
Hudi学习笔记——基本操作
1.Hudi概念
参考:
英文官方文档:https://hudi.apache.org/docs/concepts/
中文官方文档:https://hudi.apache.org/cn/docs/0.9.0/concepts/
1.Hudi表的存储类型
hudi表的类型有2种,分成cow和mor
cow是Copy On Write的缩写,含义是写入时复制(只有parquet文件)
mor是Merge On Read的缩写,含义是读取时合并(log文件+parquet文件)
2种hudi表类型的对比
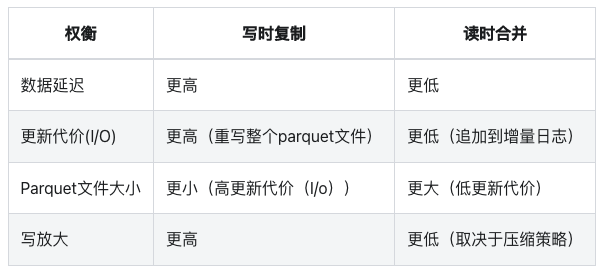
适用场景,参考:ByteLake:字节跳动基于Apache Hudi的实时数据湖平台
COW表适用于批量离线更新场景
MOR表适用于实时高频更新场景
1.写时复制
写时复制存储中的文件片仅包含基本/列文件,并且每次提交都会生成新版本的基本文件。 换句话说,我们压缩每个提交,从而所有的数据都是以列数据的形式储存。在这种情况下,写入数据非常昂贵(我们需要重写整个列数据文件,即使只有一个字节的新数据被提交),而读取数据的成本则没有增加。 这种视图有利于读取繁重的分析工作。
cow类型的hudi表文件目录如下,参考:https://jxeditor.github.io/2021/05/07/Hudi初探/#开始文件分析COW
.
├── .hoodie
│ ├── .aux
│ │ └── .bootstrap
│ │ ├── .fileids
│ │ └── .partitions
│ ├── .temp
│ ├── 20210511100234.commit
│ ├── 20210511100234.commit.requested
│ ├── 20210511100234.inflight
│ ├── 20210511100304.commit
│ ├── 20210511100304.commit.requested
│ ├── 20210511100304.inflight
│ ├── 20210511100402.commit
│ ├── 20210511100402.commit.requested
│ ├── 20210511100402.inflight
│ ├── 20210511100503.commit.requested
│ ├── 20210511100503.inflight
│ ├── archived
│ └── hoodie.properties
└── par1
├── .hoodie_partition_metadata
├── 48ca22d7-d503-4073-93ec-be7a33e6e8f4_0-1-0_20210511100234.parquet
├── 99aaf2d1-8e82-42d9-a982-65ed8d258f28_0-1-0_20210511100304.parquet
└── 99aaf2d1-8e82-42d9-a982-65ed8d258f28_0-1-0_20210511100402.parquet
使用写时复制的时候,对于update操作,当commit了之后,即使只是update了一行数据的一个字段,hudi会将这行数据所在的文件再copy一遍,然后加个这个更新之后,重新生成一个文件,所以在使用COW表的时候可能会产生写放大的问题,参考:Hudi COW表的数据膨胀(清除历史版本)问题
hudi对于历史数据的保留版本,由hoodie.cleaner.commits.retained参数来控制,默认是24
在查询COW表的时候,可以通过read.start-commit加上read.end-commit参数来按commit时间来控制查询范围,格式为yyyyMMddHHmmss,所有只使用一个参数的话,只有查询最新的一个commit,参考官方配置文档:https://hudi.apache.org/docs/configurations/
2.读时合并
读时合并存储是写时复制的升级版,从某种意义上说,它仍然可以通过读优化表提供数据集的读取优化视图(写时复制的功能)。 此外,它将每个文件组的更新插入存储到基于行的增量日志中,通过文件id,将增量日志和最新版本的基本文件进行合并,从而提供近实时的数据查询。因此,此存储类型智能地平衡了读和写的成本,以提供近乎实时的查询。 这里最重要的一点是压缩器,它现在可以仔细挑选需要压缩到其列式基础文件中的增量日志(根据增量日志的文件大小),以保持查询性能(较大的增量日志将会提升近实时的查询时间,并同时需要更长的合并时间)。
mor类型的hudi表文件目录如下,参考:https://jxeditor.github.io/2021/05/07/Hudi初探/#开始文件分析MOR
可以看到,采用读时合并的目录下除了.parquet文件,还有.log文件,其中.log文件采用的就是avro序列化格式,log文件格式结构可以参考:Hudi Log 文件格式与读写流程
.
