Python爬虫——使用selenium和chrome爬取js动态加载的网页
1.使用docker镜像运行selenium+chrome环境
官方镜像仓库selenium/standalone-chrome,只支持amd64
拉取镜像
docker pull selenium/standalone-chrome:120.0
启动
docker run -d -p 4444:4444 -p 15900:5900 selenium/standalone-chrome:120.0
其他参数
docker run -d -p 4444:4444 -p 15900:5900 -e SE_NODE_MAX_SESSIONS=5 --shm-size=2g selenium/standalone-chrome:120.0
参考:https://hub.docker.com/r/selenium/standalone-chrome
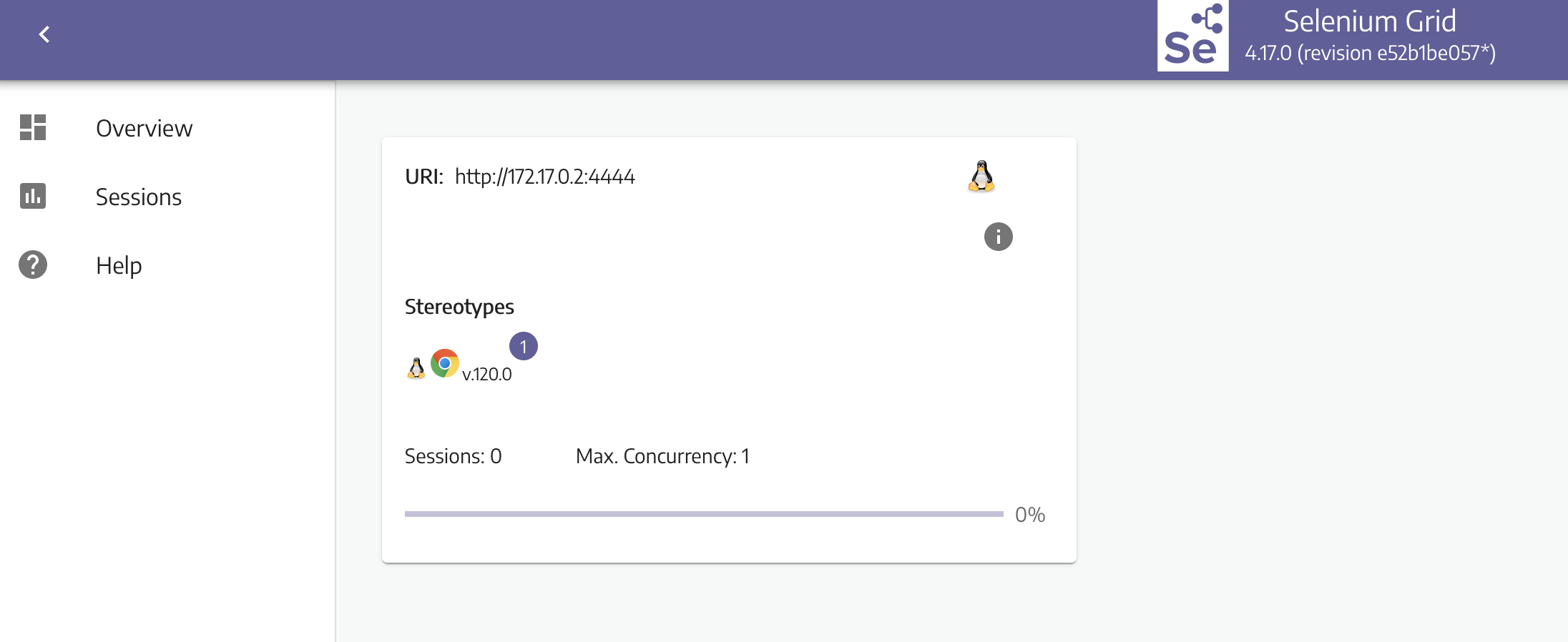
访问 localhost:4444/ui 可以查看selenium的运行状态
可以使用mac自带的屏幕共享功能连接pod的vnc
输入 vnc://localhost:15900,默认密码是secret
界面
2.安装依赖
ubuntu/debian换源
sudo -s sed -i s@/archive.ubuntu.com/@/mirrors.aliyun.com/@g /etc/apt/sources.list apt-get update
安装pip3
apt-get install python3-pip
安装selenium和webdriver-manager
pip3 install selenium pip3 install webdriver-manager
3.运行selenium
查看chrome和driver version
root@ced974ac3394:/# google-chrome --version
Google Chrome 120.0.6099.224
