
Hibernate详讲
一 概述
1.JPA
Java Persistence API,是Java EE为ORM框架定义的规范,任何使用java语言的ORM框架都必须实现该规范。Hibernate/Mybatis都是是JPA的一种实现。
2.ORM
Object Relational Mapping,对象到关系的映射,在关系型数据库与对象之间建立映射关系,以实体对象操作关系型数据库。
3.持久化
将对数据库的操作永久地反映到数据库中的过程叫做持久化。
4.持久层框架
封装了对数据库进行持久化操作的框架叫做持久化框架。所谓框架就是在内部实现了一些常用的基本操作,提供简单的接口,缩减操作步骤,而且扩展了功能。
二 数据库连接池
1.背景
数据库连接是一个极其有限的宝贵资源,在Web应用程序中表现得尤为突出。Web应用访问量大,而数据库支持的并发连接数目是有限的,连接越多,速度越慢,降低了用户体验。
在数据库连接池产生以前,访问数据库需要先建立连接,访问结束后关闭连接,下次需要时再重复创建与关闭过程,而数据库连接的创建与关闭本身消耗大量的系统资源,这时产生了共享数据库连接的思想,数据库连接池应运而生。
2.数据库连接池的含义
- 数据库连接池提供与管理用于访问数据库的连接。
- 数据库连接池在初始化阶段会创建一定数量的数据库连接,投放到数据连接池中。
- 用户访问数据库时不创建连接,而是从数据库连接池中获取连接,访问完毕后,不关闭连接,而是将连接归还连接池,以实现连接的重复使用。
3.常用数据连接池
- C3P0是一种开放源代码的JDBC连接池。
- DBCP。
4.配置数据源
Hibernate框架推荐使用C3P0:
<property name="connection.provider_class">org.hibernate.connection.C3P0ConnectionProvider</property>
三 Hibernate简介
1.基本流程
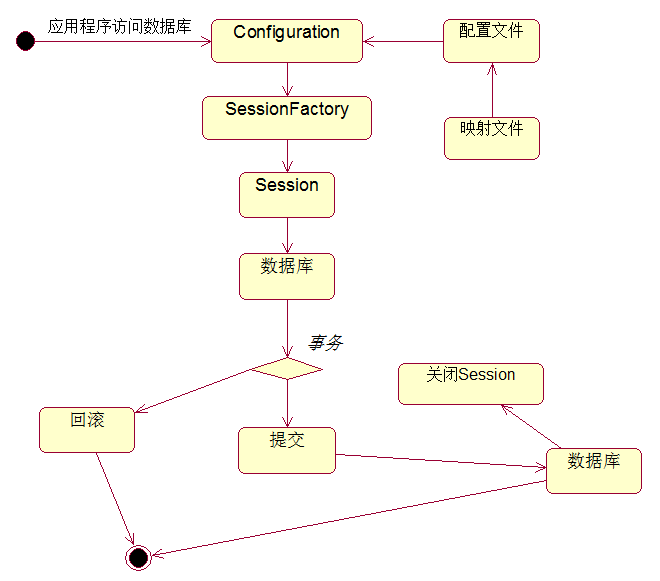
2.Configuration
负责加载配置文件,启动Hibernate。配置文件的默认名称为“hibernate.cfg.xml”,放在类路径下。
3.SessionFactory
负责创建Session对象,保存了当前数据库中所有的映射关系,线程安全。重量级对象,初始化过程耗费大量的资源,因此在应用程序中应避免创建多个SessionFactory对象。
4.Session
⑴含义
代表应用程序与数据库的一次会话,是Hibernate中持久化操作的核心,直接负责所有的持久化操作。
⑵非线程安全
session对象线程不安全,应避免多个线程共享一个Session对象。多个线程共享一个session对象,可能会因为session缓存的存在出现数据泄露,或者一个线程关闭了session对象,另一个线程出现异常。
⑶依赖事务
Session只能在事务内部运行,即未开启事务,无法运行Session。
⑷创建
Session session=sessionFactory.openSession();
Session session=sessionFactory.getCurrentSession();
- 第一种方式不需要配置,直接使用,第二种方式必须在配置文件中配置,配置如下:
<property name="current_session_context_class">thread</property>
- openSession每调用一次创建一个Session对象,getCurrentSession在同一个线程内部获得的是同一个Session对象。
- 第二种方式创建的对象与线程绑定,第一种未与线程绑定。第二种方式创建的对象在事务提交或者回滚后自动关闭,第一种方式创建的连接必须手动关闭。
⑸关闭
- Session一旦被关闭,就与线程解除了绑定关系,下一次通过该线程获得的是不同的Session对象。
- Session关闭以后,断开了与数据库的连接,就无法通过该Session对象访问数据库。
Session一旦关闭,就标志着应用程序与数据库的一次会话结束,再次通信需要建立新的会话。
5.主键生成策略
| 生成策略 | 含义 | 维护方 |
