

论文阅读——Twitter日志系统
1.业界公司数据平台建设规模
1.twitter
Twitter关于日志系统的论文有如下2篇,分别是
《The Unified Logging Infrastructure for Data Analytics at Twitter》和《Scaling Big Data Mining Infrastructure: The Twitter Experience》
1 2 | https://vldb.org/pvldb/vol5/p1771_georgelee_vldb2012.pdfhttps://www.kdd.org/exploration_files/V14-02-02-Lin.pdf |
相关PPT
1 2 3 4 5 | https://www.slideshare.net/Hadoop_Summit/scaling-big-data-mining-infrastructure-twitter-experiencehttps://slideplayer.com/slide/12451118/https://blog.twitter.com/engineering/en_us/topics/insights/2016/discovery-and-consumption-of-analytics-data-at-twitter.htmlhttps://www.slideshare.net/kevinweil/hadoop-at-twitter-hadoop-summit-2010https://www.slideshare.net/kevinweil/protocol-buffers-and-hadoop-at-twitter/1-Twitter_Open_Source_Coming_soon |
其中《The Unified Logging Infrastructure for Data Analytics at Twitter》这篇Twitter12年的论文中介绍了Twitter的产品日志基础架构以及从应用特定日志到统一的“客户端事件”日志格式的演进,其中message都是Thrift message。

当时(2012年),Twitter的Hadoop集群规模有几百台。
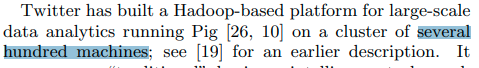
当然后来其他文章介绍说到了2016年,Twitter的集群规模超过了1W台
1 | https://blog.twitter.com/engineering/en_us/topics/insights/2016/discovery-and-consumption-of-analytics-data-at-twitter.html |

到现在,我们一般称10台左右的Hadoop集群为小型规模集群,100多台的集群为中型规模集群,上千台规模的为大型集群,上万台规模的为超大规模集群,当集群规模达到上千台之后,一般就需要做联邦了。
2.airbnb
就其他互联网公司而言,据资料显示:
Airbnb的Hadoop集群规模为1400台+

1 2 | airbnb曾洪博 - 《airbnb数据平台实践》https://myslide.cn/slides/3043 |
3.字节跳动
字节跳动的Hadoop集群规模为多集群上万台

1 2 | 字节跳动 EB 级 HDFS 实践https://www.infoq.cn/article/aLE9ObVYUEmDvRCzCTBr |

Twitter在论文那种提到,在大规模日志的生产者,管理这些数据的基础架构,分析pipeline的工程师,数据科学家之间缺乏一下互动,意思即机器和人都能正确地理解一份数据,
比如一个字段内容为"123",基础架构服务能知道它是string,而不是int;日志的生产者生产了一份数据,数据分析师能知道日志中每个字段的含义等等。这在Airbnb的PPT《Airbnb的核心日志系统》中也提到了
2.日志序列化方案选择
引入日志schema的好处
在字段定义上,文章中提到了字段格式的问题,就是驼峰,下划线,还有id,uid。。。这些问题还是比较常见的

还有就是日志格式问题,非结构化,半结构化,即使是json格式的日志也存在字段可以动态变化,字段是否是optional的问题

在《Scaling Big Data Mining Infrastructure: The Twitter Experience》这篇文章中,作者提到了几点:
1.不要使用mysql来存储日志
2.使用HDFS来存储日志,每个HDFS目录下保持,少量的文件数以及大文件

至于存储在HDFS的压缩格式,《Hadoop at Twitter (Hadoop Summit 2010)》中介绍的是lzo压一切,至于lzo和其他压缩方式的对比,可以参考我的文章《MapReduce中的InputFormat》

3.从需要正则表达式解析的纯文本(plain-text)日志格式到json格式,再到Thrift格式

4.使用IDL语言定义日志格式,此外Twitter还开发了Elephant bird来自动生成和Hadoop,Pig交互的代码,有了这些,基础架构组件和开发人员都能很好地理解日志

1.Airbnb(Thrift)

1 | https://myslide.cn/slides/635 |
2.Twitter(Thrift)
Twitter使用Facebook开源的Scribe进行日志采集,同时Twitter在论文中提到,每一种日志包含了2个string,一个是category,一个是message。其中category有配置中的元数据决定,包含了这个数据是从哪个写入的。

同时,Twitter使用ZooKeeper对scribe的agent进行管理,方案很常见,就是在zk注册一个临时节点,当节点超时和zk通信超时一段时间后,临时节点就会消失,即agent失联
有点类似filebeat的中心化管理(Beats central management),除外Apache Flume也可以使用Zookeeper作为配置中心
1 | https://www.elastic.co/guide/en/beats/filebeat/7.10/configuration-central-management.html |
不过Twitter后来使用Flume替换了Scribe

1 | https://www.slideshare.net/prasadwagle/extracting-insights-from-data-at-twitter |

