
java集合
一 概述
1.什么集合?
集合是一种用于存储对象的数据结构。
2.集合与数组对比
- 数据类型:集合只能用来存储对象(实际是对象的引用),不能用于存储基本数据类型数据,基本数据类型必须转换为相应的包装类,才能存储到集合中。而数组不仅可以储存基本类型数据,还可以存储对象。
- 长度:集合存储可存储的元素数目是可变的,数组在创建时就指定了长度,可储存元素数目固定。
二 继承关系
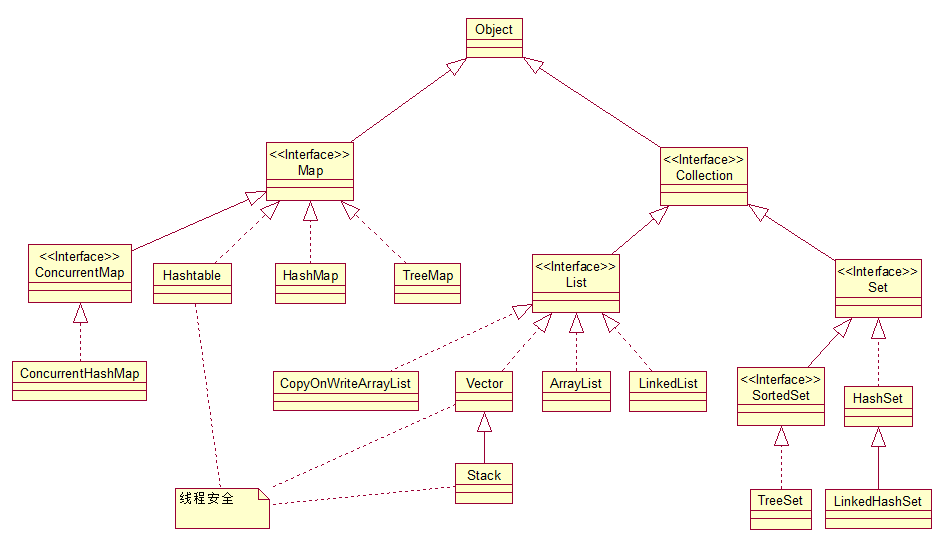
注:图中所指的线程安全是严格意义上的线程安全,即读写操作同时只能有一个线程执行,并非宽泛的同时只能有一个线程写,而多个线程读。
三 List
1.List集合特点
有序,可重复,元素允许为null。有序意味着默认情况下,在集合中,元素按照插入的顺序排列,可以根据索引操作集合中的元素,比如获取指定索引位置的元素,删除指定索引位置的元素,在指定索引位置插入元素。
2.底层实现
⑴ArrayList与Vector
底层都是数组,初始长度10,ArrayList扩容后的容量是原容量的1.5倍,Vector是原容量的2倍。Vector底层增删改查方法都采用了同步机制,线程安全,效率低,现在很少使用。
⑵LinkedList
底层采用双向链表,链表上的每一个元素都称为节点,节点由三部分构成:上一个节点的内存地址、自身存储数据的内存地址,下一个节点的内存地址。在LinkedList中元素的索引值,就是元素插入次序减1,第n个插入,索引就是n-1。
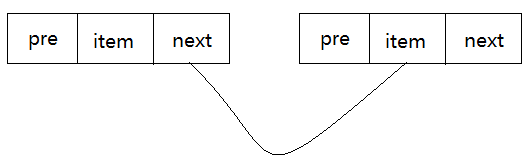
节点构成源码:
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
⑶CopyOnWriteArrayList
底层采用数组,数组长度默认长度0,即采用无参构造方法创建对象时,底层数组默认长度为0。一个读写分离的容器,执行写操作时会创建一个集合的复制品,写操作执行完毕,使引用指向写操作生成的新的集合。
3.性能对比
⑴在集合尾部插入或者删除元素
@Test public void testAddTail() { List<Integer> array = new ArrayList<Integer>(); long startTime = System.currentTimeMillis(); for (int i = 0; i < 1000000; i++) { array.add(i); } long endTime = System.currentTimeMillis(); System.out.println("ArrayList useTime::" + (endTime - startTime)); List<Integer> linked = new LinkedList<Integer>(); long startTime01 = System.currentTimeMillis(); for (int i = 0; i < 1000000; i++) { linked.add(i); } long endTime01 = System.currentTimeMillis(); System.out.println("LinkedList useTime::" + (endTime01 - startTime01)); }
输出:
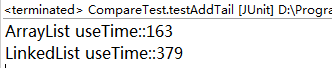
分析:
如果在结尾插入或者删除元素,ArrayList只需要插入或者删除元素即可,不需要调整数组,而LinkedList除了需要插入或者删除元素,还需要调整引用关系,因此在结尾插入或者删除时,ArrayList性能高于LikedList。
⑵在集合中间插入或者删除元素
@Test public void testInsert() { List<Integer> array = new ArrayList<Integer>(); for (int i = 0; i < 5; i++) array.add(0); long startTime01 = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { array.add(2, i); } long endTime01 = System.currentTimeMillis(); System.out.println("array useTime:" + (endTime01 - startTime01)); List<Integer> link = new LinkedList<Integer>(); for (int i = 0; i < 5; i++) link.add(0); long startTime02 = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { link.add(2, i); } long endTime02 = System.currentTimeMillis(); System.out.println("link useTime:" + (endTime02 - startTime02)); }
输出:
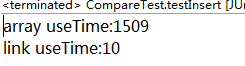
分析:
