
aws s3原理和常用命令
1.概念
Amazon s3全称Amazon Simple Storage Service,是一个对象存储,不是一个file system,所以在使用s3的时候,list dir会很慢
kv存储:从零开始写KV数据库:基于哈希索引
比如如下的s3路径
s3://BucketName/Project/WordFiles/123.txt
其中BucketName是s3的桶名
bucketname/Project/WordFiles/是分区前缀prefix
123.txt是对象名字
s3://BucketName/Project/WordFiles/123.txt是键前缀
参考:对于 Amazon S3 请求速率,前缀和嵌套文件夹之间有何区别? S3 存储桶中可以有多少个前缀?
S3 - What Exactly Is A Prefix? And what Ratelimits apply?
Organizing objects using prefixes
2.s3性能
Amazon S3 是一个非常大的分布式系统,在应用程序对 Amazon S3 读写数据时,您可以将请求性能扩展到每秒数千个事务。
Amazon S3 性能不是按存储桶定义的,而是按存储桶中的前缀。在一个存储桶中,对于每个前缀,应用程序每秒可以处理至少 3500 个 PUT/COPY/POST/DELETE 请求或 5500 个 GET/HEAD 请求。
此外,存储桶中的前缀数量没有限制,因此您可以利用并行处理,横向扩展读取或写入性能。
例如,如果您在 S3 存储桶中创建 10 个前缀来并行执行读取操作,则可以将读取性能扩展到每秒 55000 个读取请求。同样,您也可以利用多个前缀写入数据来扩展写入性能。
参考:Best practices design patterns: optimizing Amazon S3 performance
从 Amazon EMR 和 AWS Glue 访问 Amazon S3 中数据的性能优化最佳实践
3.对象存储和文件系统的区别
参考:是否可以将 Amazon S3 而不是 HDFS 作为 Hadoop 存储?
https://hadoop.apache.org/docs/stable2/hadoop-project-dist/hadoop-common/filesystem/introduction.html#Object_Stores_vs._Filesystems
脉脉上老哥的解答
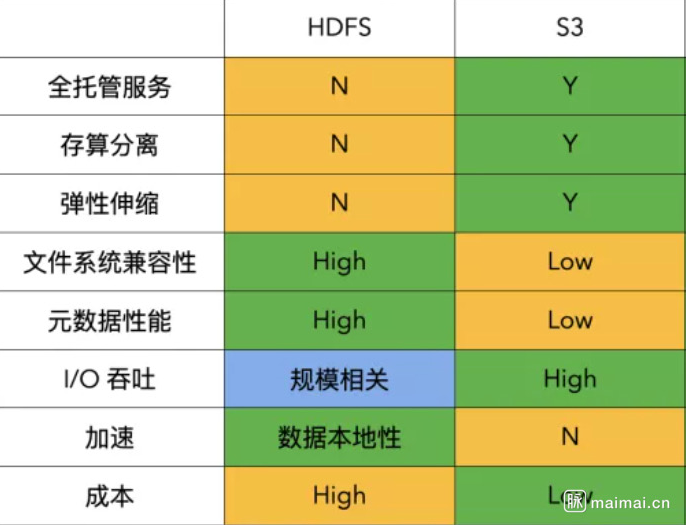
对于hdfs这种的fs而言,rename和list操作很快,而s3作为KV存储,rename和list操作很慢,因此s3使用了dynamodb使用了索引对齐做加速,尤其是rename操作,s3的rename等于copy+delete
4.s3协议的区别
| Generation | Usage | Description |
| First | s3:\\ | s3 which is also called classic (s3: filesystem for reading from or storing objects in Amazon S3 This has been deprecated and recommends to use either the second or third generation library. |
| Second | s3n:\\ | s3n uses native s3 object and makes easy to use it with Hadoop and other files systems. |
| Third | s3a:\\ | s3a – This is a replacement of s3n which supports larger files and improves in performance. |
在EMR中,还是建议使用s3协议

s3和cdh hdfs之间数据迁移,参考
http://bdlabs.edureka.co/static/help/topics/cdh_admin_distcp_data_cluster_migrate.html
HDP的s3 guide
https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.0.0/bk_cloud-data-access/content/s3-get-started.html
s3常用命令,参考:
https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/cli-services-s3.html
5.常用命令
1.安装awscli
pip install awscli
版本
aws --version aws-cli/1.18.143 Python/3.6.2 Linux/4.4.0-165-generic botocore/1.18.2
有些在CDH的s3自动安装的awscli版本可能会过低,导致一些命令不支持,比如
aws --version aws-cli/1.4.2 Python/3.4.2 Linux/4.9.0-0.bpo.6-amd64
在~/.aws目录下配置region和账号密码
~/.aws$ ls config credentials
config
[default] region = ap-northeast-1
credentials
[default] aws_access_key_id = XXXX aws_secret_access_key = XXXX
2.查看文件夹
aws s3 ls s3://xxxxx/logs/
3. 递归删除s3文件夹
aws s3 rm --recursive s3://xxxxx/logs/test
4.下载对象存储的前1024个字节的文件
aws s3api get-object --bucket {bucket-name} --key xxx/xxx/xxx_log/2021-09-22/xx-xx.gz --range bytes=0000-1024 my_data_range
5.下载s3文件到本地
aws s3 cp s3://{bucket_name}/xxxx/xx/xxxx/2021-10-21/00/xxxxx.bin.gz ./
6.上传文件到s3
aws s3 cp ~/test.json s3://xxx-bucket/new_dic/
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/13683861.html

