.bucket.BucketIdentifier.getHashKeys(BucketIdentifier.java:63) at org.apache.hudi.index.bucket.BucketIdentifier.getHashKeys(BucketIdentifier.java:58) at org.apache.hudi.index.bucket.BucketIdentifier.getBucketId(BucketIdentifier.java:42) at org.apache.hudi.sink.partitioner.BucketIndexPartitioner.partition(BucketIndexPartitioner.java:44) at org.apache.hudi.sink.partitioner.BucketIndexPartitioner.partition(BucketIndexPartitioner.java:32) at org.apache.flink.streaming.runtime.partitioner.CustomPartitionerWrapper.selectChannel(CustomPartitionerWrapper.java:57) at org.apache.flink.streaming.runtime.partitioner.CustomPartitionerWrapper.selectChannel(CustomPartitionerWrapper.java:36) at org.apache.flink.runtime.io.network.api.writer.ChannelSelectorRecordWriter.emit(ChannelSelectorRecordWriter.java:54) at org.apache.flink.streaming.runtime.io.RecordWriterOutput.pushToRecordWriter(RecordWriterOutput.java:104) at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:90) at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:44) at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56) at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29) at org.apache.flink.streaming.api.operators.StreamMap.processElement(StreamMap.java:38) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:82) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:57) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:29) at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56) at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29) at org.apache.flink.table.runtime.util.StreamRecordCollector.collect(StreamRecordCollector.java:44) at org.apache.flink.table.runtime.operators.sink.ConstraintEnforcer.processElement(ConstraintEnforcer.java:247) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:82) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:57) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:29) at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56) at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29) at org.apache.flink.streaming.api.operators.TimestampedCollector.collect(TimestampedCollector.java:51) at org.apache.flink.table.runtime.operators.deduplicate.DeduplicateFunctionHelper.processLastRowOnChangelog(DeduplicateFunctionHelper.java:112) at org.apache.flink.table.runtime.operators.deduplicate.ProcTimeDeduplicateKeepLastRowFunction.processElement(ProcTimeDeduplicateKeepLastRowFunction.java:80) at org.apache.flink.table.runtime.operators.deduplicate.ProcTimeDeduplicateKeepLastRowFunction.processElement(ProcTimeDeduplicateKeepLastRowFunction.java:32) at org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:233) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:519) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:804) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:753) at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:948) at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:927) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:741) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563) at java.lang.Thread.run(Thread.java:750) |
这是由于指定的hudi recorder key中有一些异常的数据导致的,比如这里指定的recorder key是_id,这个字段是个string类型的,但是会有少部分数据是json string,其中value包含的逗号会导致split后出现array越界的情况
5.Caused by: java.lang.NoSuchMethodError: org.apache.hudi.org.apache.avro.specific.SpecificRecordBuilderBase.<init>(Lorg/apache/hudi/org/apache/avro/Schema;Lorg/apache/hudi/org/apache/avro/specific/SpecificData;)V
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | org.apache.flink.util.FlinkException: Global failure triggered by OperatorCoordinator for 'bucket_write: hudi_test' (operator b1cd777bdf9179b3493b6420d82b014a). at org.apache.flink.runtime.operators.coordination.OperatorCoordinatorHolder$LazyInitializedCoordinatorContext.failJob(OperatorCoordinatorHolder.java:556) at org.apache.hudi.sink.StreamWriteOperatorCoordinator.lambda$start$0(StreamWriteOperatorCoordinator.java:187) at org.apache.hudi.sink.utils.NonThrownExecutor.handleException(NonThrownExecutor.java:146) at org.apache.hudi.sink.utils.NonThrownExecutor.lambda$wrapAction$0(NonThrownExecutor.java:133) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:750)Caused by: org.apache.hudi.exception.HoodieException: Executor executes action [commits the instant 20230525063249024] error ... 6 moreCaused by: java.lang.NoSuchMethodError: org.apache.hudi.org.apache.avro.specific.SpecificRecordBuilderBase.<init>(Lorg/apache/hudi/org/apache/avro/Schema;Lorg/apache/hudi/org/apache/avro/specific/SpecificData;)V at org.apache.hudi.avro.model.HoodieCompactionPlan$Builder.<init>(HoodieCompactionPlan.java:226) at org.apache.hudi.avro.model.HoodieCompactionPlan$Builder.<init>(HoodieCompactionPlan.java:217) at org.apache.hudi.avro.model.HoodieCompactionPlan.newBuilder(HoodieCompactionPlan.java:184) at org.apache.hudi.table.action.compact.strategy.CompactionStrategy.generateCompactionPlan(CompactionStrategy.java:76) at org.apache.hudi.table.action.compact.HoodieCompactor.generateCompactionPlan(HoodieCompactor.java:317) at org.apache.hudi.table.action.compact.ScheduleCompactionActionExecutor.scheduleCompaction(ScheduleCompactionActionExecutor.java:123) at org.apache.hudi.table.action.compact.ScheduleCompactionActionExecutor.execute(ScheduleCompactionActionExecutor.java:93) at org.apache.hudi.table.HoodieFlinkMergeOnReadTable.scheduleCompaction(HoodieFlinkMergeOnReadTable.java:112) at org.apache.hudi.client.BaseHoodieWriteClient.scheduleTableServiceInternal(BaseHoodieWriteClient.java:1349) at org.apache.hudi.client.BaseHoodieWriteClient.scheduleTableService(BaseHoodieWriteClient.java:1326) at org.apache.hudi.client.BaseHoodieWriteClient.scheduleCompactionAtInstant(BaseHoodieWriteClient.java:1005) at org.apache.hudi.client.BaseHoodieWriteClient.scheduleCompaction(BaseHoodieWriteClient.java:996) at org.apache.hudi.util.CompactionUtil.scheduleCompaction(CompactionUtil.java:65) at org.apache.hudi.sink.StreamWriteOperatorCoordinator.lambda$notifyCheckpointComplete$2(StreamWriteOperatorCoordinator.java:246) at org.apache.hudi.sink.utils.NonThrownExecutor.lambda$wrapAction$0(NonThrownExecutor.java:130) ... 3 more |
这个问题网上有人讨论过,原因是flink 1.15.x版本使用的avro版本是1.8.2,而hudi-flink and hudi-flink-bundle使用的avro版本是1.10.0,上面报错中的找不到的方法需要在avro 1.10.0及以上版本中出现
参考:https://github.com/apache/hudi/issues/7259
这个报错将会导致flink任务失败,而且hive表无法同步
6.java.lang.OutOfMemoryError: Java heap space
这是问题发生的原因是flink的heap内存不足,可能的原因是:
1.没有使用rocksdb状态后端
默认的backend是MemoryStateBackend。默认情况下,flink的状态会保存在taskmanager的内存中,而checkpoint会保存在jobManager的内存中。
参考:Flink状态后端配置(设置State Backend)
不过在使用flink streaming job中,使用rocksdb backend可能会使用一点managed memory(属于堆外内存)
官方作者也推荐使用rocksdb作为状态后端

参考:Flink CDC MongoDB Connector 的实现原理和使用实践
2.使用了默认的FLINK STATE index type
由于FLINK STATE index type是in-memory的,都有可能导致flink任务的堆内存爆掉,解决方法是使用BUCKET index type
7.Caused by: org.apache.flink.util.SerializedThrowable: java.lang.OutOfMemoryError: Direct buffer memory
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 | org.apache.flink.util.SerializedThrowable: Asynchronous task checkpoint failed. at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.handleExecutionException(AsyncCheckpointRunnable.java:320) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.run(AsyncCheckpointRunnable.java:155) ~[flink-dist-1.15.2.jar:1.15.2] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_372] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_372] at java.lang.Thread.run(Thread.java:750) [?:1.8.0_372]Caused by: org.apache.flink.util.SerializedThrowable: Could not materialize checkpoint 114 for operator Source: mongo_cdc_test[1] -> Calc[2] (1/10)#0. at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.handleExecutionException(AsyncCheckpointRunnable.java:298) ~[flink-dist-1.15.2.jar:1.15.2] ... 4 moreCaused by: org.apache.flink.util.SerializedThrowable: java.lang.OutOfMemoryError: Direct buffer memory at java.util.concurrent.FutureTask.report(FutureTask.java:122) ~[?:1.8.0_372] at java.util.concurrent.FutureTask.get(FutureTask.java:192) ~[?:1.8.0_372] at org.apache.flink.util.concurrent.FutureUtils.runIfNotDoneAndGet(FutureUtils.java:645) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.api.operators.OperatorSnapshotFinalizer.<init>(OperatorSnapshotFinalizer.java:60) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.finalizeNonFinishedSnapshots(AsyncCheckpointRunnable.java:191) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.run(AsyncCheckpointRunnable.java:124) ~[flink-dist-1.15.2.jar:1.15.2] ... 