在中间插入或者删除元素时,LinkedList只需要调整两三个元素之间的引用关系即可,ArrayList要移动插入点之后所有元素,因此在中间插入或者删除时,LikedList性能高于ArrayList。
⑶查询
LinkedList中节点的内存地址间没有规律,只知道首尾节点,因此需要根据前后节点的引用关系从头或者从尾遍历到指定的索引处,效率很低。以下是查询时执行的源码:
//首先判断索引值处于前半段,还是后半段,然后从一端逐个遍历,获取一个节点之后,通过引用关系获取其上一个或者下一个节点,
//一直到前一个或者下一个节点 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; }
ArrayList底层采用数组存储,数组中存储的是同种类型的数据,每一个元素在内存中的空间大小相同,排列有序,根据首元素与索引可以快速定位到指定索引处,因此查询效率高。
所以,在查询方面,LinkedList的性能远低于ArrayList。
综上可知,不能笼统地说LinkedList增删效率高于ArrayList,关键要看增删操作发生的位置,是发生的结尾,还是中间。
⑷ArrayList与CopyOnWriteArrayList
两者在读方面的执行过程相同,都是直接返回数组指定索引的值,差异主要在写上,一下是CopyOnWriteArrayList执行add操作的源码:
public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1); newElements[len] = e; setArray(newElements); return true; } finally { lock.unlock(); } }
首先创建一个新数组,将当前数组中的数据复制到新数组中,再执行添加操作,最后将引用变量指向新数组。
ArrayList的add操作源码:
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
只是简单地为指定索引位置赋值,因此在add操作上,ArrayList性能优于CopyOnWriteArrayList。其他方面(remove),由于CopyOnWriteArrayList在执行前需要先复制数组,因此性能低于ArrayList。
4.使用须知
⑴避免频繁扩容
ArrayList与Vector底层都是数组,默认长度10,当元素个数到达10以后,系统自动创建一个新数组,把原数组中的元素复制到新数组中,而数组的创建与复制很耗费资源,因此在使用ArrayList与Vector时应预先估计可能存储的元素个数,创建时指定容量,避免使用过程中频繁创建与复制数组。
⑵CopyOnWriteArrayList缺点
CopyOnWriteArrayList的设计目的使将读写分离,读时复制一个新的集合进行操作,避免多个线程同时修改集合导致ConcurrentModificationException异常。每次执行写操作时都会复制数组,内存占用较大,在写操作执行结束前,读操作面对依然是旧的集合,数据更新不及时。CopyOnWriteArrayList主要用于读多写少的并发场景。
5.常用方法
- toArray(T[] arr):将集合中的元素复制到数组中,如果数组长度小于集合元素数目,返回新一个新数组,新数组存储了集合的全部元素,用于接收的数组不变,原来为空依然为空。如果数组长度大于集合元素数目,将集合中的元素全部制到数组中,数组空余部分赋值null。
- subList(fromIndex, toIndex):复制指定索引范围的元素构成一个新集合。
四 Set
1.Set特点
无序,不可重复,允许为null。无序意味着遍历顺序与添加顺序不同,每次编译都会生成一个新的顺序。不可重复是指集合中不允许存在两个相同的元素,不意味着不可以重复向集合中添加同一元素,重复添加,覆盖之前的元素。
2.三个常用实现类
- HashSet性能高,底层是HashMap,value是一个固定值。
- TreesSet自动排序,对象必须实现Comparable,或者传入一个比较器Comparator。对象排序可参考 http://www.cnblogs.com/tonghun/p/7148234.html
- LinkedHashSet元素按照插入顺序排列。
五 Iterator
1.作用
迭代器,用于遍历Collection集合,允许遍历过程中删除元素。
2.Iterator与Enumeration对比
Enumeration速度快,占有内存小,并发环境下,其他线程修改了集合,Enumration无法做出反应,而Iterator会抛出异常。
3.Iterator与ListIterator对比
- Iterator可以遍历Set与List,ListIterator只能遍历List。
- Iterator只能从前开始单向遍历,ListIterator可以双向遍历。
4.fail-fast
JDK没有提供一个通用的Iterator实现类,而是由需要遍历的集合根据自身情况实现了Iterator,通常这些实现类都是集合的内部类。
集合中有一个计数器modCount,初始值0,无论任何一个线程对集合执行了add、remove等修改操作,modCount都会加1,记录集合被修改的次数。具体的迭代器即Iterator的实现类是集合的内部类,ArrayList实现Iterator的源码如下:
