lunix awk
awk的前世今生:
awk名字的由来:分别取三个创始人Ah,Weiberger,Kernighan三个人的首字母。
awk是一个报告生成器可以格式化输出文本内容。模式扫描和处理语言(pattern scarming and processing language)
awk工作流程图
第一步:读取被匹配到的行数据。
第二步:按照输入分隔符将整行数据分成n段。
第三步:将每一段保存到awk的内置变量,依次为$1~$n。
第四部:格式化输出。全部输出使用$0。
对段的操作:
如:判断第二个字段是否>2
如:循环$1~$n,对其进行统一操作

awk 的用法:
- awk [POSIX or GNU style options ] -f program-file [-] file......
- awk [POSIX or GNU style options ] [-] program-text file....
上边的两个语法有点难看懂,我们可以这么用
-
awk [options] 'program' file
options:
-F:指定输入数据是的字段分割符。
-v:自定义变量;格式为 variable=value。
'program':awk的程序语句段
标准形式:'PATTERN {'ACTION STATEMENTS'}'
注意:program必须使用''引起来,以防止被shell解释
PATTERN为匹配模式。
ACTION STATEMENTS为操作语句。
注意:ACTION 是由系统的awk语句组成,各语句之间用;分隔。
ACTION STATEMENTS:
输出命令:print
print item1,item2,item3……
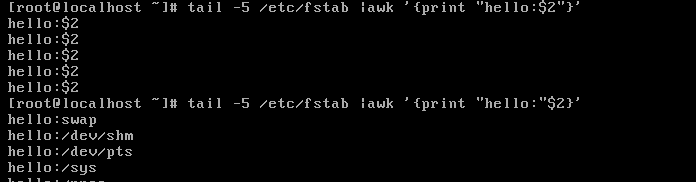
要点1:各item之间用逗号分隔,若不适用逗号则awk会默认连接两个item的内容。
首先取出文件中的后五行,然后使用awk取出其第二和第四个段(默认空格为分隔符)

$2和$4之间没有逗号,则默认拼接$2$4

要点2:print输出的item可以是数值,$n,变量,或awk表达式。
要想引用$n的值,不能把其放入“”内。
要点3:若省略item,则默认输出$0。

变量:分为内置变量和自定义变量
内置变量:
FS:input field seperator。输入字段分隔符
可以使用-v来指定分隔符,也可以直接使用-F直接指名。


OFS:outpu field seperator。输出字段分隔符
可以看到上图的输出内容,字段之间以空格分隔。使用OFS指定以:分隔。

RS:input record seperator 。输入时的换行符
ORS:output record seperator。输出时的换行符
NF:number of field。每一行的字段数量。
没有指定输入分隔符(FS),默认以空格来分隔。

指定以:为分隔符后 ,输出每一行字段数量。

$NF代表的是$7即最后一行。所以输出文件的每一行的最后一个字段。

NR:numbe of record 。显示文件的行数。每处理一行就会输出一次行数

合并多个文件的行数。

NFR单独计算每个文件的行数。

END只输出最后的行数

FILENAME:正在被awk编辑的文件名。
每处理一行数据都会打印一次文件名,test2文件有两行数据,所以输出两行。

ARGC:命令行参数个数 program不算参数。此处参数分别是 awk和两个文件

ARGV:是一个数组,保存了命令行参数。

ARGV[index]:取出ARGV中的参数从0开始。

自定义变量:-v variable=value或在program中直接定义。
注意:变量名区分大小写
下边是两种变量定义方法。


格式化输出命令:printf
语法:printf FORMAT, item1,item2,……
格式符:
%s:显示字符串
%c:显示字符对应的ASCII码
%d,%i:显示十进制整数
%e,%E:显示科学计数法数值
%f:显示浮点数
%g,%G:以科学计数法或者浮点形式显示数值
%u:显示无符号整数
%%:显示%
要点一:FORMAT必须给出
要点二:printf输出是不会自动换行,若需要换行可以使用换行控制符——\n
可以看到输出的是一堆连续的字符

手动控制换行

要点三:FORMAT中给出的格式符需要与item一一对应
要点四:在printf中可以加入提示性字符


修饰符:用来修饰格式符。
#[.#]:第一个#用来控制字符宽度,第二个用来控制小数位数。

-:左对齐。注意默认为右对齐。

+:显示数值的符号。
操作符:
算数运算:+ - * / % ^ -x +x
比较运算:> >= = < <= != ==
赋值运算:++,--,+=,-=,*=,%=
字符串操作:默认为字符串拼接
模式匹配:
~:是否匹配:左侧字符是否被右侧模式匹配
如果$NF的内容能匹配行末是bash ,这输出$1,$NF

!~:是否不匹配,:左侧字符是否不被右侧模式匹配
逻辑操作符:
&&:与
||:或
!:非
函数调用:function_name(argu1,argu2……)
条件表达式:selector?if_true_expression:if_false_expression
如果用户ID大于1000,则usertype=common user 否则等于sysadmin user .然后输出$1和usertype

PATTER:模式
empty:空模式(默认),此模式会匹配文件的每一行
/regular expression/:处理被pattern匹配的每一行
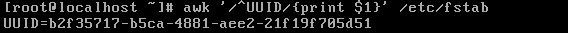
relational expression :关系表达式,如果是一个布尔值。若为真则会被处理,为假被过滤
真:非0只,非空字符
假:0,空字符
第三个字段值大于1000,输出$1,$3

如果最后一个字段为/bin/bash,则输出$1,$NF


line ranges:行范围
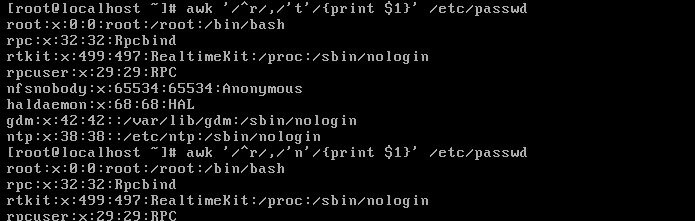
/pattern1/,/pattern2/:处理 pattern1 到 pattern2 之间(不包含pattern2)。从pattern1匹配的行开始,到pattern2匹配的行结束。
匹配第一个以r开头的行到第一个以t开头的行。但是我们会发现并没有输出t开头的行,结合第二个命令的输出。
我们会发现匹配的范围为t开头的前一行
BEGIN和END模式:是给程序赋予初始状态和在程序结束之后执行一些扫尾的工作。
BEGIN{}:任何在BEGIN之后列出的操作(在{}内)将在awk开始扫描输入之前执行一次。
END{}:END之后列出的操作将在扫描完全部的输入之后执行一次。
第一步:利用BEGIN{}输出一个表头。

第二步:格式化输出内容

第三步:利用END{}输出表尾

awk的基本应用到此结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号