
Hadoop学习笔记——HDFS
1.查看hdfs文件的block信息
不正常的文件
hdfs fsck /logs/xxx/xxxx.gz.gz -files -blocks -locations Connecting to namenode via http://xxx-01:50070/fsck?ugi=xxx&files=1&blocks=1&locations=1&path=%2Flogs%2Fxxx%2Fxxx%2F401294%2Fds%3Dxxxx-07-14%2Fxxx.gz.gz FSCK started by xxxx (auth:KERBEROS_SSL) from /10.90.1.91 for path xxxxx.gz.gz at Mon Jul 15 11:44:13 CST 2019 Status: HEALTHY Total size: 0 B (Total open files size: 194 B) Total dirs: 0 Total files: 0 Total symlinks: 0 (Files currently being written: 1) Total blocks (validated): 0 (Total open file blocks (not validated): 1) Minimally replicated blocks: 0 Over-replicated blocks: 0 Under-replicated blocks: 0 Mis-replicated blocks: 0 Default replication factor: 3 Average block replication: 0.0 Corrupt blocks: 0 Missing replicas: 0 Number of data-nodes: 99 Number of racks: 3 FSCK ended at Mon Jul 15 11:44:13 CST 2019 in 0 milliseconds
正常的文件
Connecting to namenode via http://xxx:50070/fsck?ugi=xxx&files=1&blocks=1&locations=1&path=%2Fxxx%2Fxxx%2Fxxx%2F401294%2Fds%3Dxxx-07-14%2Fxx.gz FSCK started by xxxx (auth:KERBEROS_SSL) from /10.90.1.91 for path /logs/xxxx.gz at Mon Jul 15 11:46:12 CST 2019 /logs/xxxx.gz 74745 bytes, 1 block(s): OK 0. BP-1760298736-10.90.1.6-1536234810107:blk_1392467116_318836510 len=74745 Live_repl=3 [DatanodeInfoWithStorage[10.90.1.99:1004,DS-9d465b1f-943f-4716-bce0-8b36e5631b4a,DISK], DatanodeInfoWithStorage[10.90.1.216:1004,DS-160924c6-4cd7-4822-93c0-9ac9cf9c5784,DISK], DatanodeInfoWithStorage[10.90.1.191:1004,DS-d0a2e418-610f-4bef-8f1d-4ce045533656,DISK]] Status: HEALTHY Total size: 74745 B Total dirs: 0 Total files: 1 Total symlinks: 0 Total blocks (validated): 1 (avg. block size 74745 B) Minimally replicated blocks: 1 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 3 Average block replication: 3.0 Corrupt blocks: 0 Missing replicas: 0 (0.0 %) Number of data-nodes: 99 Number of racks: 3 FSCK ended at Mon Jul 15 11:46:12 CST 2019 in 1 milliseconds
2.修复hdfs文件命令
hdfs debug recoverLease -path /logs/xxxx.gz.gz -retries 3
修复之后