| increment | 获取数据库中当前主键的最大值,加1作为新数据的主键 | Hibernate |
| identity | 按照自增方式生成主键 | 数据库 |
| native | 从底层数据库支持的主键生成策略中选择 | 数据库 |
| assigned | 由程序员手动生成主键 | 程序员 |
| sequence | 基于sequence表生成主键 | 数据库 |
| uuid | 生成一个全球唯一的32位主键 | 数据库 |
| foreign | 根据另一张表的主键生成主键,形成一对一主键关联 | Hibernate |
四 持久化对象的状态

1.瞬时状态
对象被创建、未被Session引用时的状态,与数据库中的数据无连接,数据库不存在对应数据,一旦被Session通过save或者saveOrUpdate调用方法转化为持久化状态。
2.持久化状态
对象被session引用,出现在session缓存时处于持久化状态。对象只有处于持久化状态,对其进行的操作才会持久到数据库中。
3.脱管状态
当Session对象关闭以后,持久化对象由持久状态转化为脱管状态,持久化对象处在脱管状态下仍然与数据库中的数据存在关联,数据库中存在对应数据,通过update或者saveOrUpdate转化为持久化状态。
脱管状态与瞬时状态对比:
- 相同点:都不在session缓存中。
- 不同点:脱管状态的对象确定存在于数据库中,主要用于修改数据库中的数据,通过update转化为持久化状态;瞬时状态的对象不存在于数据库中,主要用于插入数据,通过save转化为持久化状态。
4.集合角度
假如把关系型数据库中的表看做一个持久化类,每一行记录都是一个该类的对象,即持久化对象,一个对象如果在集合之外,则处于瞬时状态;在集合之内并且正在被Session调用,处在持久化状态;如果Session关闭,处在脱管状态。
5.内存地址
对象的状态发生改变时,对象在内存中的地址并未发生改变,仍然是同一对象,只是对象与数据库的关系发生改变。
五 持久化操作
1.一般步骤
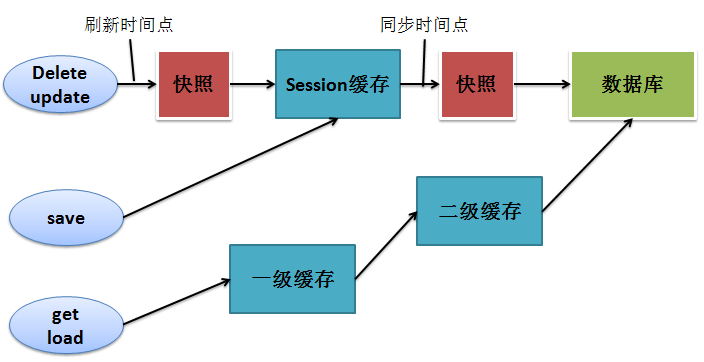
2.插入数据
session.save(Object obj);//底层生成一条insert语句
3.查询数据
⑴get
Object obj=(Object)session.get(Object.class,Serializable id);//底层生成一条select语句
⑵load
Object obj=(Object)session.get(Object.class,Serializable id);//底层生成一条select语句
返回对象的代理,在对象被调用时,才向数据库发送SQL语句。
4.删除数据
Object obj=session.get(Object.class,Serializable id); session.delete(obj);//底层生成一条delete语句
5.修改数据
Object obj=session.get(Object.class,Serializable id); obj.setter();//底层生成一条update语句
6.其他方法
- clear():清空Session缓存,取消所有未执行的操作。
- evict():立即将Session缓存中对象的引用变量赋值为null,不会生成SQL语句。
7.操作的本质
假定session缓存中保存的是对象本身,而不是对象的引用,那么清空session缓存,会销毁对象,测试一下:
@Test
public void testClear() {
Session session = HibernateUtils.getSession();
try {
session.beginTransaction();
Student stu = session.get(Student.class, 1);
System.out.println("stu=" + stu);
session.clear();
System.out.println("stu=" + stu);
} catch (Exception e) {
e.printStackTrace();
session.getTransaction().rollback();