private class Itr implements Iterator<E> { int cursor; // index of next element to return int lastRet = -1; // index of last element returned; -1 if no such int expectedModCount = modCount; ...................................... }
其中有一个计数器expectedModCount,初始值为modCount,每一次调用next()方法遍历集合的下一个元素时,或者remove()方法删除前一个迭代元素时,都会对比modCount与expectedModCount的值是否相等,如果不相等则抛出异常,next()或者remove()方法终止执行。
无论通过哪种方式修改集合,modCount的值都加1。如果迭代器以外线程修改了集合,或当前线程通过迭代以外的方法修改了集合,会尽可能抛出ConcurrentModificationException,这就是“fail-fase”机制。
"fail-fase"机制主要是为了避免遍历时其他线程修改集合,一旦其他线程修改了集合,就尝试抛出异常,不能保证一定抛出异常。源码:
public E next() { checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; }
开始执行遍历操作时,checkForComodification()会判断exceptedModCount是否等于ModCount以判断在遍历过程中是否有线程修改了集合,如果相等,则集合没有被其他线程修改,继续执行后面的代码,返回对象。假定在判断通过以后,某个线程修改了集合,迭代器无法知晓,依然当作集合没有被修改,继续执行。所以,“fail-fast”只是会尽可能地在其他线程修改了集合后抛出异常。
5.remove方法
public void remove() { if (lastRet < 0) throw new IllegalStateException(); checkForComodification(); try { ArrayList.this.remove(lastRet); cursor = lastRet; lastRet = -1; expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } }
从源码中可知,remove()方法只能删除最后一次遍历得到的元素,执行过程中lastRet变成-1,如果不继续遍历,再执行remove操作就会抛出异常。
六 Map
1.Map特点
Map以key/value键值对的形式存储数据。
2.HashMap
底层是哈希表,哈希表是数组与链表的组合,数组中的每一个元素都是一个单向链表,存储结构如下:
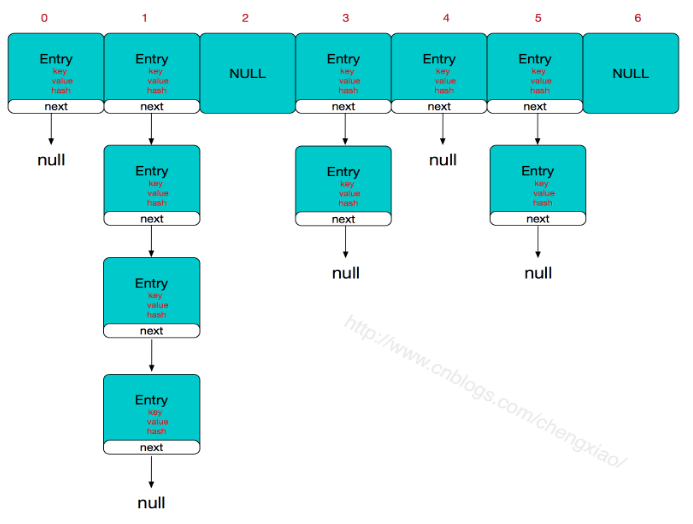
由于链表查询时,逐个对比节点,效率低,因此应该避免出现链表或者严格控制链表长度,尽可能为不同的对象设计不同的hashCode。
根据哈希表查询规则,equals为true的两个对象,hashCode必须相同;equals为false的对象,hashCode尽可能不同。建议采用String类型数据作为key值,因为String类型数据的key值可以被缓存,提高了查询速度:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final char value[]; /** Cache the hash code for the string */ private int hash; // Default to 0 ............................. }
关于equals与hashCode的知识参考http://www.cnblogs.com/tonghun/p/6938016.html
HashMap中数组的下标不是key的hashCode,因为key值多种多样,根据两个key计算出来的哈希值差值较大,导致底层数组长度无法控制,key在数组中的索引是根据hashCode计算出的一个值,计算过程如下:

3.Hashtable
底层采用同步机制,线程安全,效率低,已被ConcurrentHashMap取代。
4.TressMap
按key排序,key必须实现Comparable,或者传入一个比较器Comparator。对象排序参考http://www.cnblogs.com/tonghun/p/7148234.html
5.LikedHashMap
按key插入顺序排列。
6.ConcurrentHashMap
key与value不能为null,将Hash表分成多端,分别为每一段单独加锁,允许多个线程同时读取,多个线程同时修改不同段的数据。
7.遍历
一种遍历方法,先获取保存键值对的Set集合,然后遍历该集合:
@Test public void testForeach() { Map<String, String> strs = new HashMap<String, String>(); for (int i = 0; i < 20; i++) { strs.put("key0" + i, "value0" + i); } Set<Entry<String, String>> entrySet = strs.entrySet(); for (Entry<String, String> x : entrySet) { System.out.println(x.getKey() + "=" + x.getValue()); } }