root@ced974ac3394:/# chromedriver --version
ChromeDriver 120.0.6099.109 (3419140ab665596f21b385ce136419fde0924272-refs/branch-heads/6099@{#1483})
1.不启用chrome gui
root@ced974ac3394:/# python3
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.get("https://python.org")
print(driver.title)
Welcome to Python.org
exit()
参考:https://github.com/password123456/setup-selenium-with-chrome-driver-on-ubuntu_debian
2.启用chrome gui
root@fce0fc2def31:/# python3
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
options = Options()
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--remote-debugging-port=9222") # 不加的话会报session not created: DevToolsActivePort file doesn't exist
options.add_argument('--no-sandbox') # 不加的话会报chrome not reachable
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
此时vnc界面会弹出浏览器
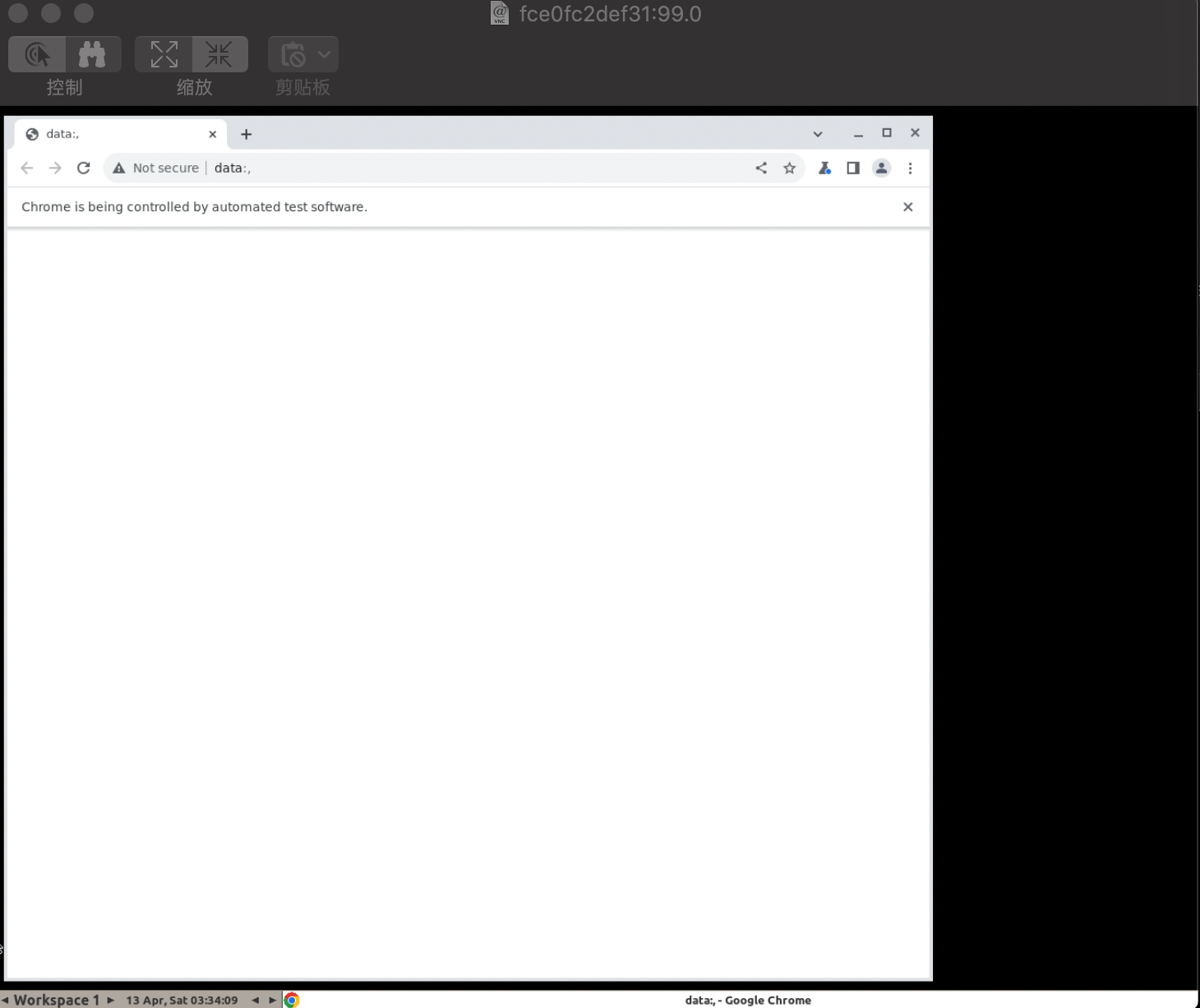
>>> driver.get("https://python.org")
>>> print(driver.title)
Welcome to Python.org
