
Flink学习笔记——读写kafka
Flink的kafka connector文档
https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/connectors/kafka.html
Flink写入kafka时候需要实现序列化和反序列化
部分代码参考了
https://github.com/apache/flink/blob/master/flink-end-to-end-tests/flink-streaming-kafka-test/src/main/java/org/apache/flink/streaming/kafka/test/KafkaExample.java
以及
https://juejin.im/post/5d844d11e51d4561e0516bbd https://developer.aliyun.com/article/686809
1.依赖,其中
flink-java提供了flink的java api,包括dataset执行环境,format,一些算子
https://github.com/apache/flink/tree/master/flink-java/src/main/java/org/apache/flink/api/java
flink-streaming-java提供了flink的java streaming api,包括stream执行环境,一些算子
https://github.com/apache/flink/tree/master/flink-streaming-java/src/main/java/org/apache/flink/streaming/api
flink-connector-kafka提供了kafka的连接器
https://github.com/apache/flink/tree/master/flink-connectors/flink-connector-kafka
1.pom文件依赖
<!-- log4j -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<!--flink-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.0</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
2.Kafka Consumer
作为kafka consumer有几个比较重要的配置参数
2.1 消费kafka内容并打印
这里选用SimpleStringSchema序列化方式,只会打印message
public static void main(String[] args) throws Exception {
ParameterTool pt = ParameterTool.fromArgs(args);
if (pt.getNumberOfParameters() != 1) {
throw new Exception("Missing parameters!\n" +
"Usage: --conf-file <conf-file>");
}
String confFile = pt.get("conf-file");
pt = ParameterTool.fromPropertiesFile(confFile);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(pt);
// 消费kafka
DataStream input = env
.addSource(
new FlinkKafkaConsumer(
pt.getProperties().getProperty("input.topic"),
new SimpleStringSchema(),
pt.getProperties()
)
);
// 打印
input.print();
env.execute("Kafka consumer Example");
}
idea args配置
--conf-file ./conf/xxxxx.conf
xxxxx.conf内容
# kafka source config bootstrap.servers=master:9092 input.topic=test_topic group.id=test
往kafka的topic中灌入数据,控制台会打印出刚刚输入的数据
2.2 消费kafka内容并打印
如果想要在消费kafka的时候,得到除message之外的其他信息,比如这条消息的offset,topic,partition等,可以使用 JSONKeyValueDeserializationSchema,JSONKeyValueDeserializationSchema将以json格式来反序列化byte数组
使用 JSONKeyValueDeserializationSchema 的时候需要保证输入kafka的数据是json格式的,否则会有报错
Caused by: org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'asdg': was expecting (JSON String, Number, Array, Object or token 'null', 'true' or 'false')
实现
FlinkKafkaConsumer<ConsumerRecord<String, String>> consumer = new FlinkKafkaConsumer(pt.getProperties().getProperty("input.topic"),
new JSONKeyValueDeserializationSchema(false), pt.getProperties());
如果为false,输出
2> {"value":123123}
如果为true,输出
2> {"value":123123,"metadata":{"offset":18,"topic":"xxxxx","partition":0}}
map输出offset
// 打印
input.map(new MapFunction<ObjectNode, String>() {
@Override
public String map(ObjectNode value) {
return value.get("metadata").get("offset").asText();
}
}).print();
如果还要获得其他信息,比如kafka消息的key,也可以自行实现 KafkaDeserializationSchema,参考如下
https://blog.csdn.net/jsjsjs1789/article/details/105099742 https://blog.csdn.net/weixin_40954192/article/details/107561435
kafka的key的用途有2个:一是作为消息的附加信息,二是可以用来决定消息应该写到kafka的哪个partition
public class KafkaConsumerRecordDeserializationSchema implements KafkaDeserializationSchema<ConsumerRecord<String, String>> {
@Override
public boolean isEndOfStream(ConsumerRecord<String, String> nextElement) {
return false;
}
@Override
public ConsumerRecord<String, String> deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
return new ConsumerRecord<String, String>(
record.topic(),
record.partition(),
record.offset(),
record.key() != null ? new String(record.key()) : null,
record.value() != null ? new String(record.value()) : null);
}
@Override
public TypeInformation<ConsumerRecord<String, String>> getProducedType() {
return TypeInformation.of(new TypeHint<ConsumerRecord<String, String>>() {
});
}
}
然后
FlinkKafkaConsumer<ConsumerRecord<String, String>> consumer =
new FlinkKafkaConsumer<>(pt.getProperties().getProperty("input.topic"), new KafkaConsumerRecordDeserializationSchema(), pt.getProperties());
输出
2> ConsumerRecord(topic = xxxx, partition = 0, leaderEpoch = null, offset = 19, NoTimestampType = -1, serialized key size = -1, serialized value size = -1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 1111111)
3.Kafka Producer
FlinkKafkaProducer有多个版本,参考:你真的了解Flink Kafka source吗?
