
Hive学习笔记——metadata
Hive结构体系
https://blog.csdn.net/zhoudaxia/article/details/8855937
依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>1.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.1.0</version>
</dependency>
有2种方法可以取得hive的元数据
1.使用hive的jdbc接口的getMetaData方法来获取hive表的相关元信息
import java.sql.*;
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection connection = DriverManager.getConnection("jdbc:hive2://xxxxx:10000", "xxxx", "xxxx");
Statement statement = connection.createStatement();
DatabaseMetaData meta = connection.getMetaData();
参考
https://blog.csdn.net/u010368839/article/details/76358831
hive metadata源码解析可以参考
https://cloud.tencent.com/developer/article/1330250
hive thrift接口可以参考
注意代码中的hive-site.xml和集群上面的保持一致
否则会报错,例如
set_ugi() not successful, Likely cause: new client talking to old server. Continuing without it.
获得表的信息接口,指定tableNamePattern为hive表名
ResultSet tableRet = meta.getTables(null, "%", "ads_nsh_trade", new String[]{"TABLE"});
while (tableRet.next()) {
System.out.println("TABLE_CAT:" + tableRet.getString("TABLE_CAT"));
System.out.println("TABLE_SCHEM:" + tableRet.getString("TABLE_SCHEM"));
System.out.println("TABLE_NAME => " + tableRet.getString("TABLE_NAME"));
System.out.println("table_type => " + tableRet.getString("table_type"));
System.out.println("remarks => " + tableRet.getString("remarks"));
System.out.println("type_cat => " + tableRet.getString("type_cat"));
System.out.println("type_schem => " + tableRet.getString("type_schem"));
System.out.println("type_name => " + tableRet.getString("type_name"));
System.out.println("self_referencing_col_name => " + tableRet.getString("self_referencing_col_name"));
System.out.println("ref_generation => " + tableRet.getString("ref_generation"));
}
其中的参数可以是
table_cat, table_schem, table_name, table_type, remarks, type_cat, type_schem, type_name, self_referencing_col_name, ref_generation
如果填写不正确将会抛出异常
java.sql.SQLException: Could not find COLUMN_NAME in [table_cat, table_schem, table_name, table_type, remarks, type_cat, type_schem, type_name, self_referencing_col_name, ref_generation] at org.apache.hive.jdbc.HiveBaseResultSet.findColumn(HiveBaseResultSet.java:100) at org.apache.hive.jdbc.HiveBaseResultSet.getString(HiveBaseResultSet.java:541)
输出的结果
TABLE_CAT: TABLE_SCHEM:tmp TABLE_NAME => ads_nsh_trade table_type => TABLE remarks => ??????????? type_cat => null type_schem => null type_name => null self_referencing_col_name => null ref_generation => null TABLE_CAT: TABLE_SCHEM:default TABLE_NAME => ads_nsh_trade table_type => TABLE remarks => null type_cat => null type_schem => null type_name => null self_referencing_col_name => null ref_generation => null
如果再指定schemaPattern为hive库名
ResultSet tableRet = meta.getTables(null, "default", "ads_nsh_trade", new String[]{"TABLE"});
