ElasticSearch学习笔记——配置参数
集群参数
1.cluster.name 集群名称
也可以在注释后在es的启动命令添加 -Ecluster.name=XXX,默认为elasticsearch
节点参数
1.node.name 节点名称
也可以在注释后在es的启动命令添加 -Enode.name=XXX
2.node.name 节点角色
有如下参数:
node.master: false
node.data: true
node.ingest: false
node.ml: true
xpack.ml.enabled: true
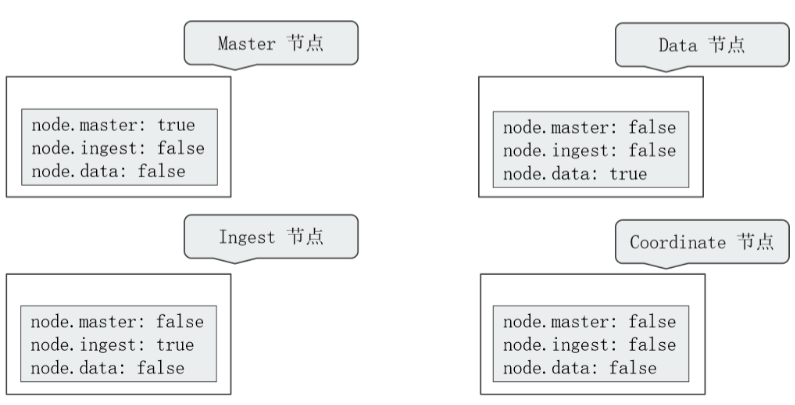
ElasticSearch node的角色可以分成5种:
1.Master eligible nodes:主节点:
负责集群状态(cluster state)的管理,使用低配置的 CPU,RAM 和磁盘
从高可用 & 避免脑裂的角色出发:一般在生产环境中配置 3 台;可以有多个master节点,但是同时只能有一个活跃的主节点,在cerebro上活跃的主节点会带有*号;负载分片管理,索引创建,集群管理等操作
如果和数据节点或者 Coordinate 节点混合部署:数据节点相对有比较大的内存占用;Coordinate 节点有时候可能会有开销很高的查询,导致 OOM;这些都有可能影响 Master 节点,导致集群的不稳定
2.Data Node:数据节点:
负责数据存储及处理客户端请求,使用高配置的 CPU,RAM 和磁盘
3.Coordinating Node:协调节点,也称为client节点:
生产环境中,建议为一些大的集群配置 Coordinating Only Nodes,Medium / High CPU; Medium / High RAM; Low Disk
扮演 Load Balancers。 降低 Master 和 Data Nodes 的负载
负载搜索结果的 Gather / Reduce
有时候无法预知客户端会发生怎样的请求
大量占用内存的结合操作,一个深度聚合可能引发 OOM
4.Ingest Node:ingest节点:
负责数据处理,使用高配置的 CPU ; 中等配置的 RAM; 低配置的磁盘
5.Machine learning:机器学习节点
2.node.attr 节点属性
Elasticsearch支持给节点打标签,具体方式是在elasticsearch.yml文件中增加
node.attr.{attribute}: {value}
比如用于进行节点的业务隔离或者冷热分离,business1,business2,hot,warm等等,也可以注释后在es的启动命令添加 -Enode.attr.box_type=$xxxx
也可以用于机架的隔离 node.attr.rack: r1
路径参数
1.path.data data路径
比如 path.data: /data01/xxx, /data02/xxx
也可以在启动命令中添加 -Epath.data=$datadir
2.path.logs log路径
比如path.logs: /data01/logs/xxx
也可以在启动命令中添加 -Epath.logs=$logdir
内存参数
1bootstrap.memory_lock
锁定jvm只用内存,不使用硬盘
网络参数
1.network.host 绑定监听IP
默认是注释的
如果不限制主机的访问和节点的交互(client节点需要这么配置),可以修改成0.0.0.0
如果发布给集群中其他节点知道的地址,可以修改成"_bond1:ipv4_"
2.http.port http端口
也可以在启动命令中添加 -Ehttp.port=$http_port;其他还有tcp的端口,比如 -Etransport.tcp.port=$tcp_port
3.http.enabled 是否为 Elasticsearch 服务启用 HTTP
如果是client节点的话,true,并且
http.cors.enabled: true
http.cors.allow-origin: "*"
如果是其他节点的话,false
3.其他http参数
发现机制参数
1.discovery.zen.ping.unicast.hosts 集群中其他节点ip:tcp端口,用来联系集群中其他节点,一般只用配置主节点地址即可
比如 discovery.zen.ping.unicast.hosts: ["host1:9300","host2:9300","host3:9300","host4:9300","host5:9300"]
2.discovery.zen.minimum_master_nodes 最小主节点数目,为了防止脑裂,需要设置发现超过半数的主节点候选者才能组成集群
比如节点的主节点数量为5,这里就是3;如果是3,那么就是2
线程池参数
1.thread_pool.bulk.queue_size
The queue_size allows to control the size of the queue of pending requests that have no threads to execute them. By default, it is set to -1 which means its unbounded. When a request comes in and the queue is full, it will abort the request.
比如设置成5000
参考:https://www.elastic.co/guide/en/elasticsearch/reference/master/modules-threadpool.html
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/5204087.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号