打开了python的网页

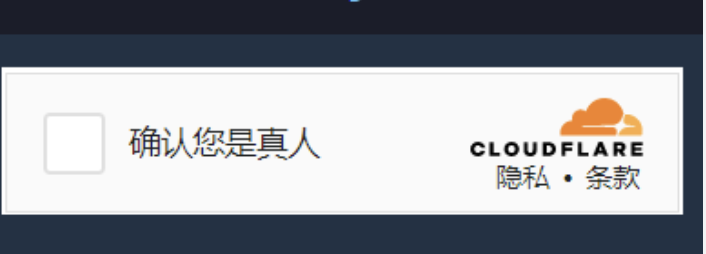
4.cloudflare人机校验
如果语言cloudflare的人机校验
1.可以尝试使用 undetected_chromedriver 这个包来代替selenium的webdriver
安装 undetected_chromedriver
pip3 install undetected_chromedriver
替换seleniuim的web driver
import undetected_chromedriver as uc
driver = uc.Chrome(headless=False,use_subprocess=False)
driver.maximize_window()
driver.get('https://nowsecure.nl')
driver.save_screenshot('nowsecure.png')
参考:https://github.com/ultrafunkamsterdam/undetected-chromedriver
如果报from session not created: This version of ChromeDriver only supports Chrome version 125
可以在代码中指定chrome的版本,如下
undetecteddriver = uc.Chrome(options=options, use_subprocess=True, version_main=125)
或者可以尝试使用125.0版本的docker镜像
docker run -d -p 4444:4444 -p 15900:5900 -e SE_NODE_MAX_SESSIONS=5 --shm-size=2g selenium/standalone-chrome:125.0
2.也可以尝试使用 DrissionPage 这个包来代替selenium的webdriver
安装DrissionPage
pip3 install DrissionPage
使用