├── .hoodie
│ ├── .aux
│ │ ├── .bootstrap
│ │ │ ├── .fileids
│ │ │ └── .partitions
│ │ ├── 20210510175131.compaction.requested
│ │ ├── 20210510181521.compaction.requested
│ │ ├── 20210510190422.compaction.requested
│ │ └── 20210511091552.compaction.requested
│ ├── .temp
│ │ ├── 20210510175131
│ │ │ └── par1
│ │ │ ├── 0a0110a8-b26b-4595-b5fb-b2388263ac54_0-1-0_20210510175131.parquet.marker.CREATE
│ │ │ ├── 39798d42-eb9f-46c7-aece-bdbe9fed3c45_0-1-0_20210510175131.parquet.marker.CREATE
│ │ │ └── 75dff8c0-614a-43e9-83c7-452dfa1dc797_0-1-0_20210510175131.parquet.marker.CREATE
│ │ ├── 20210510181521
│ │ │ └── par1
│ │ │ └── 39798d42-eb9f-46c7-aece-bdbe9fed3c45_0-1-0_20210510181521.parquet.marker.MERGE
│ │ └── 20210510190422
│ │ └── par1
│ │ └── 39798d42-eb9f-46c7-aece-bdbe9fed3c45_0-1-0_20210510190422.parquet.marker.MERGE
│ ├── 20210510174713.deltacommit
│ ├── 20210510174713.deltacommit.inflight
│ ├── 20210510174713.deltacommit.requested
......
│ ├── 20210510181212.rollback
│ ├── 20210510181212.rollback.inflight
......
│ ├── 20210510181521.commit
│ ├── 20210510181521.compaction.inflight
│ ├── 20210510181521.compaction.requested
......
│ ├── 20210511090334.clean
│ ├── 20210511090334.clean.inflight
│ ├── 20210511090334.clean.requested
......
│ ├── archived -- 归档目录,操作未达到默认值时,没有产生对应文件
│ └── hoodie.properties
└── par1
├── .39798d42-eb9f-46c7-aece-bdbe9fed3c45_20210510181521.log.1_0-1-0
├── .39798d42-eb9f-46c7-aece-bdbe9fed3c45_20210510190422.log.1_0-1-0
├── .39798d42-eb9f-46c7-aece-bdbe9fed3c45_20210511091552.log.1_0-1-2
├── .hoodie_partition_metadata
├── 0a0110a8-b26b-4595-b5fb-b2388263ac54_0-1-0_20210510175131.parquet
├── 39798d42-eb9f-46c7-aece-bdbe9fed3c45_0-1-0_20210510181521.parquet