当日志落盘到HDFS上的时候,系统将会根据日志中的category,自动将其写到一个对应的HDFS路径,即/logs/category


在日志定义中,由于Twitter广泛使用的是Thrift,所以其也就沿用了Thrift作为其日志定义语言,除了Twitter,使用Thrift来定义日志格式的公司还有Airbnb和Xiaomi;而使用Protobuf有百度,字节跳动,快手,友盟;使用avro的有uber和linkedin

3.百度(Protobuf)

1 2 | 从日志统计到大数据分析(六)——秦天下https://zhuanlan.zhihu.com/p/20401637 |
4.字节跳动(Protobuf)

1 2 | 今日头条数据平台架构师王烨 - 今日头条大数据平台的演进https://myslide.cn/slides/3497 |
5.快手(Protobuf)

1 2 | Flink在快手实时多维分析场景的应用https://cloud.tencent.com/developer/news/643334 |
6.Uber(Avro)

1 2 | Chaperone:Uber是如何对Kafka进行端到端审计的https://www.infoq.cn/article/2016/12/uber-chaperone-kafka |
7.Linkedin(Avro)

8.友盟(Protobuf)

9.知乎(Protobuf)
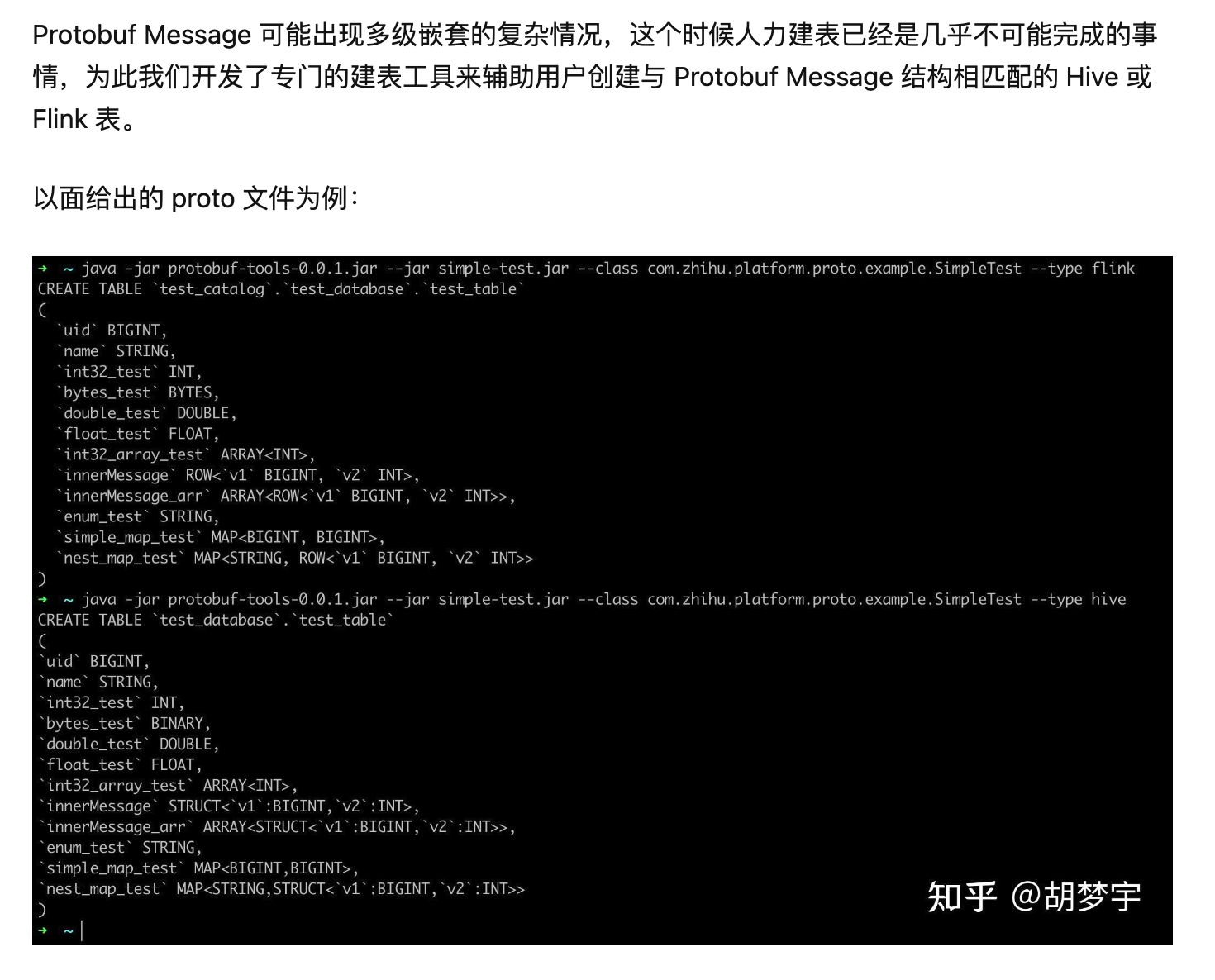
10.腾讯TEG(Protobuf)

本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/14086820.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决
2018-12-08 Elasticsearch学习笔记——分词