>>> from DrissionPage import ChromiumPage
>>> page = ChromiumPage()
>>> page.get('https://dev.epicgames.com/zh-CN/home')
True
参考:自动绕过 Cloudflare 验证码 - 两条相反的方法(选择最适合您的方法)
不过无论是使用undetected_chromedriver还是DrissionPage,只能绕过cloudflare人机检验,无法绕过hcaptcha验证码,如下

5.M1芯片环境运行selenium docker
由于selenium/standalone-chrome镜像只支持amd64架构,如果是M1芯片的话,需要使用支持arm64架构的镜像 seleniarm/standalone-chromium
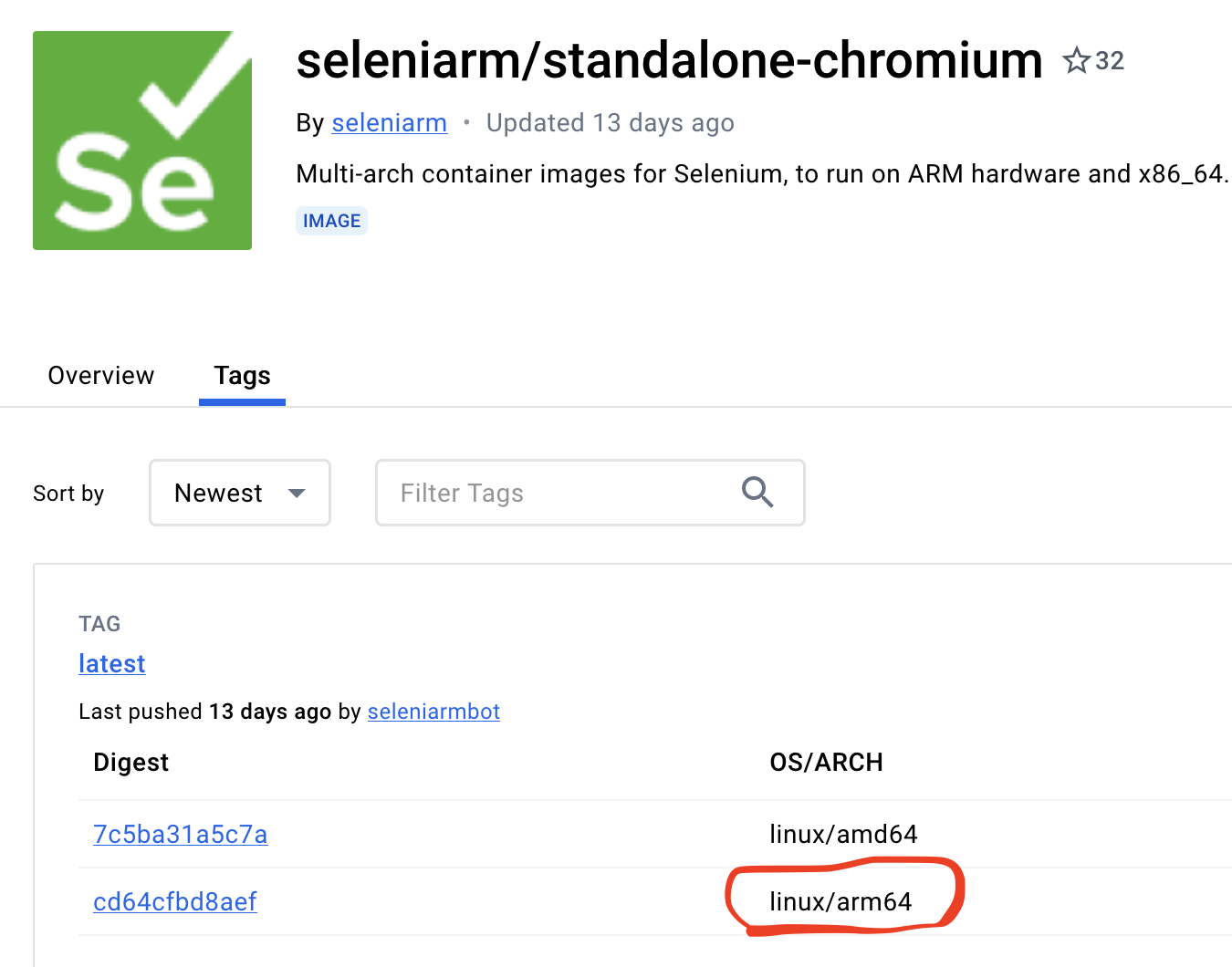
拉取镜像
docker pull seleniarm/standalone-chromium:120.0
启动,需要指定运行平台是linux/arm64
docker run -d -p 4444:4444 -p 15900:5900 -e SE_NODE_MAX_SESSIONS=5 --shm-size=2g --platform linux/arm64 seleniarm/standalone-chrome:120.0
1.M1运行selenium webdriver
seleniarm/standalone-chromium镜像中的浏览器是chromium,和chrome浏览器一些区别,需要指定webdriver的路径为/usr/bin/chromedriver
root@fce0fc2def31:/# python3
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
options = Options()
options.add_argument('--disable-dev-shm-usage')