├── 39798d42-eb9f-46c7-aece-bdbe9fed3c45_0-1-0_20210510190422.parquet
└── 75dff8c0-614a-43e9-83c7-452dfa1dc797_0-1-0_20210510175131.parquet
parquet文件什么时候合并由参数 compaction.delta_commits 和 compaction.delta_seconds控制,delta_commits其值为3的话表示,在3次commit之后,会compaction产生parquet文件
由于这里设置的commit时间是每5分钟一次,所以可以看到对于标红的log文件,第一次commit是08:46,第二次是08:51,第三次是08:56,之后产生parquet文件是09:02
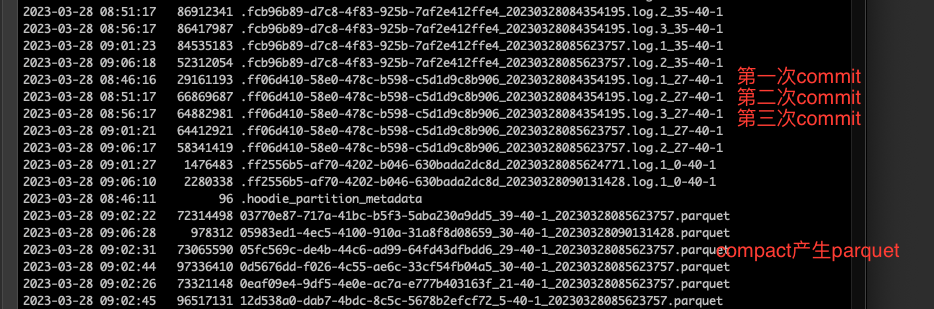
对于.hoodie下面的文件,20210510181521.compaction.requested 表示20210510181521的instant请求compaction,20210510181521.compaction.inflight 表示20210510181521的instant正在compaction,20210510181521.commit 表示20210510181521的instant compaction已经完成
2.Hudi的数据类型
https://hudi.apache.org/docs/next/table_management/#supported-types
3.Hudi Query的类型(视图)
Hudi query的类型有3种:Snapshot Queries,Incremental Queries和Read Optimized Queries
1.读优化视图(Snapshot Queries)
查询看到表的最新快照作为给定的提交或压缩操作。
在读取merge on read表的情况下,它通过即时合并最新文件切片的基础文件和增量文件来公开近实时数据(几分钟)。
对于copy on write表,它提供了对现有表的直接替换,同时提供更新插入/删除和其他写入端功能。
2.增量视图(Incremental Queries)
查询只能看到自给定提交/压缩以来写入表的新数据。这有效地提供了更改流以启用增量数据管道。
3.实时视图(Read Optimized Queries)
查询查看截至给定提交/压缩操作的表的最新快照。仅公开最新文件片中的基/列式文件,并保证与非 hudi 列式表相同的列式查询性能。
对于COW和MOR,所支持的query类型也不同,参考:
写时复制(copy on write)支持Snapshot Queries和Incremental Queries
读时合并(merge on read)支持Snapshot Queries,Incremental Queries和Read Optimized Queries
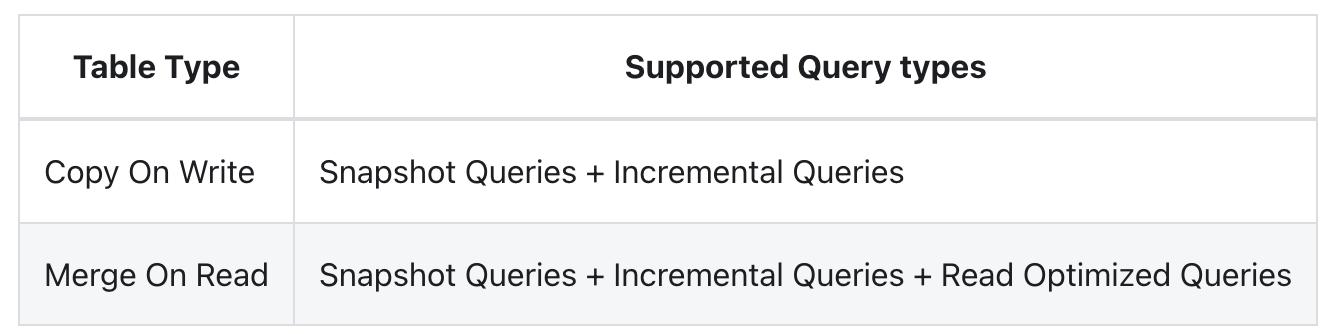
不同视图的对比:

4.Hudi的payload
目前提供的payload
https://github.com/apache/hudi/tree/master/hudi-common/src/main/java/org/apache/hudi/common/model
参考:超硬核解析!Apache Hudi灵活的Payload机制
5.Hudi的写入方式
1.insert
2.bulk_insert
3.upsert
4.delete
6.Hudi删除数据的方式
7.hudi和hive集成
8.Hudi问题集合
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/5285697.html