}
}
输出:

很明显,session缓存清空以后,依然可以输出对象的详情,说明对象依然存在,从而得出结论:session缓存中保存的不是对象,而是对象的引用。

加载完成以后,在session缓存中建立一个对象的引用变量,并且使引用变量stu也指定该对象。
- get()/load()/save(stu):在session缓存中建立引用变量stu,指向内存中的对象obj。
- delete(stu):不是从内存中删除对象obj,而是使session缓存中的引用变量“stu0=null”。
- update(stu):对数据库的修改直接来源于session缓存,所以在执行修改操作前必须保存session缓存中存在该对象,即session缓存中存在对象的引用。
六 同步时间点与刷新时间点
1.同步时间点
事务提交是Hibernate中唯一的同步时间点,事务提交时将Session缓存中的数据同步到数据库。
2.刷新时间点
遇到Query查询、flush方法、事务提交时,执行删除与修改操作更新session缓存中的内容,只有在事务提交时才同步到数据库。
3.本质
同步时间点与刷新时间点所做的工作就是将以面向对象形式对数据的操作转化为以SQL形式对数据库的操作,因为无论框架怎么封装,底层数据库所能识别与执行的命令只有SQL语句,框架提供了面向对象这种相对简单的操作数据库的方式,底层再将这种方式转化为数据库接受的方式。
刷新时间点与同步时间点就是启动转化的时机。刷新时间点将转化的SQL语句写入session缓存,同步时间点将转化的SQL语句写入数据库。

4.flush
修改缓存中已有的对象,比如修改对象属性值,删除对象,不会清空缓存,不会同步到数据库,不影响那些与缓存内容无关的操纵,比如save\get操作不受flush影响,立即执行。
5.快照约束
同步时间点与刷新时间点都受快照的约束。
七 缓存
1.Hibernate缓存结构
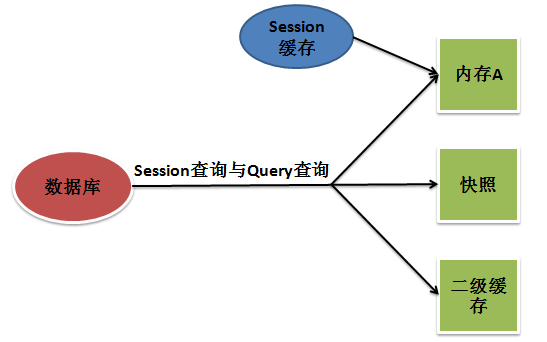
将从数据库中加载的对象分别保存在内存的3个区域,各区域之间相互独立,互不影响。
2.一级缓存与二级缓存内容结构
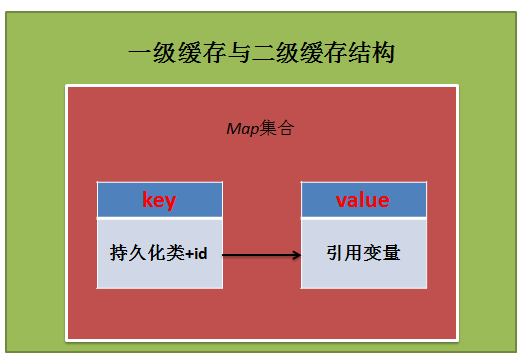
一级缓存与二级缓存中的内容都以Map集合的形式存储,key是持久化类与唯一性标识(id)的组合,value是对象的引用变量。
判断一级缓存或者二级缓存中是否存在一个对象的依据是,该对象的持久化类与唯一性标识构成的组合是否存在于Map集合中。
3.一级缓存
⑴生命周期
一级缓存是Session级的,生命周期与Session相同,随Session的创建而创建,随Session的销毁而销毁。
⑵内部共享
Session缓存中的数据在Session内部共享,Session之间不共享。
4.快照
⑴作用
快照内存中一块存储区域,提供了一种修改审查机制。
⑵基本原理
事务提交时,将缓存中准备同步到数据库中的内容与快照中的内容进行对比,不一致才同步到数据库,避免了对数据库不必要的访问,减轻了数据库的负担。
5.二级缓存
⑴作用范围
二级缓存即SessionFactory缓存,为所有Session对象共享。
⑵配置
Hibernate本身并未实现二级缓冲,需要使用第三方插件,其中一种插件为EHCache,注册后才可使用
- 开启二级缓存:
-
<property name="hibernate.cache.use_second_level_cache">true</property>
- 二级缓存对应内存一块区域,需要指明该区域的管理者,即二级缓存提供商:
-
<property name="cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
- 在src目录下加入缓冲配置文件:ehcache.xml。
实体类只有在二级缓存中设定了使用策略之后才可以缓存在二级缓存中,设定使用策略有两种方式:
- 在映射文件中配置:
-
<class> <cache usage="read-only"/> </class>
- 在配置文件中配置:
-
<class-cache class=""usage=""/>
6.Query缓存
⑴什么是Query缓存?