3 moreCaused by: org.apache.flink.util.SerializedThrowable: Direct buffer memory at java.nio.Bits.reserveMemory(Bits.java:695) ~[?:1.8.0_372] at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123) ~[?:1.8.0_372] at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311) ~[?:1.8.0_372] at sun.nio.ch.Util.getTemporaryDirectBuffer(Util.java:247) ~[?:1.8.0_372] at sun.nio.ch.IOUtil.write(IOUtil.java:58) ~[?:1.8.0_372] at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:211) ~[?:1.8.0_372] at java.nio.channels.Channels.writeFullyImpl(Channels.java:78) ~[?:1.8.0_372] at java.nio.channels.Channels.writeFully(Channels.java:101) ~[?:1.8.0_372] at java.nio.channels.Channels.access$000(Channels.java:61) ~[?:1.8.0_372] at java.nio.channels.Channels$1.write(Channels.java:174) ~[?:1.8.0_372] at java.io.BufferedOutputStream.write(BufferedOutputStream.java:122) ~[?:1.8.0_372] at java.security.DigestOutputStream.write(DigestOutputStream.java:145) ~[?:1.8.0_372] at com.amazon.ws.emr.hadoop.fs.s3n.MultipartUploadOutputStream.write(MultipartUploadOutputStream.java:172) ~[emrfs-hadoop-assembly-2.54.0.jar:?] at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.write(FSDataOutputStream.java:63) ~[hadoop-common-3.3.3-amzn-1.jar:?] at java.io.DataOutputStream.write(DataOutputStream.java:107) ~[?:1.8.0_372] at org.apache.flink.runtime.fs.hdfs.HadoopDataOutputStream.write(HadoopDataOutputStream.java:47) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.core.fs.FSDataOutputStreamWrapper.write(FSDataOutputStreamWrapper.java:65) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.filesystem.FsCheckpointStreamFactory$FsCheckpointStateOutputStream.write(FsCheckpointStreamFactory.java:296) ~[flink-dist-1.15.2.jar:1.15.2] at java.io.DataOutputStream.write(DataOutputStream.java:107) ~[?:1.8.0_372] at java.io.FilterOutputStream.write(FilterOutputStream.java:97) ~[?:1.8.0_372] at org.apache.flink.api.common.typeutils.base.array.BytePrimitiveArraySerializer.serialize(BytePrimitiveArraySerializer.java:75) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.api.common.typeutils.base.array.BytePrimitiveArraySerializer.serialize(BytePrimitiveArraySerializer.java:31) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.PartitionableListState.write(PartitionableListState.java:117) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.DefaultOperatorStateBackendSnapshotStrategy.lambda$asyncSnapshot$1(DefaultOperatorStateBackendSnapshotStrategy.java:165) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.SnapshotStrategyRunner$1.callInternal(SnapshotStrategyRunner.java:91) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.SnapshotStrategyRunner$1.callInternal(SnapshotStrategyRunner.java:88) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.AsyncSnapshotCallable.call(AsyncSnapshotCallable.java:78) ~[flink-dist-1.15.2.jar:1.15.2] at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_372] at org.apache.flink.util.concurrent.FutureUtils.runIfNotDoneAndGet(FutureUtils.java:642) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.api.operators.OperatorSnapshotFinalizer.<init>(OperatorSnapshotFinalizer.java:60) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.finalizeNonFinishedSnapshots(AsyncCheckpointRunnable.java:191) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.run(AsyncCheckpointRunnable.java:124) ~[flink-dist-1.15.2.jar:1.15.2] ... 3 more2023-05-28 17:48:00,588 WARN org.apache.flink.runtime.checkpoint.CheckpointFailureManager [] - Failed to trigger or complete checkpoint 114 for job 9635c4bd284c99b94a979bd50b5fd3bb. (0 consecutive failed attempts so far)org.apache.flink.runtime.checkpoint.CheckpointException: Asynchronous task checkpoint failed. at org.apache.flink.runtime.messages.checkpoint.SerializedCheckpointException.unwrap(SerializedCheckpointException.java:51) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.receiveDeclineMessage(CheckpointCoordinator.java:1013) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.scheduler.ExecutionGraphHandler.lambda$declineCheckpoint$2(ExecutionGraphHandler.java:103) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.scheduler.ExecutionGraphHandler.lambda$processCheckpointCoordinatorMessage$3(ExecutionGraphHandler.java:119) ~[flink-dist-1.15.2.jar:1.15.2] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_372] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_372] at java.lang.Thread.run(Thread.java:750) [?:1.8.0_372]Caused by: org.apache.flink.util.SerializedThrowable: Asynchronous task checkpoint failed. at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.handleExecutionException(AsyncCheckpointRunnable.java:320) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.run(AsyncCheckpointRunnable.java:155) ~[flink-dist-1.15.2.jar:1.15.2] ... 3 moreCaused by: org.apache.flink.util.SerializedThrowable: Could not materialize checkpoint 114 for operator Source: mongo_cdc_test[1] -> Calc[2] (1/10)#0. at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.handleExecutionException(AsyncCheckpointRunnable.java:298) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.run(AsyncCheckpointRunnable.java:155) ~[flink-dist-1.15.2.jar:1.15.2] ... 3 moreCaused by: org.apache.flink.util.SerializedThrowable: java.lang.OutOfMemoryError: Direct buffer memory at java.util.concurrent.FutureTask.report(FutureTask.java:122) ~[?:1.8.0_372] at java.util.concurrent.FutureTask.get(FutureTask.java:192) ~[?:1.8.0_372] at org.apache.flink.util.concurrent.FutureUtils.runIfNotDoneAndGet(FutureUtils.java:645) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.api.operators.OperatorSnapshotFinalizer.<init>(OperatorSnapshotFinalizer.java:60) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.finalizeNonFinishedSnapshots(AsyncCheckpointRunnable.java:191) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.run(AsyncCheckpointRunnable.java:124) ~[flink-dist-1.15.2.jar:1.15.2] ... 3 moreCaused by: org.apache.flink.util.SerializedThrowable: Direct buffer memory at java.nio.Bits.reserveMemory(Bits.java:695) ~[?:1.8.0_372] at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123) ~[?:1.8.0_372] at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311) ~[?:1.8.0_372] at sun.nio.ch.Util.getTemporaryDirectBuffer(Util.java:247) ~[?:1.8.0_372] at sun.nio.ch.IOUtil.write(IOUtil.java:58) ~[?:1.8.0_372] at sun.nio.ch.FileChannelImpl.write(FileChannelImpl.java:211) ~[?:1.8.0_372] at java.nio.channels.Channels.writeFullyImpl(Channels.java:78) ~[?:1.8.0_372] at java.nio.channels.Channels.writeFully(Channels.java:101) ~[?:1.8.0_372] at java.nio.channels.Channels.access$000(Channels.java:61) ~[?:1.8.0_372] at java.nio.channels.Channels$1.write(Channels.java:174) ~[?:1.8.0_372] at java.io.BufferedOutputStream.write(BufferedOutputStream.java:122) ~[?:1.8.0_372] at java.security.DigestOutputStream.write(DigestOutputStream.java:145) ~[?:1.8.0_372] at com.amazon.ws.emr.hadoop.fs.s3n.MultipartUploadOutputStream.write(MultipartUploadOutputStream.java:172) ~[emrfs-hadoop-assembly-2.54.0.jar:?] at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.write(FSDataOutputStream.java:63) ~[hadoop-common-3.3.3-amzn-1.jar:?] at java.io.DataOutputStream.write(DataOutputStream.java:107) ~[?:1.8.0_372] at org.apache.flink.runtime.fs.hdfs.HadoopDataOutputStream.write(HadoopDataOutputStream.java:47) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.core.fs.FSDataOutputStreamWrapper.write(FSDataOutputStreamWrapper.java:65) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.filesystem.FsCheckpointStreamFactory$FsCheckpointStateOutputStream.write(FsCheckpointStreamFactory.java:296) ~[flink-dist-1.15.2.jar:1.15.2] at java.io.DataOutputStream.write(DataOutputStream.java:107) ~[?:1.8.0_372] at java.io.FilterOutputStream.write(FilterOutputStream.java:97) ~[?:1.8.0_372] at org.apache.flink.api.common.typeutils.base.array.BytePrimitiveArraySerializer.serialize(BytePrimitiveArraySerializer.java:75) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.api.common.typeutils.base.array.BytePrimitiveArraySerializer.serialize(BytePrimitiveArraySerializer.java:31) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.PartitionableListState.write(PartitionableListState.java:117) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.DefaultOperatorStateBackendSnapshotStrategy.lambda$asyncSnapshot$1(DefaultOperatorStateBackendSnapshotStrategy.java:165) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.SnapshotStrategyRunner$1.callInternal(SnapshotStrategyRunner.java:91) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.SnapshotStrategyRunner$1.callInternal(SnapshotStrategyRunner.java:88) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.state.AsyncSnapshotCallable.call(AsyncSnapshotCallable.java:78) ~[flink-dist-1.15.2.jar:1.15.2] at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_372] at org.apache.flink.util.concurrent.FutureUtils.runIfNotDoneAndGet(FutureUtils.java:642) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.api.operators.OperatorSnapshotFinalizer.