

MapReduce中的InputFormat
InputFormat在hadoop源码中是一个抽象类 public abstract class InputFormat<K, V>
1 | https://github.com/apache/hadoop/blob/master/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-core/src/main/java/org/apache/hadoop/mapreduce/InputFormat.java |
可以参考文章
1 | https://cloud.tencent.com/developer/article/1043622 |
其中有两个抽象方法
1 2 3 | public abstract List<InputSplit> getSplits(JobContext context ) throws IOException, InterruptedException; |
和
1 2 3 4 5 | public abstract RecordReader<K,V> createRecordReader(InputSplit split, TaskAttemptContext context ) throws IOException, InterruptedException; |
InputFormat做的事情就是将inputfile使用getSplits方法切分成List<InputSplit>,之后使用createRecordReader方法将每个split 解析成records, 再依次将record解析成<K,V>对
1.getSplits方法负责将输入的文件做一个逻辑上的切分,切分成一个List<InputSplit>,InputSplit的源码在
1 | https://github.com/apache/hadoop/blob/master/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-core/src/main/java/org/apache/hadoop/mapreduce/InputSplit.java |
在下文中提到 InputSplit是一个逻辑概念,并没有对实际文件进行切分,它只包含一些元数据信息,比如数据的起始位置,数据长度,数据所在的节点等
1 | https://cloud.tencent.com/developer/article/1481777 |
2.createRecordReader方法 将每个 split 解析成records, 再依次将record解析成<K,V>对
常用的InputFormat如下图
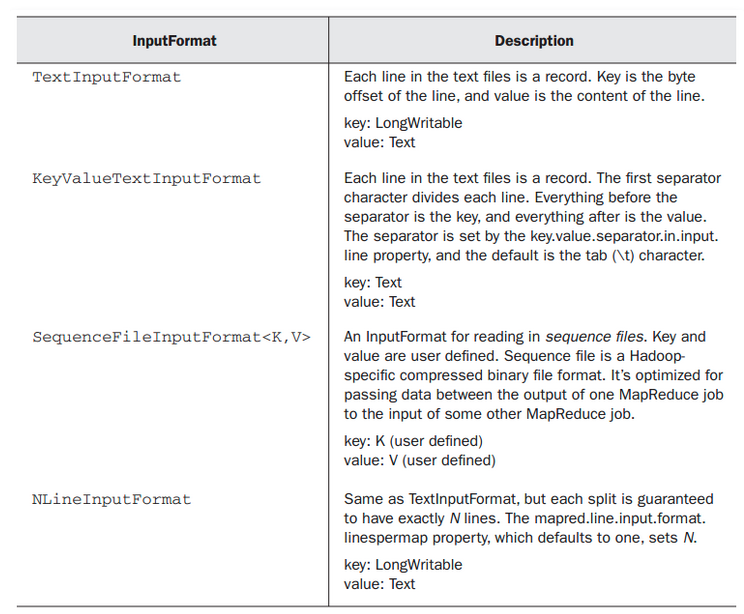
<1>其中 TextInputFormat 格式的文件,每一行是一个record,key是这一行的byte的offset,即key是LongWritable,value是Text
比如我们使用下面的建表语句来创建一张hive表
1 2 3 4 | CREATE TABLE `default.test_1`( `key` string, `value` string)STORED AS TEXTFILE |
其hive表对应的inputformat即为 org.apache.hadoop.mapred.TextInputFormat
1 2 3 4 5 6 7 8 9 10 11 12 13 | CREATE TABLE `default.test_1`( `key` string, `value` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://xxx-nameservice/user/hive/warehouse/test_1' TBLPROPERTIES ( 'transient_lastDdlTime'='1605247462') |
<2>其中 KeyValueTextInputFormat 格式是最简单的 Hadoop 输入格式之一,可以用于从文本文件中读取键值对数据。每一行都会被独立处理,键和值之间用制表符隔开。
比如文件的内容为,中间以tab分隔
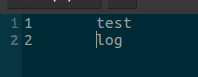
如果使用 TextInputFormat 来读取的话
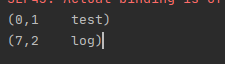
1 2 3 4 5 6 7 8 9 10 11 | def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf) val job = Job.getInstance() val data = sc.newAPIHadoopFile("file:///home/lintong/下载/test.log", classOf[TextInputFormat], classOf[LongWritable], classOf[Text], job.getConfiguration) data.foreach(println)} |
输出为,其中_1为LongWritable,即byte的offset,_2为每行的文件内容
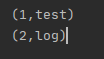
如果使用 KeyValueTextInputFormat 来读取的话
1 2 3 4 5 6 7 8 9 10 11 | def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf) val job = Job.getInstance() val data = sc.newAPIHadoopFile("file:///home/lintong/下载/test.log", classOf[KeyValueTextInputFormat], classOf[Text], classOf[Text], job.getConfiguration) data.foreach(println)} |
输出为其中_1为Text,即tab分隔之前的内容,_2为tab分隔之后的内容,如果有多个tab的话,只会切分第一个tab
<3> 对于 SequenceFileInputFormat 格式,这是一种专门用于二进制文件的input format,key和value的类型由用户决定
在hive中如果使用thrift和PB序列化格式的hive表,可以参考Twitter的elephant-bird项目
1 | https://github.com/twitter/elephant-bird/wiki/How-to-use-Elephant-Bird-with-Hive |
下面给出一个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | CREATE EXTERNAL TABLE `default.test`( `bbb` string COMMENT 'from deserializer', `aaa` string COMMENT 'from deserializer') COMMENT 'aas' PARTITIONED BY ( `ds` string COMMENT '日期分区') ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.thrift.ThriftDeserializer' WITH SERDEPROPERTIES ( 'serialization.class'='com.xxx.xxx.xxx.tables.v1.XXXX', 'serialization.format'='org.apache.thrift.protocol.TCompactProtocol') STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.SequenceFileInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat' LOCATION 'hdfs://master:8020/user/hive/warehouse/test' TBLPROPERTIES ( 'transient_lastDdlTime'='xxxxxx') |
如果使用spark来读写sequencefile文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | def main(args: Array[String]) { val conf = new SparkConf().setAppName("WordCount").setMaster("local") val sc = new SparkContext(conf) //写sequenceFile, val rdd = sc.parallelize(List(("Panda", 3), ("Kay", 6), ("Snail", 2))) rdd.saveAsSequenceFile("file:///home/lintong/下载/output") //读sequenceFile val output = sc.sequenceFile("file:///home/lintong/下载/output", classOf[Text], classOf[IntWritable]). map{case (x, y) => (x.toString, y.get())} output.foreach(println) } |
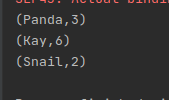
输出的文件格式为二进制,如下