options.add_argument("--remote-debugging-port=9222") # 不加的话会报session not created: DevToolsActivePort file doesn't exist
options.add_argument('--no-sandbox') # 不加的话会报chrome not reachable
driver = webdriver.Chrome(service=Service("/usr/bin/chromedriver"), options=options)
2.M1运行undetected_chromedriver
如果使用m1芯片想 undetected_chromedriver 来绕过cloudflare的人机校验的话
import undetected_chromedriver as uc
driver = uc.Chrome(driver_executable_path="/usr/bin/chromedriver",headless=True,use_subprocess=False)
driver.maximize_window()
driver.get('https://nowsecure.nl')
driver.save_screenshot('nowsecure.png')
默认的下载路径在/root/Downloads
6.验证码
业界常用的验证码服务有hCaptcha和reCaptcha等
1.hCaptcha
hCaptcha根据面向用户不同可以分成普通版,隐形版,企业版等;根据难度不同可以分成Easy,Medium,Difficult版本等,具体的Demo可以参考 http://www.52spider.com/captcha/hcaptcha-enterprise/
要想通过hCaptcha验证码,如果不想使用验证码识别平台的话,可以使用其提供的视障账号
1.视障账号
hCaptcha的accessibility,这是hCaptcha提供用于视障人员用于跳过验证码的功能
https://www.hcaptcha.com/accessibility