<init>(OperatorSnapshotFinalizer.java:60) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.finalizeNonFinishedSnapshots(AsyncCheckpointRunnable.java:191) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.tasks.AsyncCheckpointRunnable.run(AsyncCheckpointRunnable.java:124) ~[flink-dist-1.15.2.jar:1.15.2] ... 3 more2023-05-28 17:48:00,591 INFO org.apache.flink.runtime.jobmaster.JobMaster [] - Trying to recover from a global failure.org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint tolerable failure threshold. at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.checkFailureAgainstCounter(CheckpointFailureManager.java:206) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleTaskLevelCheckpointException(CheckpointFailureManager.java:191) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleCheckpointException(CheckpointFailureManager.java:124) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:2082) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.receiveDeclineMessage(CheckpointCoordinator.java:1039) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.scheduler.ExecutionGraphHandler.lambda$declineCheckpoint$2(ExecutionGraphHandler.java:103) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.scheduler.ExecutionGraphHandler.lambda$processCheckpointCoordinatorMessage$3(ExecutionGraphHandler.java:119) ~[flink-dist-1.15.2.jar:1.15.2] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_372] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_372] at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_372] |
这是flink job manager或者task manager的堆外内存不足,其中的可能性是:
1.flink job manager的堆外内存过小,默认是128 MB,参考
1 | https://nightlies.apache.org/flink/flink-docs-master/docs/deployment/config/#jobmanager-memory-off-heap-size |
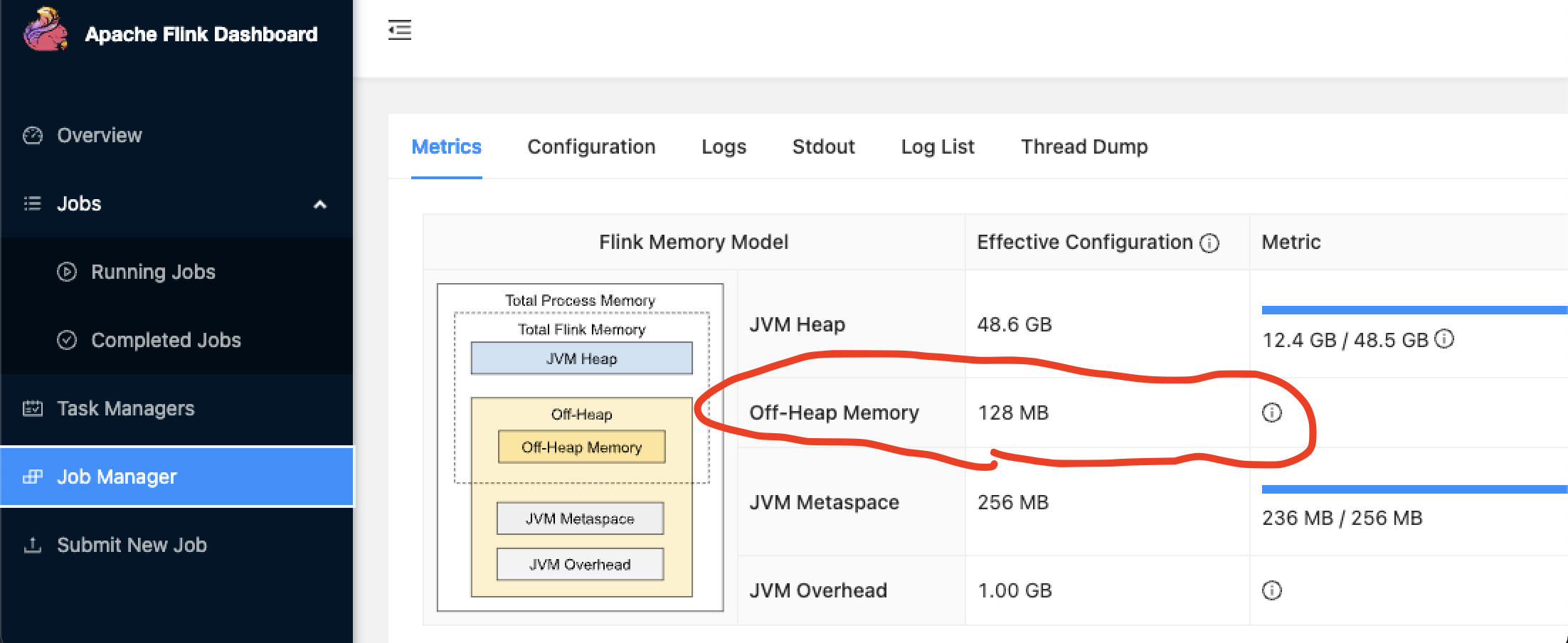
可以使用 -D jobmanager.memory.off-heap.size=1024m 手动指定大小,比如
1 | /usr/lib/flink/bin/yarn-session.sh -s 1 -jm 51200 -tm 51200 -qu data -D jobmanager.memory.off-heap.size=1024m --detached |
参考
1 | https://nightlies.apache.org/flink/flink-docs-master/docs/deployment/memory/mem_setup_jobmanager/ |
2.flink task manager的堆外内存过小,在使用task executor的时候其默认是0,即不使用堆外内存,参考
1 | https://nightlies.apache.org/flink/flink-docs-master/docs/deployment/config/#taskmanager-memory-task-off-heap-size |
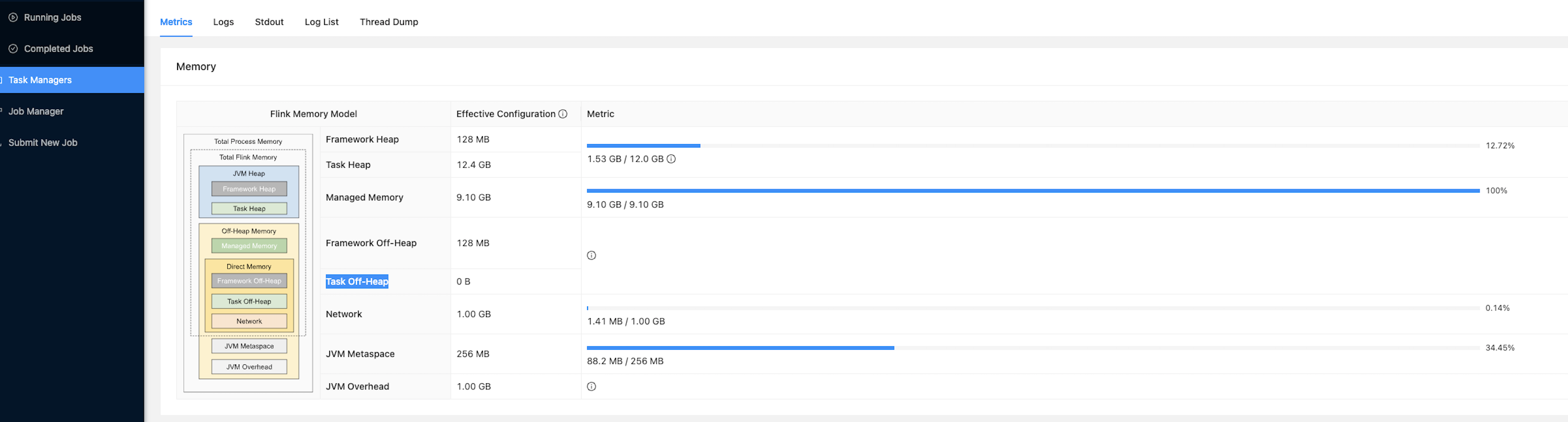
可以使用 -D taskmanager.memory.task.off-heap.size=4g手动指定大小,比如
1 | /usr/lib/flink/bin/yarn-session.sh -s 1 -jm 51200 -tm 51200 -qu data -D taskmanager.memory.task.off-heap.size=4G --detached |
参考
1 | https://nightlies.apache.org/flink/flink-docs-master/docs/deployment/memory/mem_setup_tm/#configure-off-heap-memory-direct-or-native |
如果是 compaction 阶段发生内存溢出,还会导致 compaction 一直卡住 INFLIGHT 状态,这时需要查看日志排查是否是内存爆掉了

如果 compacion 阶段发生内存溢出导致compaction失败,会使得flink任务重启,hudi会对失败的compaction阶段生成的部分parquet文件进行清理,对应的就在文件目录下可以发现时间戳在失败的compaction instant之后的parquet文件会被清理掉
一个compaction未完成的时候,即使合并出部分parquet文件,使用hive来查询的时候,这部分新的parquet是不会被查询到的
此外hudi写parquet文件的时候,是需要消耗一定的堆外内存的,参考:调优 | Apache Hudi应用调优指南
8.Caused by: com.mongodb.MongoQueryException: Query failed with error code 286 and error message 'Error on remote shard 172.31.xx.xx:27017 :: caused by :: Resume of change stream was not possible, as the resume point may no longer be in the oplog.' on server xxxx:27017
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | java.lang.RuntimeException: One or more fetchers have encountered exception at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager.checkErrors(SplitFetcherManager.java:225) at org.apache.flink.connector.base.source.reader.SourceReaderBase.getNextFetch(SourceReaderBase.java:169) at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:130) at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:385) at org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:519) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:804) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:753) at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:948) at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:927) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:741) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563) at java.lang.Thread.run(Thread.java:750)Caused by: java.lang.RuntimeException: SplitFetcher thread 0 received unexpected exception while polling the records at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:150) at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.run(SplitFetcher.java:105) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 moreCaused by: org.apache.flink.util.FlinkRuntimeException: Read split StreamSplit{splitId='stream-split', offset={resumeToken={"_data": "826472E86F0000000A2B022C0100296E5A1004B807779924DA402AB13486B3F67B6102463C5F6964003C306D5A776877724A000004"}, timestamp=7238103114576822282}, endOffset={resumeToken=null, timestamp=9223372034707292159}} error due to Query failed with error code 286 and error message 'Error on remote shard 172.31.xx.xx:27017 :: caused by :: Resume of change stream was not possible, as the resume point may no longer be in the oplog.' on server xxxx:27017. at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceStreamFetcher.checkReadException(IncrementalSourceStreamFetcher.java:124) at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceStreamFetcher.pollSplitRecords(IncrementalSourceStreamFetcher.java:106) at com.ververica.cdc.connectors.base.source.reader.IncrementalSourceSplitReader.fetch(IncrementalSourceSplitReader.java:73) at org.apache.flink.connector.base.source.reader.fetcher.FetchTask.run(FetchTask.java:58) at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:142) ... 6 moreCaused by: com.mongodb.MongoQueryException: Query failed with error code 286 and error message 'Error on remote shard 172.31.xx.xx:27017 :: caused by :: Resume of change stream was not possible, as the resume point may no longer be in the oplog.' on server xxxx:27017 at com.mongodb.internal.operation.QueryHelper.translateCommandException(QueryHelper.java:29) at com.mongodb.internal.operation.QueryBatchCursor.lambda$getMore$1(QueryBatchCursor.java:282) at com.mongodb.internal.operation.QueryBatchCursor$ResourceManager.executeWithConnection(QueryBatchCursor.java:512) at com.mongodb.internal.operation.QueryBatchCursor.getMore(QueryBatchCursor.java:270) at com.mongodb.internal.operation.QueryBatchCursor.tryHasNext(QueryBatchCursor.java:223) at com.mongodb.internal.operation.QueryBatchCursor.lambda$tryNext$0(QueryBatchCursor.java:206) at com.mongodb.internal.operation.QueryBatchCursor$ResourceManager.execute(QueryBatchCursor.java:397) at com.mongodb.internal.operation.QueryBatchCursor.tryNext(QueryBatchCursor.java:205) at com.mongodb.internal.operation.ChangeStreamBatchCursor$3.apply(ChangeStreamBatchCursor.java:102) at com.mongodb.internal.operation.ChangeStreamBatchCursor$3.apply(ChangeStreamBatchCursor.java:98) at com.mongodb.internal.operation.ChangeStreamBatchCursor.resumeableOperation(ChangeStreamBatchCursor.java:195) at com.mongodb.internal.operation.ChangeStreamBatchCursor.tryNext(ChangeStreamBatchCursor.java:98) at com.mongodb.client.internal.MongoChangeStreamCursorImpl.tryNext(MongoChangeStreamCursorImpl.java:78) at com.ververica.cdc.connectors.mongodb.source.reader.fetch.MongoDBStreamFetchTask.execute(MongoDBStreamFetchTask.java:116) at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceStreamFetcher.lambda$submitTask$0(IncrementalSourceStreamFetcher.java:86) ... 5 more |
同时使用 timeline show incomplete 命令查看未完成的timeline,会发现有 deltacommit 一直卡在 INFLIGHT 状态,说明拉取增量数据出现了问题
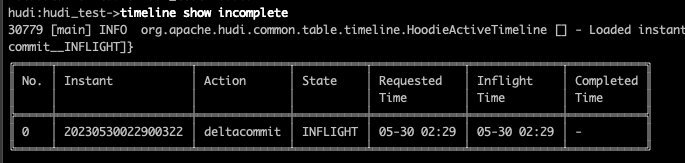
这个原因可能是oplog过期被清理掉了,这时候只能重头开始进行snapshot,之后可以调大oplog的保存大小或者时间
9.unable to convert to rowtype from unexpected value 'bsonarray{values=[]}' of type array