用来存储Query查询结果的内存区域,独立于一级与二级缓存,供Query查询使用。
⑵开启
Hibernate默认关闭了Query缓存,如果需要使用,需要在配置文件中开启:
<property name="cache.use_query_cache">true</property>
⑶存储结构
Query缓存不仅包含查询结果,而且包含hql语句,搜索Query缓存时,首先对比hql语句,Query缓存只有对完全相同的hql语句可见。
⑷使用
Query q=session.createQuery(hql); List list=q.setCacheable(true).list();
八 实体关联关系映射
1.多对一单向关联
在多的一段添加外键:
<many-to-one name="属性名"class="一方全限定性类名"> <column name="在本表中添加的外键字段">//多的一方表中外键名 </many-to-one>
2.多对一双向关联
//多方映射文件 <many-to-one name="属性名" class="一方"> <column name="外键"> </many-to-one> //一方映射文件 <set name="属性名" inverse="true"> <key column="外键"/> <one-to-many class="多方"/> </set>
- inverse:指明关联关系由哪一方控制,关联关系是通过外键建立起来的,因此维护关联关系就是维护外键,默认为false,双方都可控制,有可能导致数据重复;取值true,由另一方维护关联关系。
- 没有维护权的一方尝试维护关联关系时,无法修改外键字段。
- 为了防止出现双方都放弃维护权的情况,只有一方才有权利设置维护权。
- 在MySQL中关联关系只能由父表维护,在Hibernate中子表也可以维护关联关系,底层实现也是遵循MySQL规则的。
3.一对一主键关联
一个实体与另一个实体一一对应,可以通过主键关联实现这种关联关系,形成表与表之间的一对一主键关联。也可以在一张表中建立外键,外键字段唯一,引用另一张表的主键,形成一对一外键关联。
一对一主键关联的核心是一张表的主键由另一张表的主键生成,即从另一张表的主键中取值,相当于主键又作为外键,引用一张表的主键。
映射文件的创建:
<id> <generator class="foreign"> <param name="property">当前实体中另一个实体的引用变量</param> </generator> </id> <one-to-to name="引用变量名"class="类名"constrained="true"/>
constrained:用来设定子表与父表之间是否存在外键约束,即是否把子表的主键当做外键关联父表的主键。可取值false/true,取值为false时,两张表孤立,无任何关系,取值为true时,子表的主键引用父表的主键。一般设定为为true。
4.一对一外键关联
一对一外键关联是多对一外键关联的特例,将外键字段设定为不可重复,即由多对一外键关联转化为一对一外键关联。
<many-to-one name=""class=""unique="true"> <column name=""/> </many-to-one>
5.多对多关联
将多对多关联分解成2个一对多关联,提供第三张表作为中间表,作为多的一方。
<set name="属性名"table="tb_mid"> <key column="中间表中的外键"/> <many-to-many class=""column="关联实体在中间表中的外键"/> </set>
- 多对多关联的实现是在中间表中创建了一个联合主键,联合主键的每一个字段都是外键,分别引用一张表的主键。
- 在双向关联中,由于数据之间的相互引用,如果设置了级联删除,那么一旦删除一条数据,整个数据库中就可能被清空,因此在双向关联中尽量不设置级联删除。
6.自关联
⑴什么是自关联?
实体A与实体B的属性完全相同,其中一方包含另一方,据此创建一个实体,包含A与B双向的关联关系。
⑵目的
因为两个实体属性全相同,存在共用一张表的可能,放在一张表中不仅可以节省空间,而且可以提高查询效率。
⑶处理措施
将自关联看作多对一双向关联。
九 级联操作
1.什么是级联操作?
