Spark学习笔记——读写ScyllaDB
Scylla兼容cassandra API,所以可以使用spark读写cassandra的方法来进行读写
1.查看scyllaDB对应的cassandra版本
cqlsh:my_db> SHOW VERSION [cqlsh 5.0.1 | Cassandra 3.0.8 | CQL spec 3.3.1 | Native protocol v4]
2.查看spark和cassandra对应的版本
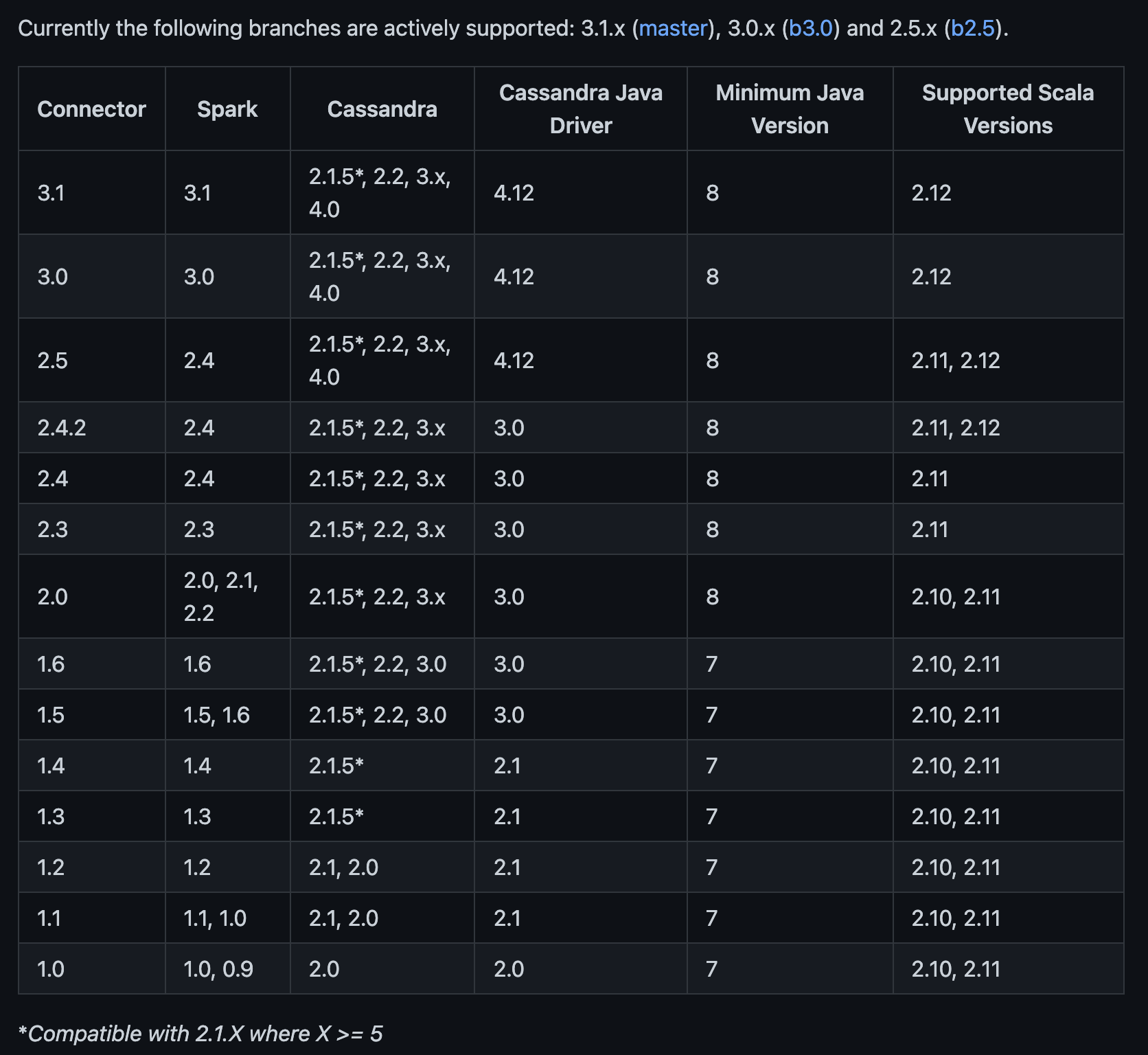
参考:https://github.com/datastax/spark-cassandra-connector
3.写scyllaDB
dataset API写scyllaDB
ds2.write
.mode("append")
.format("org.apache.spark.sql.cassandra")
.options(Map("table" -> "my_tb", "keyspace" -> "my_db", "output.consistency.level" -> "ALL", "ttl" -> "8640000"))
.save()
RDD API写scyllaDB
import com.datastax.oss.driver.api.core.ConsistencyLevel
import com.datastax.spark.connector._
ds.rdd.saveToCassandra("my_db", "my_tb", writeConf = WriteConf(ttl = TTLOption.constant(8640000), consistencyLevel = ConsistencyLevel.ALL))
注意字段的数量和顺序需要和ScyllaDB表的顺序一致,可以使用下面方式select字段
val columns = Seq[String](
"a",
"b",
"c")
val colNames = columns.map(name => col(name))
val colRefs = columns.map(name => toNamedColumnRef(name))
val df2 = df.select(colNames: _*)
df2.rdd
.saveToCassandra(ks, table, SomeColumns(colRefs: _*), writeConf = WriteConf(ttl = TTLOption.constant(8640000), consistencyLevel = ConsistencyLevel.ALL))
不过官方推荐使用DataFrame API,而不是RDD API
If you have the option we recommend using DataFrames instead of RDDs
https://github.com/datastax/spark-cassandra-connector/blob/master/doc/4_mapper.md
4.读scyllaDB
val df = spark
.read
.format("org.apache.spark.sql.cassandra")
.options(Map( "table" -> "words", "keyspace" -> "test" ))
.load()
参考:通过 Spark 创建/插入数据到 Azure Cosmos DB Cassandra API
Cassandra Optimizations for Apache Spark
5.cassandra connector参数
比如如果想实现spark更新scylla表的部分字段,可以将spark.cassandra.output.ignoreNulls设置为true
connector参数:https://github.com/datastax/spark-cassandra-connector/blob/master/doc/reference.md
参数调优参考:Spark + Cassandra, All You Need to Know: Tips and Optimizations
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/15531196.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号