这是由于mongo是无强数据类型的,所以在实际Flink Mongo CDC的使用中,有时就会出现数据类型对不上的时候,比如mongo中一个字段,应该是一个array,但是实际上却出现了json类型,这时候就会出现以上报错
解决方法是对 flink-connector-mongodb-cdc 项目中的 MongoDBConnectorDeserializationSchema 代码进行修改,对数据类型对不上时候的报错进行捕获,直接填充字符串NULL,这和MapReduce dump Mongodb时候的对于字段类型无法对上的处理方法是一致的
10.java.util.concurrent.TimeoutException: Heartbeat of TaskManager with id container_1685522036674_0015_01_000014(ip-172-31-xxx-xx.us.compute.internal:8041) timed out.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | java.util.concurrent.TimeoutException: Heartbeat of TaskManager with id container_1685522036674_0015_01_000014(ip-172-31-xxx-xx.us.compute.internal:8041) timed out. at org.apache.flink.runtime.jobmaster.JobMaster$TaskManagerHeartbeatListener.notifyHeartbeatTimeout(JobMaster.java:1371) at org.apache.flink.runtime.heartbeat.HeartbeatMonitorImpl.run(HeartbeatMonitorImpl.java:155) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRunAsync$4(AkkaRpcActor.java:443) at org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:443) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:213) at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:78) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:163) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20) at scala.PartialFunction.applyOrElse(PartialFunction.scala:123) at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122) at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172) at akka.actor.Actor.aroundReceive(Actor.scala:537) at akka.actor.Actor.aroundReceive$(Actor.scala:535) at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:580) at akka.actor.ActorCell.invoke(ActorCell.scala:548) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270) at akka.dispatch.Mailbox.run(Mailbox.scala:231) at akka.dispatch.Mailbox.exec(Mailbox.scala:243) at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056) at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692) at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175) |
这个报错问题是由于task manager所在机器内存被占满等机器层面的问题,排查方法同下面第10条
11.Caused by: java.util.concurrent.TimeoutException: Invocation of [RemoteRpcInvocation(TaskExecutorGateway.sendOperatorEventToTask(ExecutionAttemptID, OperatorID, SerializedValue))] at recipient [akka.tcp://flink@ip-172-31-xxx-xx.us-.compute.internal:33139/user/rpc/taskmanager_0] timed out
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | org.apache.flink.util.FlinkException: An OperatorEvent from an OperatorCoordinator to a task was lost. Triggering task failover to ensure consistency. Event: 'SourceEventWrapper[com.ververica.cdc.connectors.base.source.meta.events.FinishedSnapshotSplitsRequestEvent@19b057ed]', targetTask: Source: mongo_cdc_test[1] -> Calc[2] (6/60) - execution #1 at org.apache.flink.runtime.operators.coordination.SubtaskGatewayImpl.lambda$null$0(SubtaskGatewayImpl.java:90) at org.apache.flink.runtime.util.Runnables.lambda$withUncaughtExceptionHandler$0(Runnables.java:49) at org.apache.flink.runtime.util.Runnables.assertNoException(Runnables.java:33) at org.apache.flink.runtime.operators.coordination.SubtaskGatewayImpl.lambda$sendEvent$1(SubtaskGatewayImpl.java:88) at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774) at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750) at java.util.concurrent.CompletableFuture$Completion.run(CompletableFuture.java:456) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRunAsync$4(AkkaRpcActor.java:443) at org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:443) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:213) at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:78) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:163) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20) at scala.PartialFunction.applyOrElse(PartialFunction.scala:123) at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122) at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172) at akka.actor.Actor.aroundReceive(Actor.scala:537) at akka.actor.Actor.aroundReceive$(Actor.scala:535) at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:580) at akka.actor.ActorCell.invoke(ActorCell.scala:548) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270) at akka.dispatch.Mailbox.run(Mailbox.scala:231) at akka.dispatch.Mailbox.exec(Mailbox.scala:243) at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056) at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692) at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:175)Caused by: java.util.concurrent.TimeoutException: Invocation of [RemoteRpcInvocation(TaskExecutorGateway.sendOperatorEventToTask(ExecutionAttemptID, OperatorID, SerializedValue))] at recipient [akka.tcp://flink@ip-172-31-xxx-xx.us-.compute.internal:33139/user/rpc/taskmanager_0] timed out. This is usually caused by: 1) Akka failed sending the message silently, due to problems like oversized payload or serialization failures. In that case, you should find detailed error information in the logs. 2) The recipient needs more time for responding, due to problems like slow machines or network jitters. In that case, you can try to increase akka.ask.timeout. at org.apache.flink.runtime.jobmaster.RpcTaskManagerGateway.sendOperatorEventToTask(RpcTaskManagerGateway.java:127) at org.apache.flink.runtime.executiongraph.Execution.sendOperatorEvent(Execution.java:874) at org.apache.flink.runtime.operators.coordination.ExecutionSubtaskAccess.lambda$createEventSendAction$1(ExecutionSubtaskAccess.java:67) at org.apache.flink.runtime.operators.coordination.OperatorEventValve.callSendAction(OperatorEventValve.java:180) at org.apache.flink.runtime.operators.coordination.OperatorEventValve.sendEvent(OperatorEventValve.java:94) at org.apache.flink.runtime.operators.coordination.SubtaskGatewayImpl.lambda$sendEvent$2(SubtaskGatewayImpl.java:98) ... 26 moreCaused by: akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka.tcp://flink@ip-172-31-xxx-xx.us-.compute.internal:33139/user/rpc/taskmanager_0#-116058576]] after [10000 ms]. Message of type [org.apache.flink.runtime.rpc.messages.RemoteRpcInvocation]. A typical reason for `AskTimeoutException` is that the recipient actor didn't send a reply. |
这需要去job manager报错日志里面的ip对应的task manager上查看具体日志,排查下来发现是访问s3时候有问题导致的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 | 2023-05-30 10:18:59,460 ERROR org.apache.hudi.sink.compact.CompactFunction [] - Executor executes action [Execute compaction for instant 20230530095353629 from task 1] errororg.apache.hudi.exception.HoodieIOException: Could not check if s3a://xxxx/hudi_test35 is a valid table at org.apache.hudi.exception.TableNotFoundException.checkTableValidity(TableNotFoundException.java:59) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.common.table.HoodieTableMetaClient.<init>(HoodieTableMetaClient.java:128) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.common.table.HoodieTableMetaClient.newMetaClient(HoodieTableMetaClient.java:642) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.common.table.HoodieTableMetaClient.access$000(HoodieTableMetaClient.java:80) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.common.table.HoodieTableMetaClient$Builder.build(HoodieTableMetaClient.java:711) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.table.HoodieFlinkTable.create(HoodieFlinkTable.java:59) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.client.HoodieFlinkWriteClient.getHoodieTable(HoodieFlinkWriteClient.java:607) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.sink.compact.CompactFunction.reloadWriteConfig(CompactFunction.java:125) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.sink.compact.CompactFunction.lambda$processElement$0(CompactFunction.java:95) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.sink.utils.NonThrownExecutor.lambda$wrapAction$0(NonThrownExecutor.java:130) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_372] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_372] at java.lang.Thread.run(Thread.java:750) [?:1.8.0_372]Caused by: org.apache.hadoop.fs.s3a.AWSClientIOException: getFileStatus on s3a://xxxx/hudi_test35/.hoodie: com.amazonaws.SdkClientException: Unable to unmarshall response (Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'.). Response Code: 200, Response Text: OK: Unable to unmarshall response (Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'.). Response Code: 200, Response