while (tableRet.next()) {
System.out.println("TABLE_CAT:" + tableRet.getString("TABLE_CAT"));
System.out.println("TABLE_SCHEM:" + tableRet.getString("TABLE_SCHEM"));
System.out.println("TABLE_NAME => " + tableRet.getString("TABLE_NAME"));
System.out.println("table_type => " + tableRet.getString("table_type"));
System.out.println("remarks => " + tableRet.getString("remarks"));
System.out.println("type_cat => " + tableRet.getString("type_cat"));
System.out.println("type_schem => " + tableRet.getString("type_schem"));
System.out.println("type_name => " + tableRet.getString("type_name"));
System.out.println("self_referencing_col_name => " + tableRet.getString("self_referencing_col_name"));
System.out.println("ref_generation => " + tableRet.getString("ref_generation"));
}
输出结果
TABLE_CAT: TABLE_SCHEM:default TABLE_NAME => ads_nsh_trade table_type => TABLE remarks => null type_cat => null type_schem => null type_name => null self_referencing_col_name => null ref_generation => null
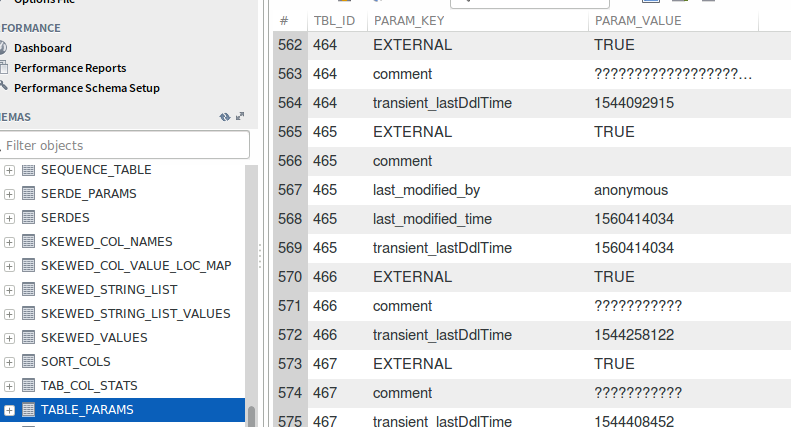
在hive的元数据表中,表的信息主要在TBLS和TABLE_PARAMS这两张表中
参考
https://blog.csdn.net/haozhugogo/article/details/73274832
比如TBLS表
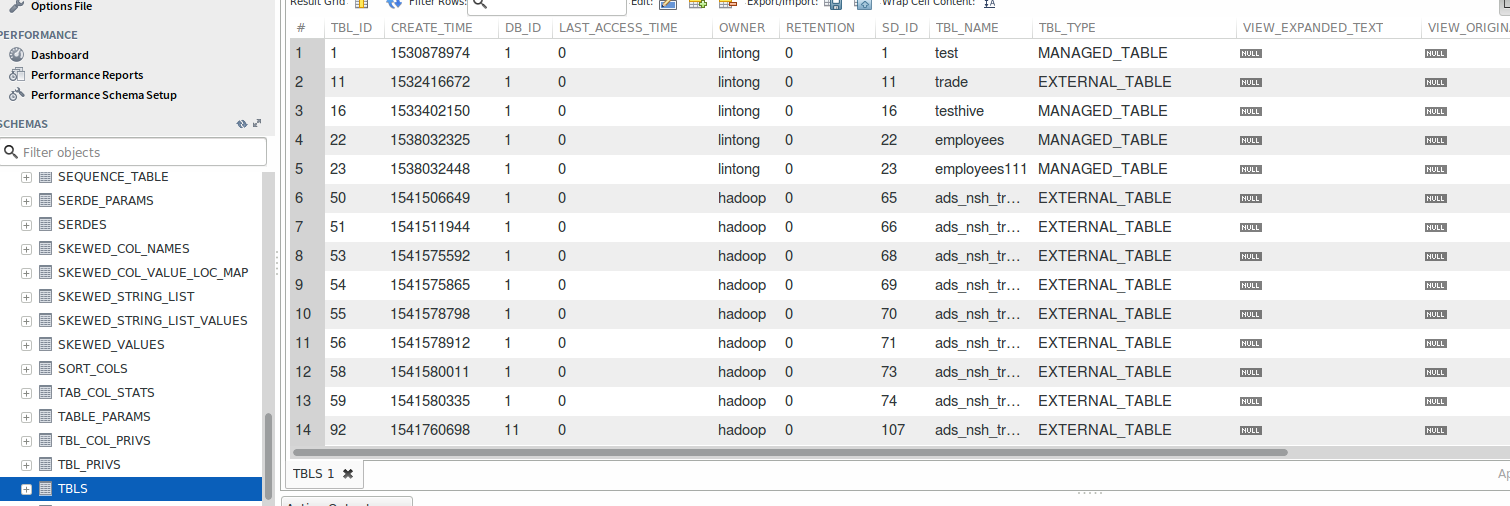
和TABLE_PARAMS表
获得表的字段信息的接口
ResultSet rs1 = meta.getColumns("%", "default", "my_table_xxx", "%"); while (rs1.next()) { String tableCat = rs1.getString("table_cat"); String tableSchem = rs1.getString("table_schem"); String tableName = rs1.getString("table_name"); String columnName = rs1.getString("COLUMN_NAME"); String columnType = rs1.getString("TYPE_NAME"); String remarks = rs1.getString("REMARKS"); int datasize = rs1.getInt("COLUMN_SIZE"); int digits = rs1.getInt("DECIMAL_DIGITS"); int nullable = rs1.getInt("NULLABLE"); System.out.println(tableCat + " " + tableSchem + " " + tableName + " " + columnName + " " + columnType + " " + datasize + " " + digits + " " + nullable + " " + remarks); }
其中的参数可以是
table_cat, table_schem, table_name, column_name, data_type, type_name, column_size, buffer_length, decimal_digits, num_prec_radix, nullable, remarks, column_def, sql_data_type, sql_datetime_sub, char_octet_length, ordinal_position, is_nullable, scope_catalog, scope_schema, scope_table, source_data_type, is_auto_increment
输出的结果
null default ads_nsh_trade test_string STRING 2147483647 0 1 string?????? null default ads_nsh_trade test_boolean BOOLEAN 0 0 1 boolean?????? null default ads_nsh_trade test_short SMALLINT 5 0 1 short?????? null default ads_nsh_trade test_double DOUBLE 15 15 1 double?????? null default ads_nsh_trade test_byte TINYINT 3 0 1 byte?????? null default ads_nsh_trade test_list array<string> 0 0 1 list<String>???? null default ads_nsh_trade test_map map<string,int> 0 0 1 map<String,Int>???? null default ads_nsh_trade test_int INT 10 0 1 int?????? null default ads_nsh_trade test_set array<bigint> 