8.按照value排序
TreeMap是按照key对Map进行排序,可以利用TreeMap,实际对比时由key获取value,对比value的大小:
package com.javase.collections.map; import java.util.Comparator; import java.util.Map; import java.util.TreeMap; public class MapUtils { /** * 按照value升序排列集合。 * * @param map * @return */ public static <K, V extends Comparable<? super V>> Map<K, V> sortByValue(Map<K, V> map) { Map<K, V> sorter = new TreeMap<K, V>(new ValueComparator<K, V>(map)); sorter.putAll(map); return sorter; } private static class ValueComparator<K, T extends Comparable<? super T>> implements Comparator<K> { private Map<K, T> map; public ValueComparator(Map<K, T> map) { super(); this.map = map; } // TreeMap会调用该方法对key进行排序,如果区分key大小的标准不再是key自身,而是对应的value,就实现了按照value进行排序 @Override public int compare(K k1, K k2) { return map.get(k1).compareTo(map.get(k2)); } } }
七 数组与集合相互转化
1.数组转化为集合
Arrays工具类提供了一个方法asList(T...a),返回一个固定长度的List,该List是Arrays的内部类,不是java.util.ArrayList,不可以添加或者删除数据,不建议采用该方法。Collections工具类中有一个方法addAll(Collection<? super T> c, T... elements),可以将数组中的元素添加到集合中,demo如下:
@Test public void testTransformToCollection() { Integer[] arr = new Integer[] { new Integer(1), new Integer(2) };//创建一个数组 List<Integer> IntList = new ArrayList<Integer>();//创建一个集合 Collections.addAll(IntList, arr);//将数组中的元素添加到集合中 }
2.集合转化为数组
由于数组排列有序,将无序的Set集合转化为数组时,元素排列由无序状态转化为有序状态,怎么从多种多样的无序状态中确定一种有序状态呢?即选择哪一种无序状态作为有序状态呢,选择依据是什么?因此只能将List集合转化为数组,不能将Set集合转化为数组,转化方式是调用集合的toArray(T[] a)方法。
八 集合工具类
1.Arrays
- Arrays.sort(Object[] arr):对数组进行排序。
- copyOf(T[] src,int newLength):复制一个新数组,新数组长度为newLength,数组元素为src数组中索引从0-newLength-1的的元素,如果newLength超出src长度,超出部分用默认值填充。数值型默认值0,对象类型默认null。
- copyOfRange(T[] src,index from,int to):从src中复制索引从from到to范围的元素到新数组中。
- toString(T[] arr):将数组转化成由","连接的数组。
2.Collections
- Collections.sort():底层调用Arrays.sort(),用于对List集合进行排序。
- Collections.addAll(Collection<? super T>,T...elements):将若干个元素添加到集合中。
- synchronizedList(List<T> list):返回一个线程安全的访问集合的对象,只有通过该对象访问集合才是线程安全的。限制条件加在访问方式上,并未加在集合上。
- unmodifiableList(List<? extends T> list):返回一个以只读方式访问集合的对象,只有通过该对象访问集合才是只读的。限制条件加在访问方式上,并未加在集合上。
参考:
http://www.cnblogs.com/xujian2014/p/5846128.html
http://ifeve.com/java-copy-on-write/
http://www.importnew.com/21396.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号