Text: OK at org.apache.hadoop.fs.s3a.S3AUtils.translateException(S3AUtils.java:214) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AUtils.translateException(S3AUtils.java:175) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.s3GetFileStatus(S3AFileSystem.java:3861) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.innerGetFileStatus(S3AFileSystem.java:3688) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.lambda$getFileStatus$24(S3AFileSystem.java:3556) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.statistics.impl.IOStatisticsBinding.lambda$trackDurationOfOperation$5(IOStatisticsBinding.java:499) ~[hadoop-common-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.statistics.impl.IOStatisticsBinding.trackDuration(IOStatisticsBinding.java:444) ~[hadoop-common-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.trackDurationAndSpan(S3AFileSystem.java:2337) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.trackDurationAndSpan(S3AFileSystem.java:2356) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.getFileStatus(S3AFileSystem.java:3554) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hudi.common.fs.HoodieWrapperFileSystem.lambda$getFileStatus$17(HoodieWrapperFileSystem.java:402) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.common.fs.HoodieWrapperFileSystem.executeFuncWithTimeMetrics(HoodieWrapperFileSystem.java:106) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.common.fs.HoodieWrapperFileSystem.getFileStatus(HoodieWrapperFileSystem.java:396) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.exception.TableNotFoundException.checkTableValidity(TableNotFoundException.java:51) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] ... 12 moreCaused by: com.amazonaws.SdkClientException: Unable to unmarshall response (Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'.). Response Code: 200, Response Text: OK at com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleResponse(AmazonHttpClient.java:1818) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleSuccessResponse(AmazonHttpClient.java:1477) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeOneRequest(AmazonHttpClient.java:1384) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeHelper(AmazonHttpClient.java:1157) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:814) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeWithTimer(AmazonHttpClient.java:781) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.execute(AmazonHttpClient.java:755) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.access$500(AmazonHttpClient.java:715) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutionBuilderImpl.execute(AmazonHttpClient.java:697) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:561) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:541) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5456) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5403) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5397) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.AmazonS3Client.listObjectsV2(AmazonS3Client.java:971) ~[aws-java-sdk-bundle-1.12.331.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.lambda$listObjects$11(S3AFileSystem.java:2595) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.statistics.impl.IOStatisticsBinding.lambda$trackDurationOfOperation$5(IOStatisticsBinding.java:499) ~[hadoop-common-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.Invoker.retryUntranslated(Invoker.java:414) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.Invoker.retryUntranslated(Invoker.java:377) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.listObjects(S3AFileSystem.java:2586) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.s3GetFileStatus(S3AFileSystem.java:3832) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.innerGetFileStatus(S3AFileSystem.java:3688) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.lambda$getFileStatus$24(S3AFileSystem.java:3556) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.statistics.impl.IOStatisticsBinding.lambda$trackDurationOfOperation$5(IOStatisticsBinding.java:499) ~[hadoop-common-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.statistics.impl.IOStatisticsBinding.trackDuration(IOStatisticsBinding.java:444) ~[hadoop-common-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.trackDurationAndSpan(S3AFileSystem.java:2337) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.trackDurationAndSpan(S3AFileSystem.java:2356) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.getFileStatus(S3AFileSystem.java:3554) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hudi.common.fs.HoodieWrapperFileSystem.lambda$getFileStatus$17(HoodieWrapperFileSystem.java:402) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.common.fs.HoodieWrapperFileSystem.executeFuncWithTimeMetrics(HoodieWrapperFileSystem.java:106) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.common.fs.HoodieWrapperFileSystem.getFileStatus(HoodieWrapperFileSystem.java:396) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.exception.TableNotFoundException.checkTableValidity(TableNotFoundException.java:51) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] ... 12 moreCaused by: java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration 'classloader.check-leaked-classloader'. at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.ensureInner(FlinkUserCodeClassLoaders.java:164) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.loadClass(FlinkUserCodeClassLoaders.java:172) ~[flink-dist-1.15.2.jar:1.15.2] at org.xml.sax.helpers.NewInstance.newInstance(NewInstance.java:82) ~[?:1.8.0_372] at org.xml.sax.helpers.XMLReaderFactory.loadClass(XMLReaderFactory.java:228) ~[?:1.8.0_372] at org.xml.sax.helpers.XMLReaderFactory.createXMLReader(XMLReaderFactory.java:191) ~[?:1.8.0_372] at com.amazonaws.services.s3.model.transform.XmlResponsesSaxParser.<init>(XmlResponsesSaxParser.java:135) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.model.transform.Unmarshallers$ListObjectsV2Unmarshaller.unmarshall(Unmarshallers.java:135) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.model.transform.Unmarshallers$ListObjectsV2Unmarshaller.unmarshall(Unmarshallers.java:125) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.internal.S3XmlResponseHandler.handle(S3XmlResponseHandler.java:62) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.internal.S3XmlResponseHandler.handle(S3XmlResponseHandler.java:31) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.response.AwsResponseHandlerAdapter.handle(AwsResponseHandlerAdapter.java:69) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleResponse(AmazonHttpClient.java:1794) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleSuccessResponse(AmazonHttpClient.java:1477) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeOneRequest(AmazonHttpClient.java:1384) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeHelper(AmazonHttpClient.java:1157) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:814) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeWithTimer(AmazonHttpClient.java:781) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.execute(AmazonHttpClient.java:755) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutor.access$500(AmazonHttpClient.java:715) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient$RequestExecutionBuilderImpl.execute(AmazonHttpClient.java:697) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:561) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:541) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5456) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5403) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5397) ~[aws-java-sdk-bundle-1.12.331.jar:?] at com.amazonaws.services.s3.AmazonS3Client.listObjectsV2(AmazonS3Client.java:971) ~[aws-java-sdk-bundle-1.12.331.