0 0 1 set<Long>?????? null default ads_nsh_trade col_name DECIMAL 10 2 1 null null default ads_nsh_trade col_name2 DECIMAL 10 2 1 null null default ads_nsh_trade test_long BIGINT 19 0 1 null null tmp ads_nsh_trade test_boolean BOOLEAN 0 0 1 boolean?????? null tmp ads_nsh_trade test_short SMALLINT 5 0 1 short?????? null tmp ads_nsh_trade test_double DOUBLE 15 15 1 double?????? null tmp ads_nsh_trade test_byte TINYINT 3 0 1 byte?????? null tmp ads_nsh_trade test_list array<string> 0 0 1 list<String>???? null tmp ads_nsh_trade test_map map<string,int> 0 0 1 map<String,Int>???? null tmp ads_nsh_trade test_int INT 10 0 1 int?????? null tmp ads_nsh_trade test_set array<bigint> 0 0 1 set<Long>?????? null tmp ads_nsh_trade test_long BIGINT 19 0 1 null null tmp ads_nsh_trade test_string STRING 2147483647 0 1 null
如果读取hive元数据的时候遇到下面报错,hive的schema在外部系统,且使用hive2的版本
org.apache.hive.service.cli.HiveSQLException: MetaException(message:java.lang.UnsupportedOperationException: Storage schema reading not supported) at org.apache.hive.jdbc.Utils.verifySuccess(Utils.java:267) at org.apache.hive.jdbc.Utils.verifySuccess(Utils.java:258) at org.apache.hive.jdbc.HiveDatabaseMetaData.getColumns(HiveDatabaseMetaData.java:226) at com.xxx.data.udf.ShowColumnsUDF.evaluate(ShowColumnsUDF.java:25) at com.xxx.data.udf.ShowColumnsUDFTest.evaluate(ShowColumnsUDFTest.java:13) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50) at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12) at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47) at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17) at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57) at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290) at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71) at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288) at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58) at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268) at org.junit.runners.ParentRunner.run(ParentRunner.java:363) at org.junit.runner.JUnitCore.run(JUnitCore.java:137) at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:69) at com.intellij.rt.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:33) at com.intellij.rt.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:221) at com.intellij.rt.junit.JUnitStarter.main(JUnitStarter.java:54) Caused by: org.apache.hive.service.cli.HiveSQLException: MetaException(message:java.lang.UnsupportedOperationException: Storage schema reading not supported) at org.apache.hive.service.cli.operation.GetColumnsOperation.runInternal(GetColumnsOperation.java:213) at org.apache.hive.service.cli.operation.Operation.run(Operation.java:247)
解决的方法是在 hive-site.xml 中添加
metastore.storage.schema.reader.impl=org.apache.hadoop.hive.metastore.SerDeStorageSchemaReader