通过注册hCaptcha视障账号 ,可以在如下页面中通过点击set cookie按钮来设置一个cookie用于跳过验证码
https://dashboard.hcaptcha.com/welcome_accessibility
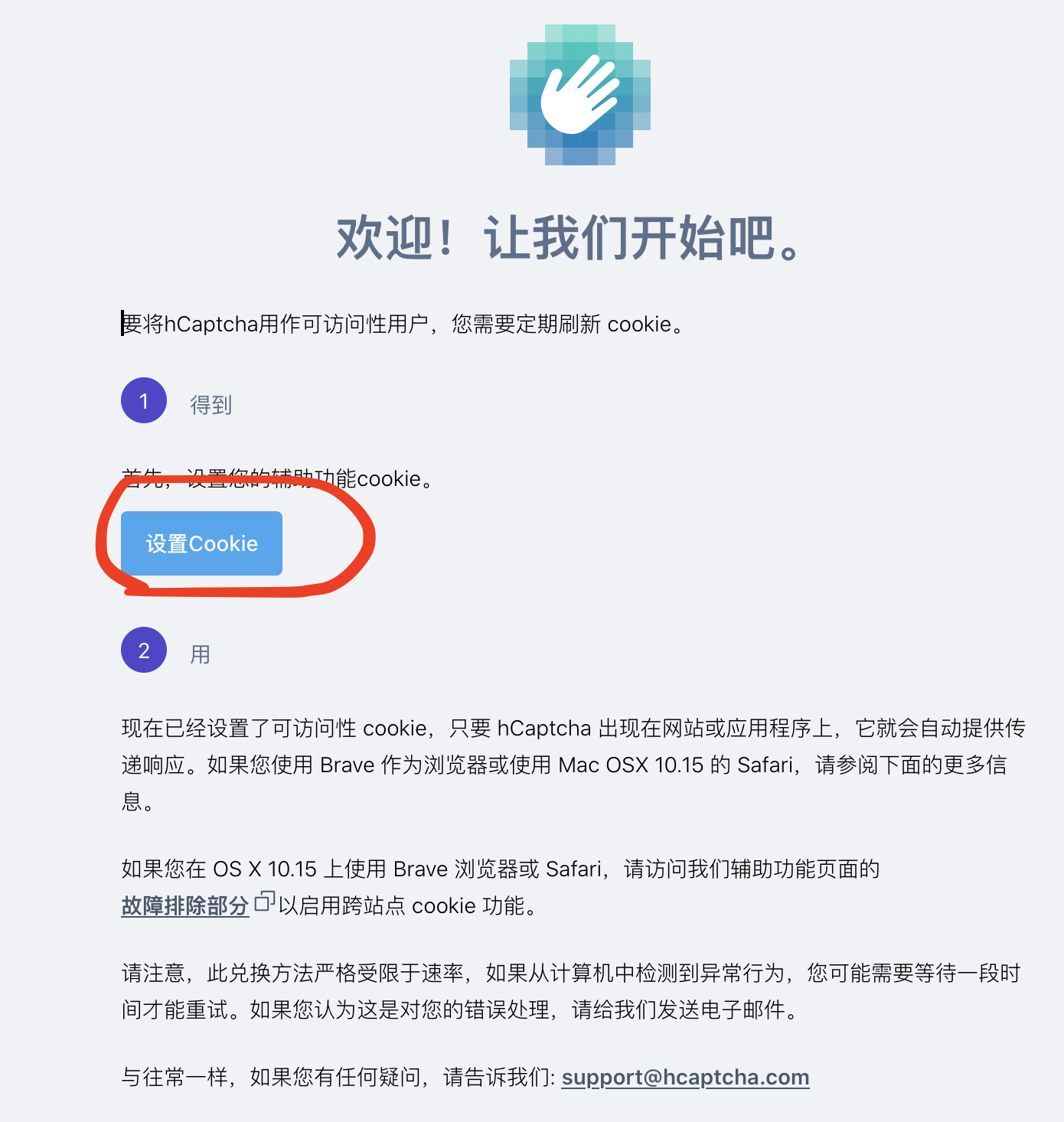
但是set cookie不是所有情况下都能成功的,如果你的环境被检测是机器人,或者ip被封,set cookie的时候则有可能报401,
报错是:无法发布Cookie。如果此问题继续发生,请发送电子邮件至support@hcaptcha.com
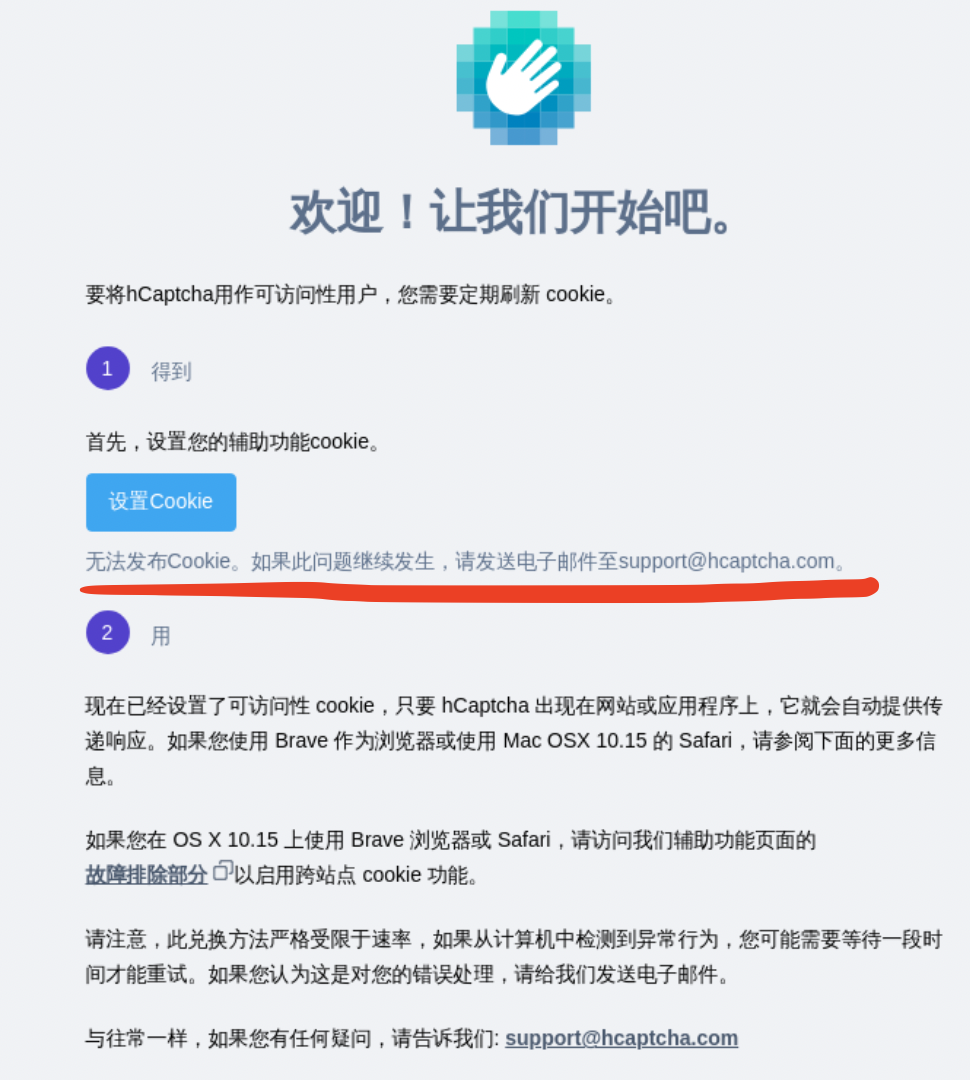
参考:如何绕过烦人的 hCaptcha & Cloudflare Captcha
2.reCaptcha
7.验证码识别平台
可以尝试使用验证码识别平台来识别验证码,比如 2captcha服务,类似的服务还有yescaptcha,NopeCHA。
这类服务一般都提供API和浏览器插件2种方式用于识别验证码,API用于无头浏览器下获取验证码的captcha_response,填入后再点击检测后来提交验证码;而浏览器插件则可以在浏览器中实现自动点击验证码
1.浏览器插件
使用最为简单,只需要安装其提供的验证码识别插件即可,具体每个平台的识别准确率根据验证码难度的不同会不相同
具体使用的时候,可以配合selenium一起使用
1.2captcha
2captcha可以通过作为员工来点击验证码来赚取额度进行测试
2captcha插件 for hCaptcha:https://chromewebstore.google.com/detail/hcaptcha-solver-auto-capt/imgmoeegfjhhmljmphfkjeibkiffcdgl
2captcha插件 for reCaptcha:https://chromewebstore.google.com/detail/recaptcha-solver-auto-cap/infdcenbdoibcacogknkjleclhnjdmfh