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.lambda$listObjects$11(S3AFileSystem.java:2595) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.statistics.impl.IOStatisticsBinding.lambda$trackDurationOfOperation$5(IOStatisticsBinding.java:499) ~[hadoop-common-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.Invoker.retryUntranslated(Invoker.java:414) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.Invoker.retryUntranslated(Invoker.java:377) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.listObjects(S3AFileSystem.java:2586) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.s3GetFileStatus(S3AFileSystem.java:3832) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.innerGetFileStatus(S3AFileSystem.java:3688) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.lambda$getFileStatus$24(S3AFileSystem.java:3556) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.statistics.impl.IOStatisticsBinding.lambda$trackDurationOfOperation$5(IOStatisticsBinding.java:499) ~[hadoop-common-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.statistics.impl.IOStatisticsBinding.trackDuration(IOStatisticsBinding.java:444) ~[hadoop-common-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.trackDurationAndSpan(S3AFileSystem.java:2337) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.trackDurationAndSpan(S3AFileSystem.java:2356) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hadoop.fs.s3a.S3AFileSystem.getFileStatus(S3AFileSystem.java:3554) ~[hadoop-aws-3.3.3-amzn-1.jar:?] at org.apache.hudi.common.fs.HoodieWrapperFileSystem.lambda$getFileStatus$17(HoodieWrapperFileSystem.java:402) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.common.fs.HoodieWrapperFileSystem.executeFuncWithTimeMetrics(HoodieWrapperFileSystem.java:106) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.common.fs.HoodieWrapperFileSystem.getFileStatus(HoodieWrapperFileSystem.java:396) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.exception.TableNotFoundException.checkTableValidity(TableNotFoundException.java:51) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] ... 12 more2023-05-30 10:18:59,461 ERROR org.apache.flink.runtime.util.ClusterUncaughtExceptionHandler [] - WARNING: Thread 'pool-17-thread-2' produced an uncaught exception. If you want to fail on uncaught exceptions, then configure cluster.uncaught-exception-handling accordinglyorg.apache.flink.runtime.execution.CancelTaskException: Buffer pool has already been destroyed. at org.apache.flink.runtime.io.network.buffer.LocalBufferPool.checkDestroyed(LocalBufferPool.java:404) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.io.network.buffer.LocalBufferPool.requestMemorySegment(LocalBufferPool.java:373) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.io.network.buffer.LocalBufferPool.requestBufferBuilder(LocalBufferPool.java:316) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.requestNewBufferBuilderFromPool(BufferWritingResultPartition.java:394) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.requestNewUnicastBufferBuilder(BufferWritingResultPartition.java:377) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.appendUnicastDataForNewRecord(BufferWritingResultPartition.java:281) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.io.network.partition.BufferWritingResultPartition.emitRecord(BufferWritingResultPartition.java:157) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.io.network.api.writer.RecordWriter.emit(RecordWriter.java:106) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.io.network.api.writer.ChannelSelectorRecordWriter.emit(ChannelSelectorRecordWriter.java:54) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.io.RecordWriterOutput.pushToRecordWriter(RecordWriterOutput.java:104) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:90) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.runtime.io.RecordWriterOutput.collect(RecordWriterOutput.java:44) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:56) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.api.operators.CountingOutput.collect(CountingOutput.java:29) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.streaming.api.operators.TimestampedCollector.collect(TimestampedCollector.java:51) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.hudi.sink.compact.CompactFunction.lambda$processElement$1(CompactFunction.java:96) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.sink.utils.NonThrownExecutor.handleException(NonThrownExecutor.java:146) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at org.apache.hudi.sink.utils.NonThrownExecutor.lambda$wrapAction$0(NonThrownExecutor.java:133) ~[hudi-flink1.15-bundle-0.12.1.jar:0.12.1] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_372] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_372] at java.lang.Thread.run(Thread.java:750) [?:1.8.0_372] |
12.org.apache.flink.runtime.io.network.netty.exception.RemoteTransportException: Connection unexpectedly closed by remote task manager 'ip-172-31-xxx-xx.us.compute.internal/172.31.xxx.xx:39597'. This might indicate that the remote task manager was lost.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | org.apache.flink.runtime.io.network.netty.exception.RemoteTransportException: Connection unexpectedly closed by remote task manager 'ip-172-31-xxx-xx.us.compute.internal/172.31.xxx.xx:39597'. This might indicate that the remote task manager was lost. at org.apache.flink.runtime.io.network.netty.CreditBasedPartitionRequestClientHandler.channelInactive(CreditBasedPartitionRequestClientHandler.java:127) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelInactive(AbstractChannelHandlerContext.java:262) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelInactive(AbstractChannelHandlerContext.java:248) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.fireChannelInactive(AbstractChannelHandlerContext.java:241) at org.apache.flink.shaded.netty4.io.netty.channel.ChannelInboundHandlerAdapter.channelInactive(ChannelInboundHandlerAdapter.java:81) at org.apache.flink.runtime.io.network.netty.NettyMessageClientDecoderDelegate.channelInactive(NettyMessageClientDecoderDelegate.java:94) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelInactive(AbstractChannelHandlerContext.java:262) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelInactive(AbstractChannelHandlerContext.java:248) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.fireChannelInactive(AbstractChannelHandlerContext.java:241) at org.apache.flink.shaded.netty4.io.netty.channel.DefaultChannelPipeline$HeadContext.channelInactive(DefaultChannelPipeline.java:1405) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelInactive(AbstractChannelHandlerContext.java:262) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannelHandlerContext.invokeChannelInactive(AbstractChannelHandlerContext.java:248) at org.apache.flink.shaded.netty4.io.netty.channel.DefaultChannelPipeline.fireChannelInactive(DefaultChannelPipeline.java:901) at org.apache.flink.shaded.netty4.io.netty.channel.AbstractChannel$AbstractUnsafe$8.run(AbstractChannel.java:831) at org.apache.flink.shaded.netty4.io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:164) at org.apache.flink.shaded.netty4.io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:469) at org.apache.flink.shaded.netty4.io.netty.channel.epoll.EpollEventLoop.run(EpollEventLoop.java:384) at org.apache.flink.shaded.netty4.io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:986) at org.apache.flink.shaded.netty4.io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) at java.lang.Thread.run(Thread.java:750) |
这种报错通常发生在机器出现内存不足等问题的时候
去对应ip的task manager上查看日志,日志最后显示这个task manager当时正在加载checkpoint
1 2 3 | 2023-05-31 03:19:00,920 INFO com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem [] - Opening 's3://xxx/hudi_test_checkpoint/131ca6b0b81354dfb130360ccf9e9d30/shared/a5edc84c-840c-4ccd-8038-7da256d08cbd' for reading2023-05-31 03:19:03,369 INFO com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem [] - Opening 's3://xxx/hudi_test_checkpoint/131ca6b0b81354dfb130360ccf9e9d30/chk-125/9d7e2217-10e5-436d-b678-6ca27ea1c6a0' for reading2023-05-31 03:19:03,424 INFO com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem [] - Opening 's3://xxx/hudi_test_checkpoint/131ca6b0b81354dfb130360ccf9e9d30/shared/ad969d73-a803-4e82-b4fa-38a57469d48a' for reading |
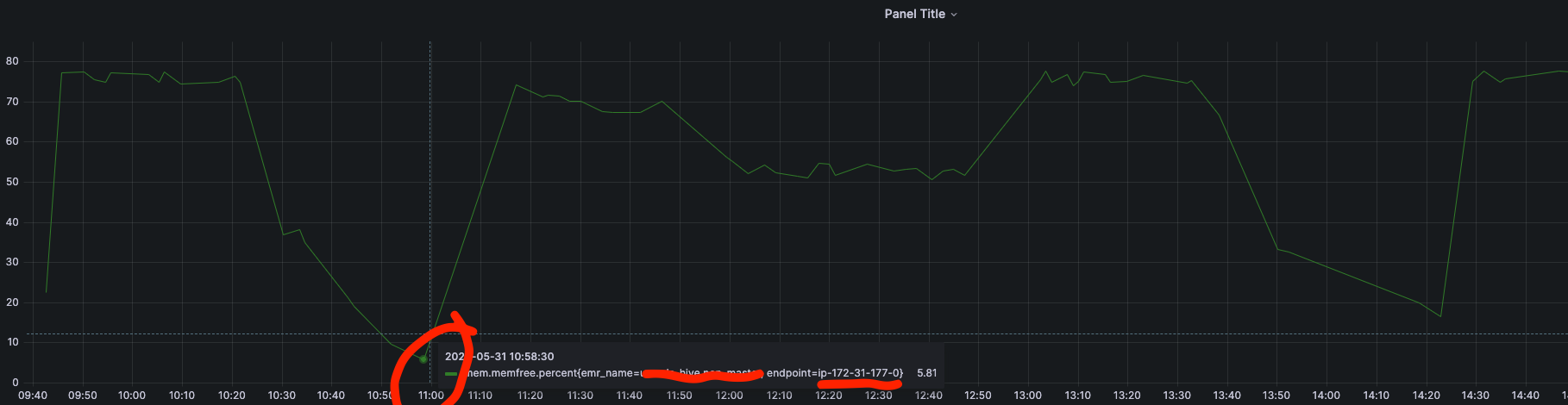
对比报错发生的时间点和当时机器的内存监控指标
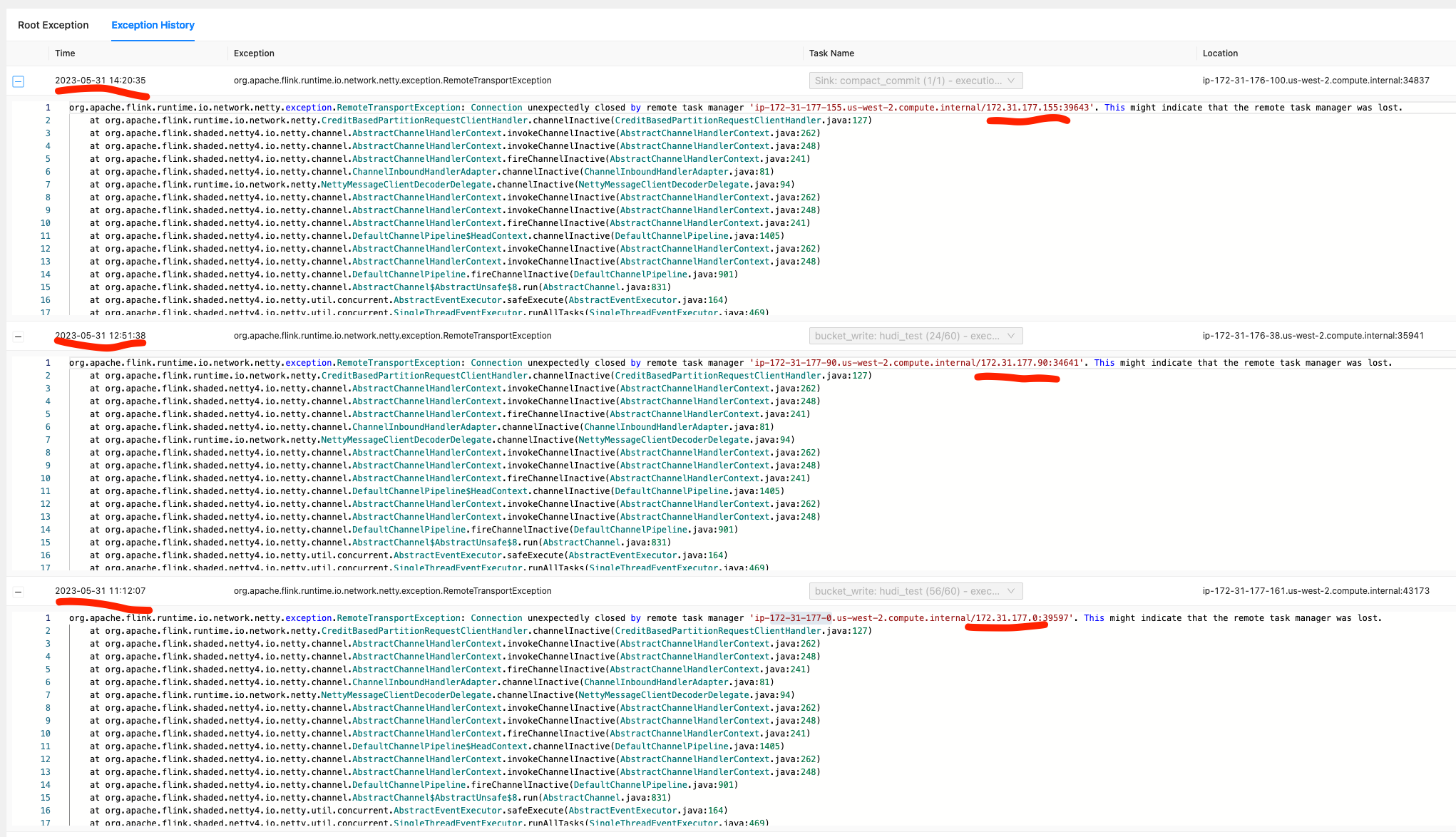
发现报错的时候对应ip机器的内存都几乎满了

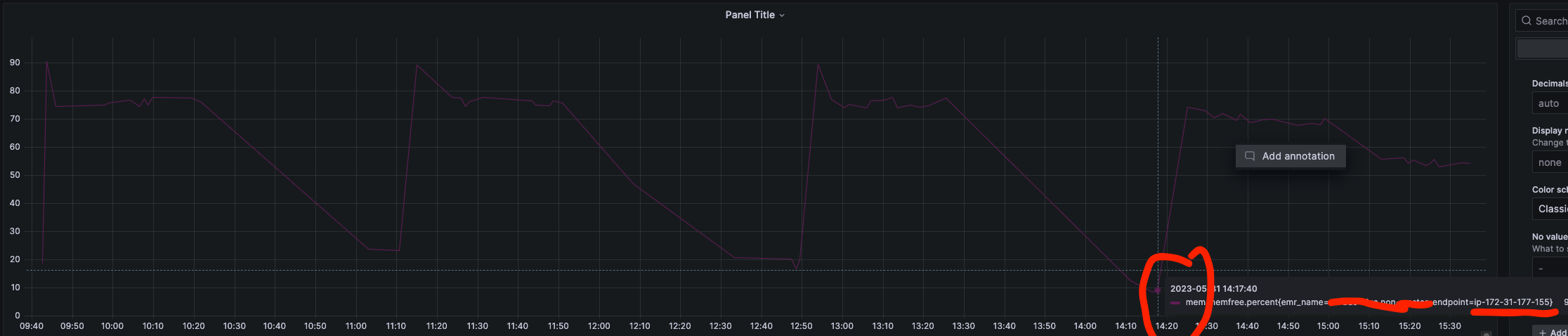
13.Caused by: com.mongodb.MongoCommandException: Command failed with error 13 (Unauthorized): ‘not authorized on admin to execute command { aggregate: 1, pipeline: [ { db: “admin”, $clusterTime: { clusterTime: Timestamp(1680783775, 2), signature: { hash: BinData(0, 898FE82BE1837F4BDBDA1A12CC1D5F765527A25C), keyId: 7175829065197158402 } }, lsid: { id: UUID(“9d99adfc-cc35-4619-b5c5-7ad71ec77df1”) } }’ on server xxxx:27017