2.使用hive的thrift接口来操作hive元数据
Configuration config = new Configuration();
config.set("hive.metastore.uris", "thrift://xxxx:9083");
config.set("javax.security.auth.useSubjectCredsOnly", "false");
HiveConf hConf = new HiveConf(config, HiveConf.class);
HiveMetaStoreClient hiveMetaStoreClient = new HiveMetaStoreClient(hConf);
List<FieldSchema> list = hiveMetaStoreClient.getSchema("default", "avro_test_dwd2");
for (FieldSchema schema: list) {
System.out.println(schema);
}
输出
FieldSchema(name:string1, type:string, comment:) FieldSchema(name:int1, type:int, comment:) FieldSchema(name:tinyint1, type:int, comment:) FieldSchema(name:smallint1, type:int, comment:) FieldSchema(name:bigint1, type:bigint, comment:) FieldSchema(name:boolean1, type:boolean, comment:) FieldSchema(name:float1, type:float, comment:) FieldSchema(name:double1, type:double, comment:) FieldSchema(name:list1, type:array<string>, comment:) FieldSchema(name:map1, type:map<string,int>, comment:) FieldSchema(name:struct1, type:struct<sint:int,sboolean:boolean,sstring:string>, comment:) FieldSchema(name:enum1, type:string, comment:) FieldSchema(name:nullableint, type:int, comment:) FieldSchema(name:ds, type:string, comment:null)
当查看hive表分区的参数的时候,有时numRows和rawDataSize会显示-1,这是hive metastore中没有相应的数据,
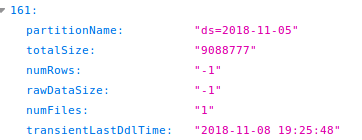
需要执行如下命令重新计算
ANALYZE TABLE xxx.xxx PARTITION(ds='2019-02-28') COMPUTE STATISTICS;
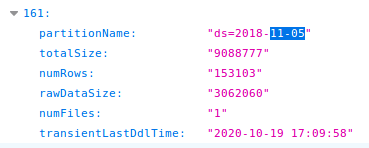
如果要刷新整个分区表的话
ANALYZE TABLE xxxx.xxxx PARTITION(ds) COMPUTE STATISTICS;
就能刷新整个表的metadata


使用NOSCAN将会直接查询元数据,不会重新计算
ANALYZE TABLE xxx.xxx PARTITION(ds) COMPUTE STATISTICS NOSCAN;
输出
INFO : Starting task [Stage-1:STATS] in serial mode
INFO : Partition xxx.xxx{ds=2018-08-31} stats: [numFiles=1, numRows=86, totalSize=15358, rawDataSize=1032]
INFO : Partition xxx.xxx{ds=2018-09-01} stats: [numFiles=1, numRows=728, totalSize=114974, rawDataSize=8736]
INFO : Partition xxx.xxx{ds=2018-09-02} stats: [numFiles=1, numRows=787, totalSize=124251, rawDataSize=9444]
INFO : Partition xxx.xxx{ds=2018-09-03} stats: [numFiles=1, numRows=670, totalSize=106113, rawDataSize=8040]
INFO : Partition xxx.xxx{ds=2018-09-04} stats: [numFiles=1, numRows=594, totalSize=93643, rawDataSize=7128]
INFO : Partition xxx.xxx{ds=2018-09-05} stats: [numFiles=1, numRows=627, totalSize=98089, rawDataSize=7524]
INFO : Partition xxx.xxx{ds=2018-09-06} stats: [numFiles=1, numRows=558, totalSize=88352, rawDataSize=6696]
对于hiveMetaStoreClient的dropPartition方法,有4个参数,databaseName,tableName,partitionName,deleteData
对于hive的内部表,如果deleteData为false,只会删除hive表的分区,不会删除hdfs上的数据
deleteData为true,两个都会删除
如果找不到该分区,会抛出
NoSuchObjectException(message:partition values=[2020-07-14]
对于hive的外部表,无论deleteData为false还是true,都不会删除hdfs上的数据
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/11451946.html