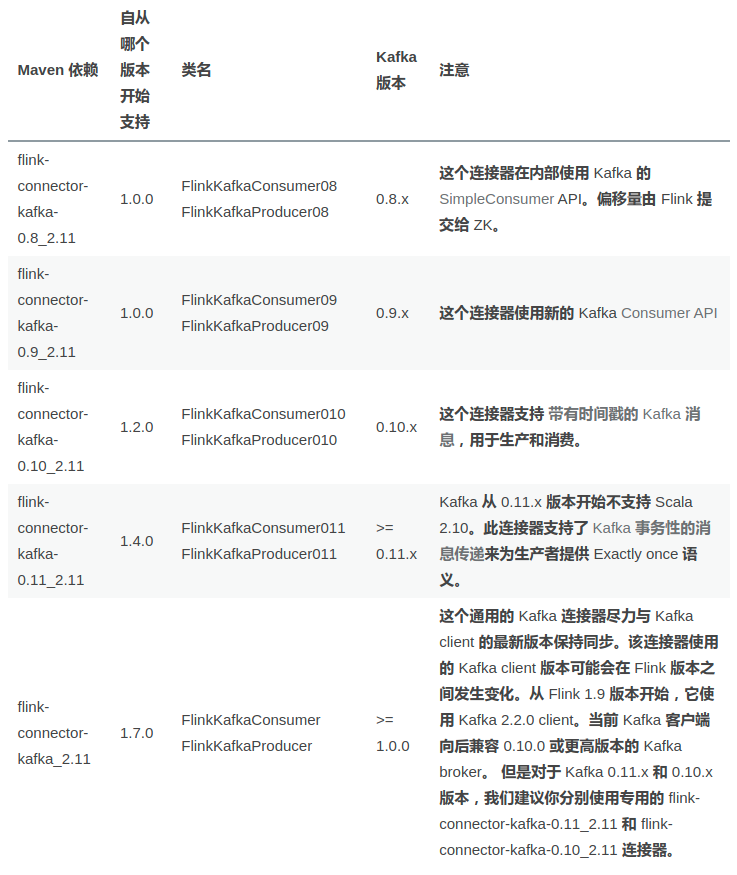
FlinkKafkaProducer可以参考
https://www.programcreek.com/java-api-examples/?api=org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer
3.1 从kafka的topic读取数据 ,之后写到另外一个kafka的topic中
使用 SimpleStringSchema,这里FlinkKafkaProducer会显示过期,但不影响功能
public static void main(String[] args) throws Exception {
ParameterTool pt = ParameterTool.fromArgs(args);
if (pt.getNumberOfParameters() != 1) {
throw new Exception("Missing parameters!\n" +
"Usage: --conf-file <conf-file>");
}
String confFile = pt.get("conf-file");
pt = ParameterTool.fromPropertiesFile(confFile);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(pt);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
FlinkKafkaConsumer<ConsumerRecord<String, String>> consumer = new FlinkKafkaConsumer(
pt.getProperties().getProperty("input.topic"),
new SimpleStringSchema(),
pt.getProperties()
);
// 消费kafka
DataStream input = env.addSource(consumer);
// 打印
input.print();
// producer
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(
pt.getProperties().getProperty("output.topic"),
new SimpleStringSchema(),
pt.getProperties()
);
// 往kafka中写数据
input.addSink(producer);
env.execute("Kafka consumer Example");
}
配置文件
# kafka config bootstrap.servers=localhost:9092 input.topic=thrift_log_test output.topic=test group.id=test
输出
如果想写到文件,可以setParallelism是控制输出的文件数量,1是写成1个文件,大于1会是文件夹下面的多个文件
input.writeAsText("file:///Users/lintong/coding/java/flink-demo/conf/test.log").setParallelism(1);
3.2 也可以自行实现 KafkaSerializationSchema 接口来序列化string
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.nio.charset.StandardCharsets;
public class KafkaProducerStringSerializationSchema implements KafkaSerializationSchema<String> {
private String topic;
public KafkaProducerStringSerializationSchema(String topic) {
super();
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, Long timestamp) {
return new ProducerRecord<>(topic, element.getBytes(StandardCharsets.UTF_8));
}
}
然后
public static void main(String[] args) throws Exception {
ParameterTool pt = ParameterTool.fromArgs(args);
if (pt.getNumberOfParameters() != 1) {
throw new Exception("Missing parameters!\n" +
"Usage: --conf-file <conf-file>");
}
String confFile = pt.get("conf-file");
pt = ParameterTool.fromPropertiesFile(confFile);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(pt);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// consumer
FlinkKafkaConsumer<ConsumerRecord<String, String>> consumer = new FlinkKafkaConsumer(
pt.getProperties().getProperty("input.topic"),
new SimpleStringSchema(),
pt.getProperties()
);
// 消费kafka
DataStream input = env.addSource(consumer);
// 打印
input.print();
// producer
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(
pt.getProperties().getProperty("output.topic"),
new KafkaProducerStringSerializationSchema(pt.getProperties().getProperty("output.topic")),
pt.getProperties(),
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
);
// 往kafka中写数据
input.addSink(producer);
env.execute("Kafka consumer Example");
}