这是由于使用的mongo账号没有admin库的读取权限导致的,需要添加一下权限,参考:https://ververica.github.io/flink-cdc-connectors/release-2.3/content/connectors/mongodb-cdc.html?highlight=mongo#setup-mongodb
1 2 3 4 5 6 7 8 | Caused by: org.apache.flink.util.FlinkRuntimeException: Read split SnapshotSplit{tableId=xxx.xxx, splitId=‘xxx.xxx:224’, splitKeyType=[`_id` INT], splitStart=[{“_id”: 1.0}, {“_id”: “xxxx”}], splitEnd=[{“_id”: 1.0}, {“_id”: “xxxx"}], highWatermark=null} error due to Command failed with error 13 (Unauthorized): ‘not authorized on admin to execute command { aggregate: 1, pipeline: [ { $changeStream: { allChangesForCluster: true } } ], cursor: { batchSize: 1 }, $db: “admin”, $clusterTime: { clusterTime: Timestamp(1680783775, 2), signature: { hash: BinData(0, 898FE82BE1837F4BDBDA1A12CC1D5F765527A25C), keyId: 7175829065197158402 } }, lsid: { id: UUID(“9d99adfc-cc35-4619-b5c5-7ad71ec77df1") } }’ on server xxxx:27017. The full response is {“ok”: 0.0, “errmsg”: “not authorized on admin to execute command { aggregate: 1, pipeline: [ { $changeStream: { allChangesForCluster: true } } ], cursor: { batchSize: 1 }, $db: \“admin\“, $clusterTime: { clusterTime: Timestamp(1680783775, 2), signature: { }}}. at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceScanFetcher.checkReadException(IncrementalSourceScanFetcher.java:181) at com.ververica.cdc.connectors.base.source.reader.external.IncrementalSourceScanFetcher.pollSplitRecords(IncrementalSourceScanFetcher.java:128) at com.ververica.cdc.connectors.base.source.reader.IncrementalSourceSplitReader.fetch(IncrementalSourceSplitReader.java:73) at org.apache.flink.connector.base.source.reader.fetcher.FetchTask.run(FetchTask.java:58) at org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher.runOnce(SplitFetcher.java:142) ... 6 moreCaused by: com.mongodb.MongoCommandException: Command failed with error 13 (Unauthorized): ‘not authorized on admin to execute command { aggregate: 1, pipeline: [ { $changeStream: { allChangesForCluster: true } } ], cursor: { batchSize: 1 }, $db: “admin”, $clusterTime: { clusterTime: Timestamp(1680783775, 2), signature: { } }, lsid: { }’ on server xxxx:27017. The full response is {“ok”: 0.0, “errmsg”: “not authorized on admin to execute command { aggregate: 1, pipeline: [ { $changeStream: { allChangesForCluster: true } } ], cursor: { batchSize: 1 }, $db: \“admin\“, $clusterTime: { clusterTime: Timestamp(1680783775, 2), signature: { }, lsid: { }“, “code”: 13, “codeName”: “Unauthorized”, “operationTime”: {“$timestamp”: {“t”: 1680783775, “i”: 2}}, “$clusterTime”: {“clusterTime”: {“$timestamp”: {“t”: 1680783775, “i”: 2}}, “signature”: {“hash”: {“$binary”: {“base64": ““, “subType”: “00"}}, “keyId”:xxx}}} |
14.Caused by: com.mongodb.MongoCommandException: Command failed with error 18 (AuthenticationFailed): 'Authentication failed.' on server xxx:27017.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | org.apache.flink.util.FlinkException: Global failure triggered by OperatorCoordinator for 'Source: mongo_cdc_test[1] -> Calc[2]' (operator cbc357ccb763df2852fee8c4fc7d55f2). at org.apache.flink.runtime.operators.coordination.OperatorCoordinatorHolder$LazyInitializedCoordinatorContext.failJob(OperatorCoordinatorHolder.java:556) at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator$QuiesceableContext.failJob(RecreateOnResetOperatorCoordinator.java:231) at org.apache.flink.runtime.source.coordinator.SourceCoordinatorContext.failJob(SourceCoordinatorContext.java:316) at org.apache.flink.runtime.source.coordinator.SourceCoordinator.start(SourceCoordinator.java:201) at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator$DeferrableCoordinator.resetAndStart(RecreateOnResetOperatorCoordinator.java:394) at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator.lambda$resetToCheckpoint$6(RecreateOnResetOperatorCoordinator.java:144) at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774) at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488) at java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975) at org.apache.flink.runtime.operators.coordination.ComponentClosingUtils.lambda$closeAsyncWithTimeout$0(ComponentClosingUtils.java:77) at java.lang.Thread.run(Thread.java:750)Caused by: org.apache.flink.util.FlinkRuntimeException: Failed to discover captured tables for enumerator at com.ververica.cdc.connectors.base.source.IncrementalSource.createEnumerator(IncrementalSource.java:151) at org.apache.flink.runtime.source.coordinator.SourceCoordinator.start(SourceCoordinator.java:197) ... 8 moreCaused by: com.mongodb.MongoSecurityException: Exception authenticating MongoCredential{mechanism=SCRAM-SHA-1, userName='xxxx', source='admin', password=<hidden>, mechanismProperties=<hidden>} at com.mongodb.internal.connection.SaslAuthenticator.wrapException(SaslAuthenticator.java:273) at com.mongodb.internal.connection.SaslAuthenticator.getNextSaslResponse(SaslAuthenticator.java:137) at com.mongodb.internal.connection.SaslAuthenticator.access$100(SaslAuthenticator.java:48) at com.mongodb.internal.connection.SaslAuthenticator$1.run(SaslAuthenticator.java:63) at com.mongodb.internal.connection.SaslAuthenticator$1.run(SaslAuthenticator.java:57) at com.mongodb.internal.connection.SaslAuthenticator.doAsSubject(SaslAuthenticator.java:280) at com.mongodb.internal.connection.SaslAuthenticator.authenticate(SaslAuthenticator.java:57) at com.mongodb.internal.connection.DefaultAuthenticator.authenticate(DefaultAuthenticator.java:55) at com.mongodb.internal.connection.InternalStreamConnectionInitializer.authenticate(InternalStreamConnectionInitializer.java:205) at com.mongodb.internal.connection.InternalStreamConnectionInitializer.finishHandshake(InternalStreamConnectionInitializer.java:79) at com.mongodb.internal.connection.InternalStreamConnection.open(InternalStreamConnection.java:170) at com.mongodb.internal.connection.UsageTrackingInternalConnection.open(UsageTrackingInternalConnection.java:53) at com.mongodb.internal.connection.DefaultConnectionPool$PooledConnection.open(DefaultConnectionPool.java:496) at com.mongodb.internal.connection.DefaultConnectionPool$OpenConcurrencyLimiter.openWithConcurrencyLimit(DefaultConnectionPool.java:865) at com.mongodb.internal.connection.DefaultConnectionPool$OpenConcurrencyLimiter.openOrGetAvailable(DefaultConnectionPool.java:806) at com.mongodb.internal.connection.DefaultConnectionPool.get(DefaultConnectionPool.java:155) at com.mongodb.internal.connection.DefaultConnectionPool.get(DefaultConnectionPool.java:145) at com.mongodb.internal.connection.DefaultServer.getConnection(DefaultServer.java:92) at com.mongodb.internal.binding.ClusterBinding$ClusterBindingConnectionSource.getConnection(ClusterBinding.java:141) at com.mongodb.client.internal.ClientSessionBinding$SessionBindingConnectionSource.getConnection(ClientSessionBinding.java:163) at com.mongodb.internal.operation.CommandOperationHelper.lambda$executeCommand$4(CommandOperationHelper.java:190) at com.mongodb.internal.operation.OperationHelper.withReadConnectionSource(OperationHelper.java:583) at com.mongodb.internal.operation.CommandOperationHelper.executeCommand(CommandOperationHelper.java:189) at com.mongodb.internal.operation.ListDatabasesOperation.execute(ListDatabasesOperation.java:201) at com.mongodb.internal.operation.ListDatabasesOperation.execute(ListDatabasesOperation.java:54) at com.mongodb.client.internal.MongoClientDelegate$DelegateOperationExecutor.execute(MongoClientDelegate.java:184) at com.mongodb.client.internal.MongoIterableImpl.execute(MongoIterableImpl.java:135) at com.mongodb.client.internal.MongoIterableImpl.iterator(MongoIterableImpl.java:92) at com.mongodb.client.internal.MongoIterableImpl.forEach(MongoIterableImpl.java:121) at com.mongodb.client.internal.MappingIterable.forEach(MappingIterable.java:59) at com.ververica.cdc.connectors.mongodb.source.utils.CollectionDiscoveryUtils.databaseNames(CollectionDiscoveryUtils.java:56) at com.ververica.cdc.connectors.mongodb.source.dialect.MongoDBDialect.lambda$discoverAndCacheDataCollections$0(MongoDBDialect.java:99) at java.util.concurrent.ConcurrentHashMap.computeIfAbsent(ConcurrentHashMap.java:1660) at com.ververica.cdc.connectors.mongodb.source.dialect.MongoDBDialect.discoverAndCacheDataCollections(MongoDBDialect.java:94) at com.ververica.cdc.connectors.mongodb.source.dialect.MongoDBDialect.discoverDataCollections(MongoDBDialect.java:75) at com.ververica.cdc.connectors.mongodb.source.dialect.MongoDBDialect.discoverDataCollections(MongoDBDialect.java:60) at com.ververica.cdc.connectors.base.source.IncrementalSource.createEnumerator(IncrementalSource.java:139) ... 