经测试2captcha for hCaptcha在某些网站无法工作,对于不同难度的验证码识别正确率暂时未知
2.yescaptcha
貌似是国内开发运行的验证码识别平台,注册送免费额度
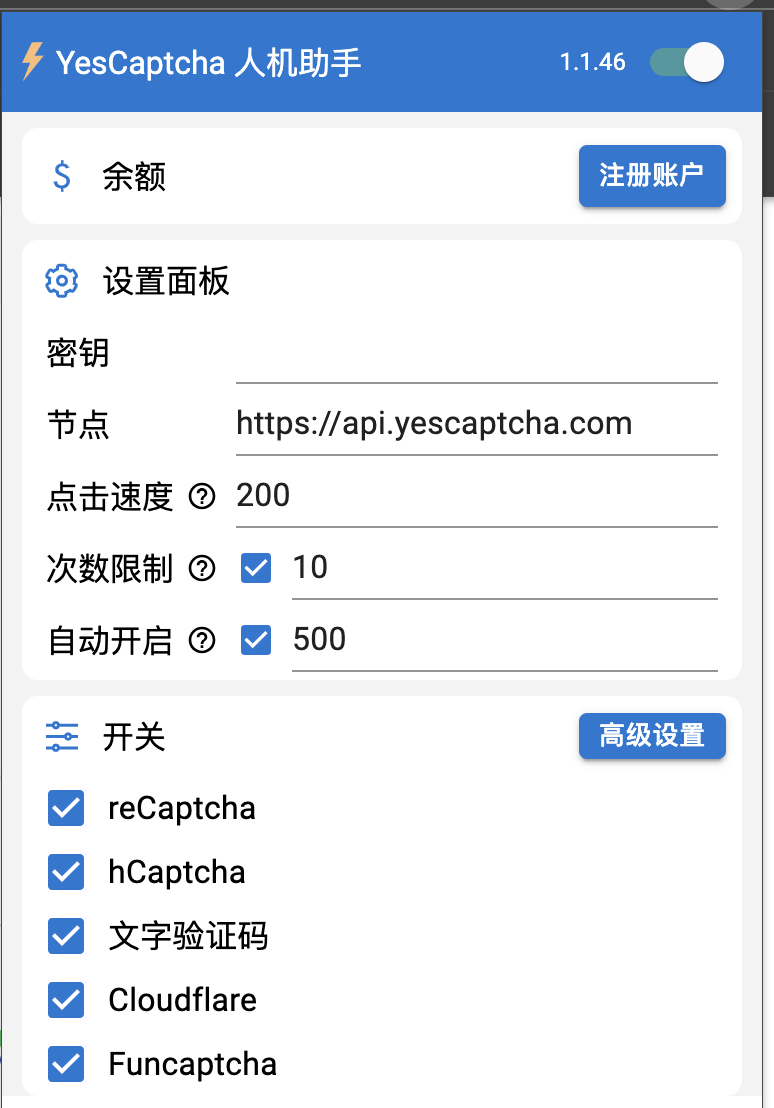
经测试yescaptcha可以正常点击hCaptcha验证码,不过对于hCaptcha difficult难度的hCaptcha验证码有时能点击正确,但是也有较高概率点错
3.nopecaptcha
nopecapcha验证码识别平台,每24小时刷新100免费额度
nopecaptcha插件:https://chromewebstore.google.com/detail/nopecha-captcha-solver/dknlfmjaanfblgfdfebhijalfmhmjjjo
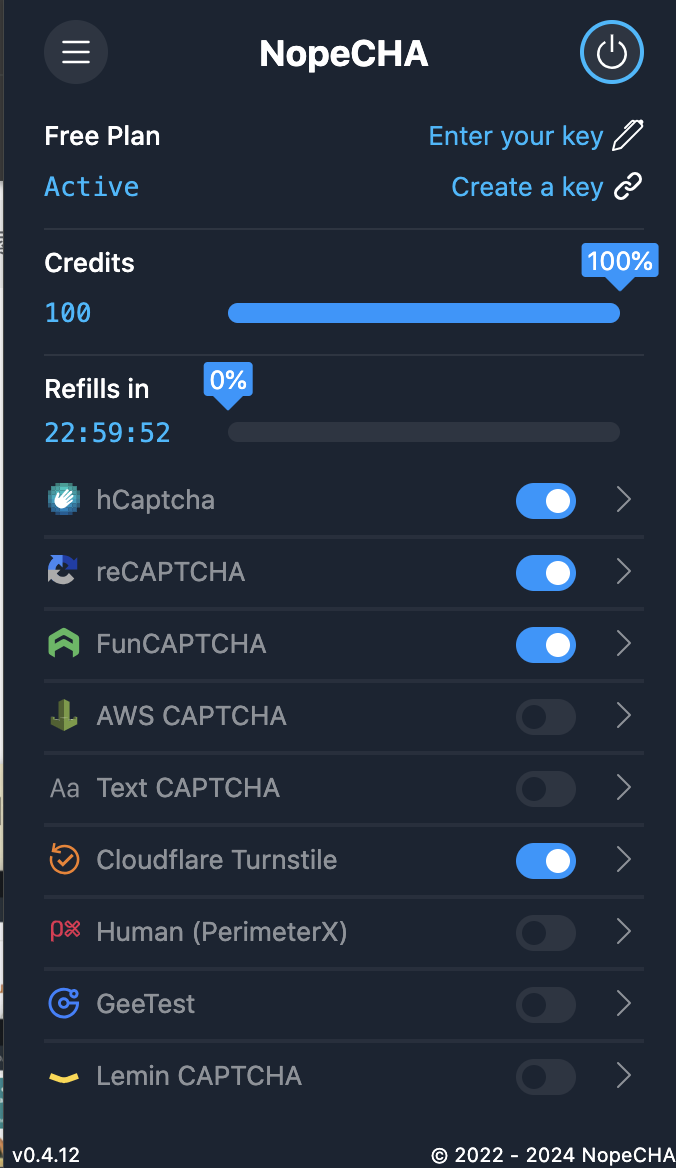
经测试yescaptcha可以正常点击hCaptcha验证码,不过对于hCaptcha difficult难度的hCaptcha验证码错误率离谱,没见过能正确点对的时候
4.capsolver
通过公司邮箱注册的话可以领取免费额度,没进行测试,不知道效果如何
2.API
如果想要使用无头浏览器(比较节省系统资源),可以尝试使用验证码平台提供的API,比如2captcha其支持多种验证码类型,比如reCaptcha,hCaptcha等
API文档可以参考:https://2captcha.com/api-docs
SDK文档可以参考:https://github.com/2captcha/2captcha-python

比如我们要识别hCaptcha的验证码,可以查看2Captcha的API v2下面hCaptcha对应的文档 https://2captcha.com/api-docs/hcaptcha
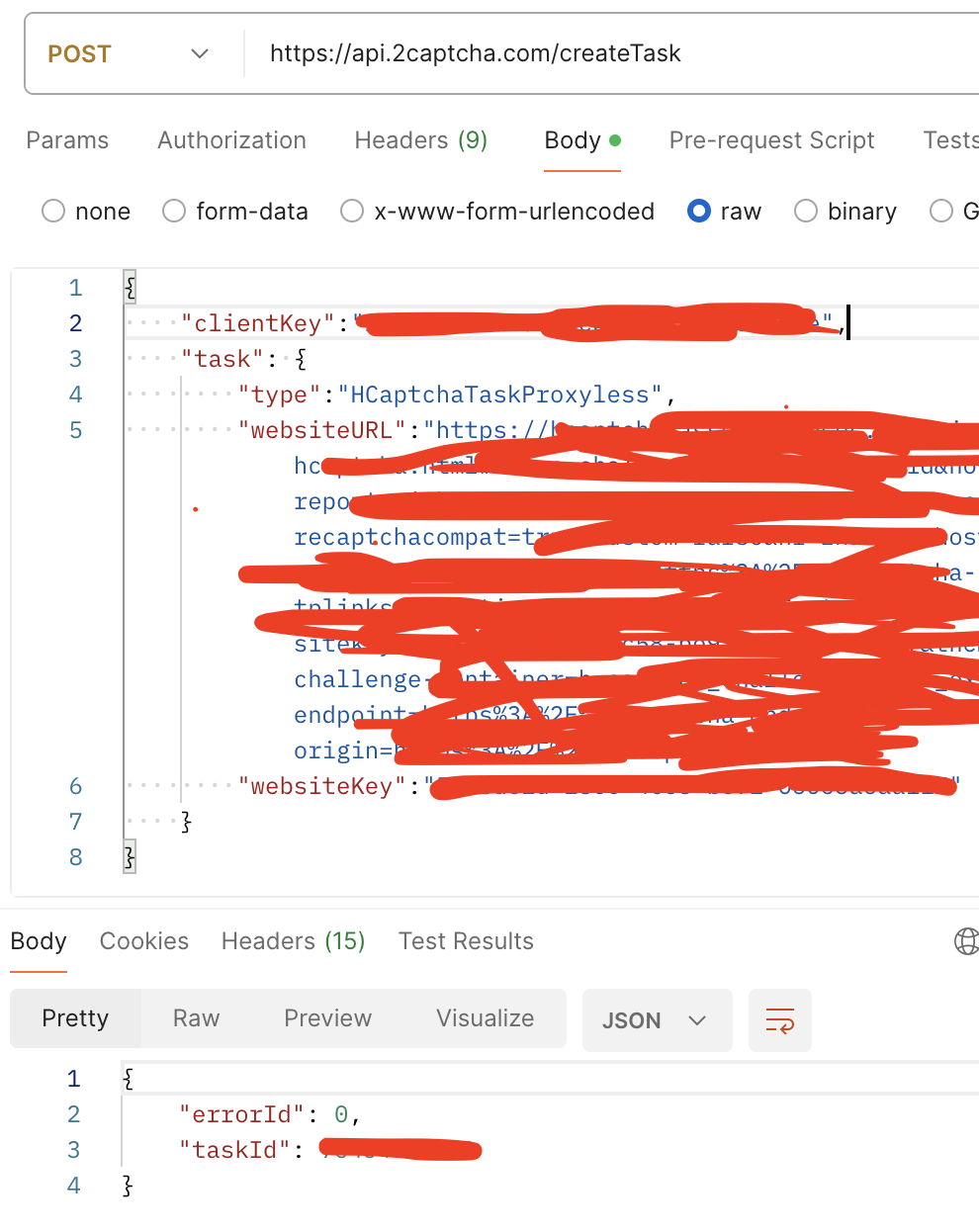
提交的任务提交API将验证码提交上来 https://api.2captcha.com/createTask