3.3 使用 ProducerRecord<String, String> 序列化
public class KafkaProducerRecordSerializationSchema implements KafkaSerializationSchema<ProducerRecord<String, String>> {
@Override
public ProducerRecord<byte[], byte[]> serialize(ProducerRecord<String, String> element, Long timestamp) {
return new ProducerRecord<>(element.topic(), element.value().getBytes(StandardCharsets.UTF_8));
}
}
然后
public static void main(String[] args) throws Exception {
ParameterTool pt = ParameterTool.fromArgs(args);
if (pt.getNumberOfParameters() != 1) {
throw new Exception("Missing parameters!\n" +
"Usage: --conf-file <conf-file>");
}
String confFile = pt.get("conf-file");
pt = ParameterTool.fromPropertiesFile(confFile);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(pt);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// consumer
FlinkKafkaConsumer<ConsumerRecord<String, String>> consumer = new FlinkKafkaConsumer<>(
pt.getProperties().getProperty("input.topic"),
new KafkaConsumerRecordDeserializationSchema(),
pt.getProperties()
);
// 消费kafka
DataStream input = env.addSource(consumer);
String outputTopic = pt.getProperties().getProperty("output.topic");
// 转换
DataStream output = input.map(new MapFunction<ConsumerRecord<String, String>, ProducerRecord<String, String>>() {
@Override
public ProducerRecord<String, String> map(ConsumerRecord<String, String> value) throws Exception {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(outputTopic, value.value());
return producerRecord;
}
});
FlinkKafkaProducer<ProducerRecord<String, String>> producer = new FlinkKafkaProducer<>(
pt.getProperties().getProperty("output.topic"),
new KafkaProducerRecordSerializationSchema(),
pt.getProperties(),
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
);
// 往kafka中写数据
output.addSink(producer);
output.print();
env.execute("Kafka consumer Example");
}
也可以参考官方文档
https://github.com/apache/flink/blob/master/flink-end-to-end-tests/flink-streaming-kafka-test/src/main/java/org/apache/flink/streaming/kafka/test/KafkaExample.java
代码
package com.bigdata.flink;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class KafkaExampleUtil {
public static StreamExecutionEnvironment prepareExecutionEnv(ParameterTool parameterTool)
throws Exception {
if (parameterTool.getNumberOfParameters() < 5) {
System.out.println("Missing parameters!\n" +
"Usage: Kafka --input-topic <topic> --output-topic <topic> " +
"--bootstrap.servers <kafka brokers> " +
"--zookeeper.connect <zk quorum> --group.id <some id>");
throw new Exception("Missing parameters!\n" +
"Usage: Kafka --input-topic <topic> --output-topic <topic> " +
"--bootstrap.servers <kafka brokers> " +
"--zookeeper.connect <zk quorum> --group.id <some id>");
}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
env.enableCheckpointing(5000); // create a checkpoint every 5 seconds
env.getConfig().setGlobalJobParameters(parameterTool); // make parameters available in the web interface
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
return env;
}
}
代码