9 moreCaused by: com.mongodb.MongoCommandException: Command failed with error 18 (AuthenticationFailed): 'Authentication failed.' on server xxx:27017. The full response is {"operationTime": {"$timestamp": {"t": 1686237336, "i": 24}}, "ok": 0.0, "errmsg": "Authentication failed.", "code": 18, "codeName": "AuthenticationFailed", "$clusterTime": {"clusterTime": {"$timestamp": {"t": 1686237336, "i": 24}}, "signature": {"hash": {"$binary": {"base64": "xjwzreIFobScDm4vZ2UH319Iklo=", "subType": "00"}}, "keyId": 7192072244963573763}}} at com.mongodb.internal.connection.ProtocolHelper.getCommandFailureException(ProtocolHelper.java:195) at com.mongodb.internal.connection.InternalStreamConnection.receiveCommandMessageResponse(InternalStreamConnection.java:400) at com.mongodb.internal.connection.InternalStreamConnection.sendAndReceive(InternalStreamConnection.java:324) at com.mongodb.internal.connection.CommandHelper.sendAndReceive(CommandHelper.java:88) at com.mongodb.internal.connection.CommandHelper.executeCommand(CommandHelper.java:36) at com.mongodb.internal.connection.SaslAuthenticator.sendSaslStart(SaslAuthenticator.java:228) at com.mongodb.internal.connection.SaslAuthenticator.getNextSaslResponse(SaslAuthenticator.java:135) |
这也是由于使用的mongo账号没有权限导致的,除了admin库的读取权限之外,还需要如下权限,参考:https://ververica.github.io/flink-cdc-connectors/release-2.3/content/connectors/mongodb-cdc.html?highlight=mongo#setup-mongodb
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | use admin;db.createRole( { role: "flinkrole", privileges: [{ // Grant privileges on all non-system collections in all databases resource: { db: "", collection: "" }, actions: [ "splitVector", "listDatabases", "listCollections", "collStats", "find", "changeStream" ] }], roles: [ // Read config.collections and config.chunks // for sharded cluster snapshot splitting. { role: 'read', db: 'config' } ] });db.createUser( { user: 'flinkuser', pwd: 'flinkpw', roles: [ { role: 'flinkrole', db: 'admin' } ] }); |
15.checkpoint超时
如果发现checkpoint间歇性失败,可以看一下是否是checkpoint超过默认10分钟的限制,对于大表,可能checkpoint会达到30分钟,可以通过以下方式调整checkpoint超时时间
1 2 | // checkpoint1小时超时env.getCheckpointConfig().setCheckpointTimeout(3600000); |

16.org.apache.flink.streaming.runtime.tasks.ExceptionInChainedOperatorException: Could not forward element to next operator
这是由于flink的tuple类型不支持包含null,比如["test1",null,"test2"],从而导致遍历数组的时候出现NullPointException
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | 2023-07-04 14:53:47java.lang.NullPointerException at org.apache.flink.table.runtime.typeutils.StringDataSerializer.copy(StringDataSerializer.java:56) at org.apache.flink.table.runtime.typeutils.StringDataSerializer.copy(StringDataSerializer.java:34) at org.apache.flink.table.runtime.typeutils.ArrayDataSerializer.copyGenericArray(ArrayDataSerializer.java:128) at org.apache.flink.table.runtime.typeutils.ArrayDataSerializer.copy(ArrayDataSerializer.java:86) at org.apache.flink.table.runtime.typeutils.ArrayDataSerializer.copy(ArrayDataSerializer.java:47) at org.apache.flink.table.runtime.typeutils.RowDataSerializer.copyRowData(RowDataSerializer.java:170) at org.apache.flink.table.runtime.typeutils.RowDataSerializer.copy(RowDataSerializer.java:131) at org.apache.flink.table.runtime.typeutils.RowDataSerializer.copy(RowDataSerializer.java:48) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:80) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:57) at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.collect(CopyingChainingOutput.java:29) at org.apache.flink.streaming.runtime.tasks.SourceOperatorStreamTask$AsyncDataOutputToOutput.emitRecord(SourceOperatorStreamTask.java:196) at org.apache.flink.streaming.api.operators.source.SourceOutputWithWatermarks.collect(SourceOutputWithWatermarks.java:110) at org.apache.flink.streaming.api.operators.source.SourceOutputWithWatermarks.collect(SourceOutputWithWatermarks.java:101) at com.ververica.cdc.connectors.base.source.reader.IncrementalSourceRecordEmitter$OutputCollector.collect(IncrementalSourceRecordEmitter.java:166) at com.ververica.cdc.connectors.mongodb.table.MongoDBConnectorDeserializationSchema.emit(MongoDBConnectorDeserializationSchema.java:216) at com.ververica.cdc.connectors.mongodb.table.MongoDBConnectorDeserializationSchema.deserialize(MongoDBConnectorDeserializationSchema.java:143) at com.ververica.cdc.connectors.base.source.reader.IncrementalSourceRecordEmitter.emitElement(IncrementalSourceRecordEmitter.java:141) at com.ververica.cdc.connectors.mongodb.source.reader.MongoDBRecordEmitter.processElement(MongoDBRecordEmitter.java:79) at com.ververica.cdc.connectors.base.source.reader.IncrementalSourceRecordEmitter.emitRecord(IncrementalSourceRecordEmitter.java:86) at com.ververica.cdc.connectors.base.source.reader.IncrementalSourceRecordEmitter.emitRecord(IncrementalSourceRecordEmitter.java:55) at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:143) at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:351) at org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:496) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:809) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:761) at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958) at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:937) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575) at java.lang.Thread.run(Thread.java:750) |
17.java.lang.NoClassDefFoundError: Could not initialize class com.ververica.cdc.connectors.mongodb.internal.MongoDBEnvelope
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | 2023-07-13 08:08:55,200 ERROR org.apache.flink.runtime.source.coordinator.SourceCoordinator [] - Failed to create Source Enumerator for source Source: mongo_cdc_test[1]java.lang.NoClassDefFoundError: Could not initialize class com.ververica.cdc.connectors.mongodb.internal.MongoDBEnvelope at com.ververica.cdc.connectors.mongodb.source.utils.MongoUtils.buildConnectionString(MongoUtils.java:373) ~[flink-sql-connector-mongodb-cdc-2.5-SNAPSHOT.jar:2.5-SNAPSHOT] at com.ververica.cdc.connectors.mongodb.source.config.MongoDBSourceConfig.<init>(MongoDBSourceConfig.java:79) ~[flink-sql-connector-mongodb-cdc-2.5-SNAPSHOT.jar:2.5-SNAPSHOT] at com.ververica.cdc.connectors.mongodb.source.config.MongoDBSourceConfigFactory.create(MongoDBSourceConfigFactory.java:253) ~[flink-sql-connector-mongodb-cdc-2.5-SNAPSHOT.jar:2.5-SNAPSHOT] at com.ververica.cdc.connectors.mongodb.source.config.MongoDBSourceConfigFactory.create(MongoDBSourceConfigFactory.java:41) ~[flink-sql-connector-mongodb-cdc-2.5-SNAPSHOT.jar:2.5-SNAPSHOT] at com.ververica.cdc.connectors.base.source.IncrementalSource.createEnumerator(IncrementalSource.java:134) ~[flink-sql-connector-mongodb-cdc-2.5-SNAPSHOT.jar:2.5-SNAPSHOT] at org.apache.flink.runtime.source.coordinator.SourceCoordinator.start(SourceCoordinator.java:197) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator$DeferrableCoordinator.resetAndStart(RecreateOnResetOperatorCoordinator.java:394) ~[flink-dist-1.15.2.jar:1.15.2] at org.apache.flink.runtime.operators.coordination.RecreateOnResetOperatorCoordinator.lambda$resetToCheckpoint$6(RecreateOnResetOperatorCoordinator.java:144) ~[flink-dist-1.15.2.jar:1.15.2] at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774) ~[?:1.8.0_372] at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750) ~[?:1.8.0_372] at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488) ~[?:1.8.0_372] at java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975) ~[?:1.8.0_372] at org.apache.flink.runtime.operators.coordination.ComponentClosingUtils.lambda$closeAsyncWithTimeout$0(ComponentClosingUtils.java:77) ~[flink-dist-1.15.2.jar:1.15.2] at java.lang.Thread.run(Thread.java:750) [?:1.8.0_372] |
该报错是由于没有按照flink cdc文档来使用jar导致的
在项目的pom.xml中使用的依赖应该如下
1 2 3 4 5 6 | <dependency> <groupId>com.ververica</groupId> <artifactId>flink-connector-mongodb-cdc</artifactId> <version>2.5-SNAPSHOT</version> <scope>provided</scope></dependency> |
在${FLINK_HOME}/lib目录下部署的jar应该如下
1 | flink-sql-connector-mongodb-cdc-2.5-SNAPSHOT.jar |
5.Mongo CDC业界使用案例
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/5517590.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)