注意websiteURL字段如果验证码是通过iframe弹出的话,需要填写iframe的URL
{
"clientKey":"YOUR_API_KEY",
"task": {
"type":"HCaptchaTaskProxyless",
"websiteURL":"https://2captcha.com/demo/hcaptcha",
"websiteKey":"f7de0da3-3303-44e8-ab48-fa32ff8ccc7b"
}
}
如下
然后去 https://2captcha.com/zh/enterpage 的 上次提交的验证码 页面查看验证码识别的进度
这个验证码识别成功
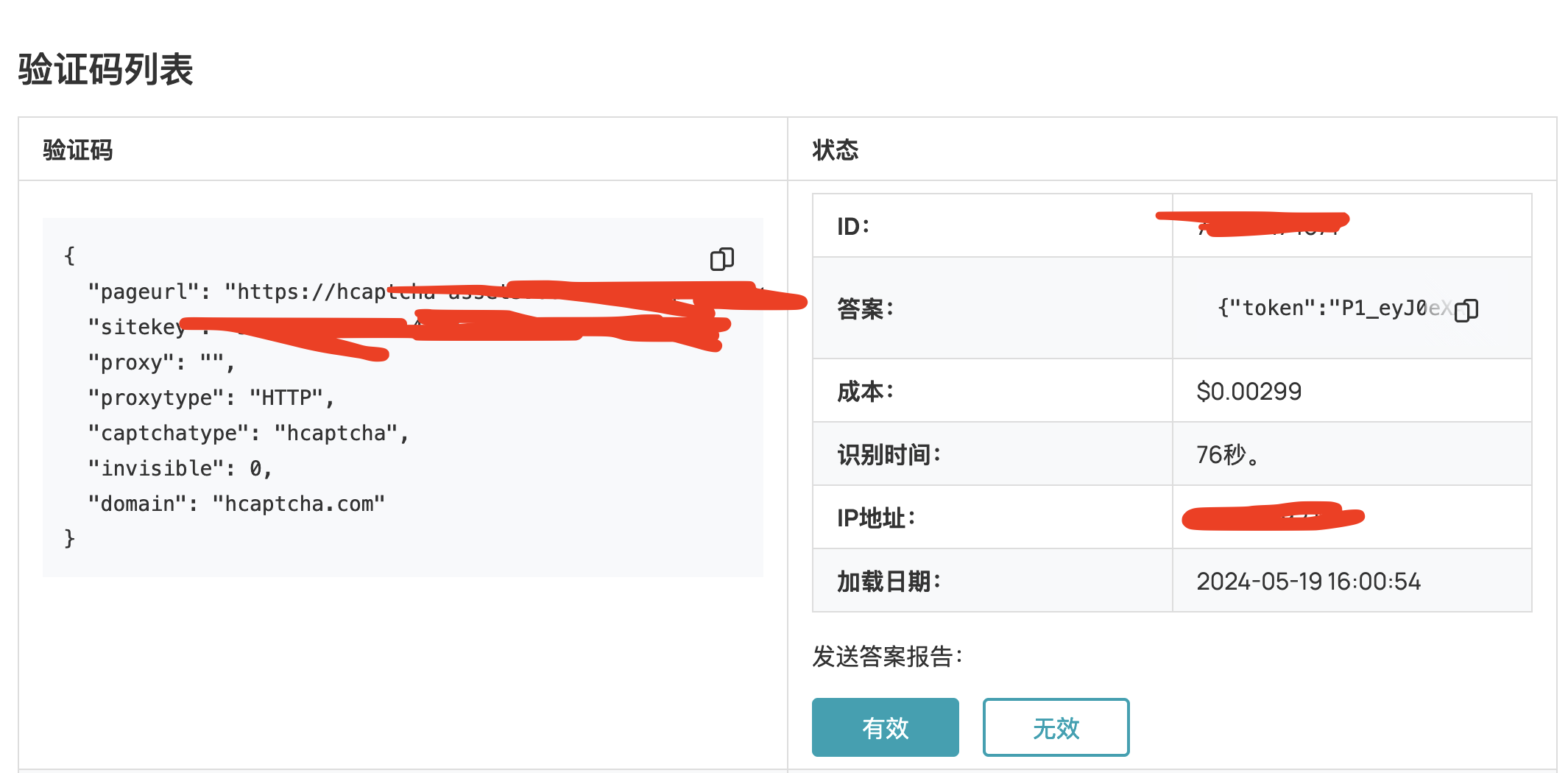
返回的答案如下,其中token是验证码识别的结果,而respKey这个额外的返回值是部分网站需要的
{
"token": "P1_eyJ0eXAiOiJKV...1LDq89KyJ5A",
"respKey": "E0_eyJ0eXAiOiJK...y2w5_YbP8PGuJBBo",
"userAgent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.5614.0 Safari/537.36"
}
如果网站只需要token的话,,这里只需要找到data-hcaptcha-response的属性,将验证码的结尾添加到这个属性的value位置,最后点击check按钮来提交验证码
如果网站同时需要token和respKey的话,这里有些网站会将token和respKey放到一个json中并将其转成jwt格式后调用login接口,一起提交上来
hcapcha js混淆可以参考:关于hcaptcha (vm wasm ob)三合一
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/4663307.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号