读取结果如下
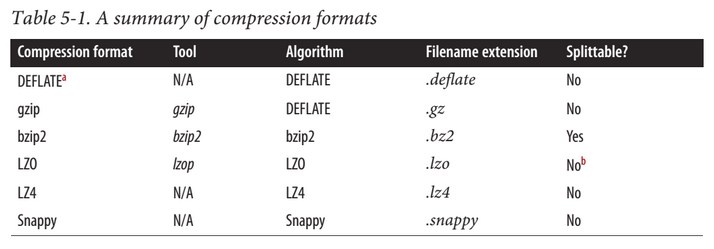
对于那些不支持split的文件格式,提升mapreduce任务的map数并不能加快处理的速度,参考hadoop权限指南的表格
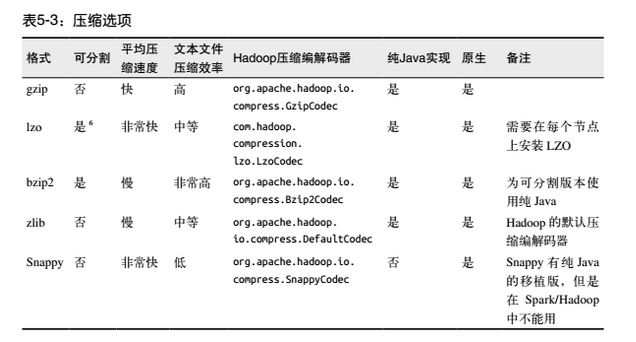
注意:其中gzip压缩格式适合用于冷数据上;snappy和lzo压缩格式适合用于热数据上;
lzo格式在创建在index索引文件后,可以支持切分;
此外,从cloudera的文章 Choosing and Configuring Data Compression 中,可以看出
gzip和snappy格式的块是不能切分的,但是使用了avro这种容器文件格式的snappy块的文件是可以切分的;snappy压缩格式也建议是使用在二进制文件和avro数据文件中,不建议使用在文本格式文件中,比如json格式

facebook 提供的各种压缩算法的benchmark
1 | https://github.com/facebook/zstd#benchmarks |
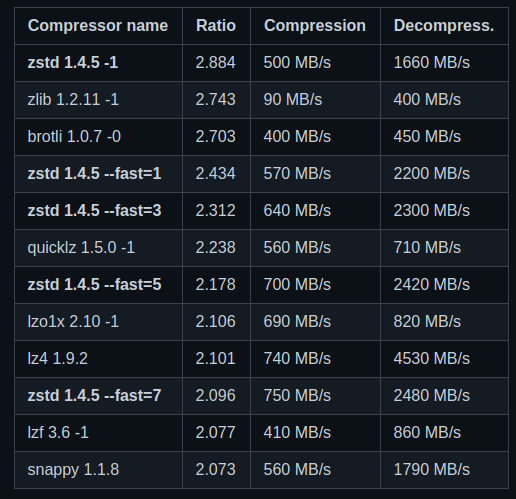
其中zstd也是可以切分的
1 | https://medium.com/@anirbangoswami_22783/parquet-zstd-vs-gzip-740a83571ecd |
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/13750952.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决
2019-09-30 Nexus上传python包
2016-09-30 面试题目——《CC150》Java