相关联的两方,一方为主动方,另一方为被动方,当主动方发生变动时,被动方产生同样的变动,这种变化上的关联关系叫做级联。
2.作用
一张表中的某个字段引用另一张表中的某个字段,为了保证源字段发生该表时,引用字段做出同样的改变,保证数据的正确性,可以设置级联操作。
3.cascade
在映射文件中级联属性用cascade表示,可取值:
- all:所用情况下均采用级联操作。
- none:默认情况。所用情况下均不采用级联操作。
- save-update:只有在主动方执行save或者update操作时,被动方才发生相应的改变。
- delete:只有在主动方执行delete操作时,被动方才发生相应的改变。
4.all-delete-orphan
删除与当前对象不存在关联的对象,只能从父表删除,因为可能子表中多个对象引用同一父表对象,如果从子表删除,那么子表中引用该父表的其他对象也可能被删除,而这是不期望的。
Child oneChild=session.get(xxxxx);//首先获取子对象
parentObj.remove(oneChild);//解除子对象与父对象之间的关系,将子对象从子表中删除
不设置成all-delete-orphan时,只解除关联关系,即子表中对应数据的外键为空。
十 检索优化
1.优化切入点
- 加载对象的时机,通过属性lazy设定。
- 加载对象的方式,通过属性fetch设定,取值join时采用左外连接加载,延时加载失效;取值select时,两张表分别查询。
2.多端加载优化
对一方作为主加载方加载多方的操作进行优化。
lazy可取值:
- true:延迟加载,只有在访问多端对象中的未知数据数据时才加载多端对象。
- false:在加载一段对象时,立即加载多端对象。
- extra:相比true更加延迟加载,如果当前操作能够通过其他不加载详情的方式实现,就不加载详情。
3.一端加载优化
对多方作为主加载方加载一方的操作进行优化。
lazy可取值:
- false:不采用延时加载,立即加载。
- proxy:是否立即加载由一方在映射文件中的设置决定。
4.默认情况
无论是一端加载,还是多端加载,默认采用延时加载,分别查询的方式。
十一 实体继承关系映射
1.类继承关系树映射成一张表
将存在继承关系的多个实体映射成一张表,表中既有共有字段,又有特有字段,为了表明数据从属的实体,增加一个身份标识字段:
<discriminator column="字段名"type="string">//身份标识字段,紧跟主键定义 //省略父类属性映射 <subclass name=""class=""discriminator-value="身份名"> <property name=""/>//特有字段定义 </subclass>
2.子类新增属性单独映射成一张表
父类映射成一张表,子类新增属性映射成一张表,子类主键作为外键引用父类的主键,实现表的连接:
<joined-subclass name="全限定性类名"table="子表名"> <key column="id">//在子表中增加外键,关联本表的主键,该外键同时是子表的主键 <property name=""/> </joined-class>
3.子类映射成一张独立的表
将子类继承属性与新增属性映射到一张表中,该表为子类独有。
<class name="父类"abstract="true">//因为只为子类创建表,不为父类创建表,所以将父类定义为abstract <id name="id"> <generator class="assigned"/>//主键由程序负责生成 </id> -------------------xxxxxxxxxxxxxx----------------------- <union-subclass name="子类"table="子表名"> <property name="子类新增属性名"/> </union-subclass> </class>
- 因为父类可能是一个抽象类,现实中不存在对应的对象,只是充当过渡环节,因此没有必要为父类创建表,所以将父表定义为abstract,表示不为该实体创建表。
- 主键由程序负责生成。
十二 HQL
1.什么是HQL?
Hibernate Query Language,一种完全面向对象的查询语言,查询范围是对象的集合,返回结果也是对象的集合。
2.基本语法
select obj.attr from Object obj where obj.attr xxxx group by xxxx having order by xxx;
3.基本操作
String hql="from xxxx"; Query q=session.createQuery(hql); List list=q.list();//以List集合返回查询结果
4.参数绑定机制
Hibernate参数绑定机制提供了两种占位符,不同的占位符有不同的操作:
- ?:采用索引确定占位符,索引从0开始。为占位符赋值:
-
Query.setParameter(0,"具体指");
- :parameterName:采用参数名确定占位符。为占位符赋值:
-
Query.setParameter("parameterName","具体指");
5.limit
hql语句中支持limit关键字,分页查询可以通过以下方式实现:
String hql="不含hql";
Query q=session.createQuery(hql).setFirst(beginIndex).setMaxResults(length);
6.namedQuery
如果修改了hql语句,不希望重新编译java文件,可以预先把hql语句定义在映射文件中,在java代码中通过名称调用hql语句,这种查询方式叫做命名查询。实现方式:
<class> xxxxxxxxxxxxxxx </class> <query name="namedQuery">hql</> Query q=session.getNamedQuery("namedQuery");
十三 注解式开发
在配置文件中注册实体类 :
<mapping class="实体类全限定性类名" />
常用注解:
- @Entity:注释在类名上,表明该类是一个实体类。
- @Table:注释在类名上,指明该类映射的表名,省略时采用类名作为表名。
- @Id:注释在标识属性上,表明该属性映射为主键。
- @GeneratedValue(Strategy=GenarationType.xxxx):注释在@Id下面,设置主键生成策略。
- @Basic:注释在非标识属性上,将该属性映射为非主键字段,是一个默认注释,可以取消。
- @Column:注释在@Basic下面,设定字段名称,可以省略,省略时采用属性名作为字段名。
- @Transient:注释在不建立映射字段的属性上,必须注释,因为系统默认将所有属性映射到表中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号