package com.bigdata.flink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
public class KafkaExample {
public static void main(String[] args) throws Exception {
// parse input arguments
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
StreamExecutionEnvironment env = KafkaExampleUtil.prepareExecutionEnv(parameterTool);
// 消费kafka
DataStream input = env
.addSource(new FlinkKafkaConsumer("test_topic", new SimpleStringSchema(), parameterTool.getProperties()));
// 打印
input.print();
// 往kafka中写数据
FlinkKafkaProducer<String> myProducer = new FlinkKafkaProducer<>(
parameterTool.getProperties().getProperty("bootstrap.servers"), // broker list
"test_source", // target topic
new SimpleStringSchema()); // serialization schema
input.map(line -> line + "test").addSink(myProducer);
env.execute("Modern Kafka Example");
}
}
配置
--input-topic test_topic --output-topic test_source --bootstrap.servers master:9092 --zookeeper.connect master:2181 --group.id test_group
往kafka topic中放数据
/opt/cloudera/parcels/KAFKA/bin/kafka-console-producer --broker-list master:9092 --topic test_topic
输出
消费flink程序写入的topic
/opt/cloudera/parcels/KAFKA/bin/kafka-console-consumer --bootstrap-server master:9092 --topic test_source
输出

4.数据重复问题
Flink自带Exactly Once语义,对于支持事务的存储,可以实现数据的不重不丢。Kafka在0.11.0版本的时候,支持了事务,参考:【干货】Kafka 事务特性分析
要使用Flink实现Exactly Once,需要注意,参考:Flink exactly-once 实战笔记
1. kafka的Producer写入数据的时候需要通过事务来写入,即使用Exactly-once语义的FlinkKafkaProducer;
2. 是kafka的consumer消费的时候,需要给消费者加上参数isolation.level=read_committed来保证未commit的消息对消费者不可见
Kafka端到端一致性需要注意的点,参考:Flink Kafka端到端精准一致性测试
1. Flink任务需要开启checkpoint配置为CheckpointingMode.EXACTLY_ONCE
2. Flink任务FlinkKafkaProducer需要指定参数Semantic.EXACTLY_ONCE
3. Flink任务FlinkKafkaProducer配置需要配置transaction.timeout.ms,checkpoint间隔(代码指定)<transaction.timeout.ms(默认为1小时)<transaction.max.timeout.ms(默认为15分钟)
4. 消费端在消费FlinkKafkaProducer的topic时需要指定isolation.level(默认为read_uncommitted)为read_committed
关于flink读写kafka Exactly Once的最佳实践,参考:Best Practices for Using Kafka Sources/Sinks in Flink Jobs
1. 在FlinkKafkaProducer开启了Semantic.EXACTLY_ONCE之后,如果遇到一下报错
Unexpected error in InitProducerIdResponse; The transaction timeout is larger than the maximum value allowed by the broker (as configured by max.transaction.timeout.ms).
则需要调小Producer的transaction.timeout.ms参数,其默认值为1 hour,比如调整成
transaction.timeout.ms=300000
2. 开启Semantic.EXACTLY_ONCE之后,需要保证transactional.id是唯一的
3. 设置做checkpoint的间隔时间,比如
StreamExecutionEnvironment env = ...; env.enableCheckpointing(1000); // unit is millisecond
4. 并发checkpoint,默认的FlinkKafkaProducer有一个5个KafkaProducers的线程池,支持并发做4个checkpoint
5. 需要注意kafka connect的版本
6. 当kafka集群不可用的时候,避免刷日志
min.insync.replicas
reconnect.backoff.max.ms reconnect.backoff.ms
关于kafka的事务机制和read_committed,参考:Kafka Exactly-Once 之事务性实现
5.flink读写kafka端到端exactly once
socket stream 写入数据 -> flink读取socket流式数据 -> 事务写kafka -> flink使用isolation.level=read_committed来消费kafka数据 -> console打印数据
由于使用了checkpoint机制,在消费kafka的时候,只有当flink周期性做checkpoint成功后,才会提交offset;如果当flink任务挂掉的时候,对于未提交事务的消息,消费者是不可见的
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/12497787.html