hdfs fsck /logs/xxx.gz.gz -files -blocks -locations Connecting to namenode via http://xxx-01:50070/fsck?ugi=xxx&files=1&blocks=1&locations=1&path=%2Flogs%2Fnsh%2Fjson%2F401294%2Fds%3D2019-07-14%2Fxxx.gz.gz FSCK started by xxx (auth:KERBEROS_SSL) from /10.90.1.91 for path /logs/xxxx.gz.gz at Mon Jul 15 11:48:01 CST 2019 /logs/xxxx.gz.gz 67157 bytes, 1 block(s): OK 0. BP-1760298736-10.90.1.6-1536234810107:blk_1392594522_319757834 len=67157 Live_repl=3 [DatanodeInfoWithStorage[10.90.1.213:1004,DS-6aee5c90-c834-475e-8f20-7a0f8bd8d315,DISK], DatanodeInfoWithStorage[10.90.1.207:1004,DS-cd79bacc-89ff-4fb3-82b5-79341391ae8d,DISK], DatanodeInfoWithStorage[10.90.1.97:1004,DS-ba5953f8-c0c3-444a-8996-3bcfa1bcf851,DISK]] Status: HEALTHY Total size: 67157 B Total dirs: 0 Total files: 1 Total symlinks: 0 Total blocks (validated): 1 (avg. block size 67157 B) Minimally replicated blocks: 1 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 3 Average block replication: 3.0 Corrupt blocks: 0 Missing replicas: 0 (0.0 %) Number of data-nodes: 99 Number of racks: 3 FSCK ended at Mon Jul 15 11:48:01 CST 2019 in 1 milliseconds
3. 其他博客:Hadoop学习笔记—HDFS
4. 一些脚本
遍历hdfs路径,并截取最后一层子路径,其中 ##*/ 是截取 / 后面的字符,参考:Shell当中的字符串切割
#!/usr/bin/env bash
function grep_dir(){
kinit -kt xxx.keytab xxx
# 遍历hdfs路径
for file in `hadoop fs -ls /logs/xxxx | awk '{print $8}'`
do
echo $file" "${file##*/}
done
}
grep_dir
输出
/logs/xxxx/ds=2019-04-01 ds=2019-04-01 /logs/xxxx/ds=2019-04-02 ds=2019-04-02 /logs/xxxx/ds=2019-04-03 ds=2019-04-03 /logs/xxxx/ds=2019-04-04 ds=2019-04-04 /logs/xxxx/ds=2019-04-05 ds=2019-04-05 /logs/xxxx/ds=2019-04-06 ds=2019-04-06 /logs/xxxx/ds=2019-04-07 ds=2019-04-07
遍历hdfs路径,并截取中间层路径,其中
logid=`echo $file | awk -F "/" '{print $5}'`
是使用 / 切分后,取对应数组第5个位置的字符串
#!/usr/bin/env bash
function grep_dir(){
kinit -kt xxxx.keytab xxxx
# 遍历hdfs路径
for file in `hadoop fs -ls /logs/xxx/json/status-1 | awk '{print $8}'`
do
echo $file" "${file##*/}
logid=`echo $file | awk -F "/" '{print $5}'`
echo $logid
done
}
grep_dir
输出
/logs/xxx/json/status-1/ds=2021-04-18 ds=2021-04-18 status-1 /logs/xxx/json/status-1/ds=2021-04-19 ds=2021-04-19 status-1 /logs/xxx/json/status-1/ds=2021-04-20 ds=2021-04-20 status-1
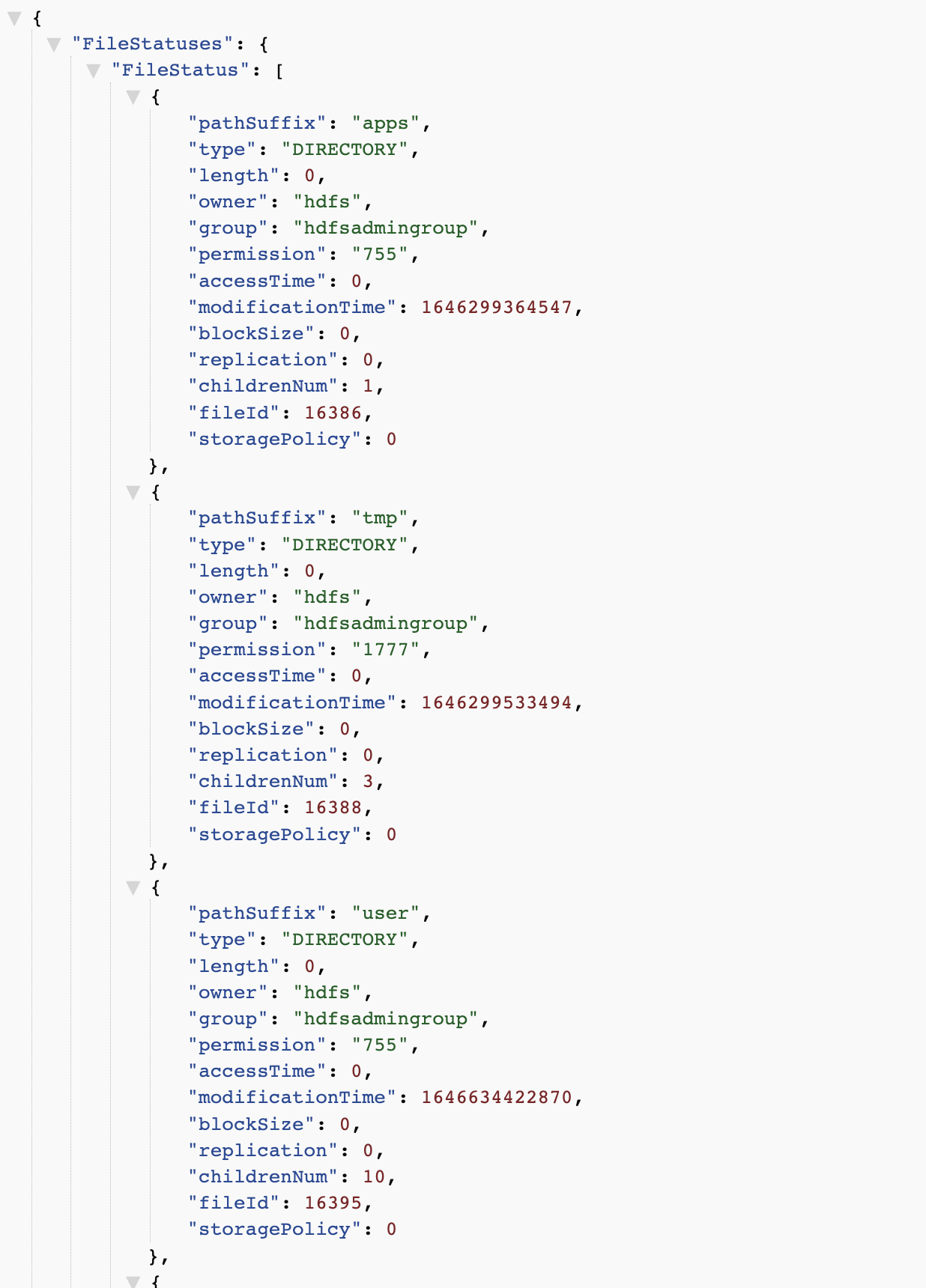
5.webhdfs
http://master:14000/webhdfs/v1/?op=liststatus&user.name=hadoop
本文只发表于博客园和tonglin0325的博客,作者:tonglin0325,转载请注明原文链接:https://www.cnblogs.com/tonglin0325/p/11188000.html

