Yarn学习笔记——MR任务
1.hive sql提交到yarn上面执行之后,将会成为MR任务执行
正在运行的MR任务的application查看的url,不同类似的任务查看的url可能会不同,比如Spark,Flink等
http://xxxx:8088/cluster/app/application_158225xxxxx_0316

运行结束的MR任务的查看url
http://xxxx:19888/jobhistory/job/job_1582255xxxx_0316
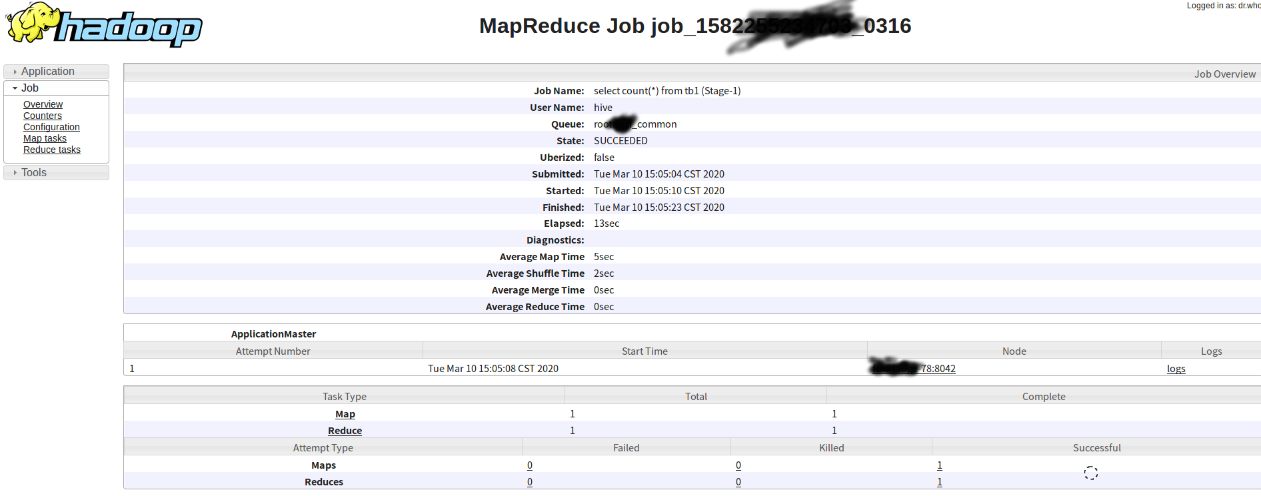
具体hive sql的具体执行用户,sql内容等信息到配置进行查看
http://xxxx:19888/ws/v1/history/mapreduce/jobs/job_15822552xxxxx_0298/conf
如执行用户hive.server2.proxy.user

具体执行的sql语句hive.query.string

Application和Job的区别
Job:源于Hadoop 1.0的概念,一般指用户提交的MapReduce作业。当然,具体到客户端提交的spark作业,也会根据action,将作业的DAG划分成多个job。这个以后再具体说。 Application:从Hadoop 2.0引入,即可以指传统的MapReduce作业,也可以指其它计算框架的作业,如Spark、Storm作业等,甚至是一系列作业组成的有向无环图。
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/12455825.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号