七夕也要学起来,哈希哈希哈希!

前言
本文收录于专辑:http://dwz.win/HjK,点击解锁更多数据结构与算法的知识。
你好,我是彤哥。
上一节,我们一起学习了,在Java中如何构建高性能队列,里面牵涉到很多底层的知识,不知道你有Get到多少呢?!
本节,我想跟着大家一起重新学习下关于哈希的一切——哈希、哈希函数、哈希表。
这三者有什么样的爱恨情仇?
为什么Object类中需要有一个hashCode()方法?它跟equals()方法有什么关系?
如何编写一个高性能的哈希表?
Java中的HashMap中的红黑树可以使用其它数据结构替换吗?
何为哈希?
Hash,是指把任意长度的输入通过一定的算法变成固定长度的输出的过程,这个输出称作Hash值,或者Hash码,这个算法叫做Hash算法,或者Hash函数,这个过程我们一般就称作Hash,或者计算Hash,Hash翻译为中文有哈希、散列、杂凑等。
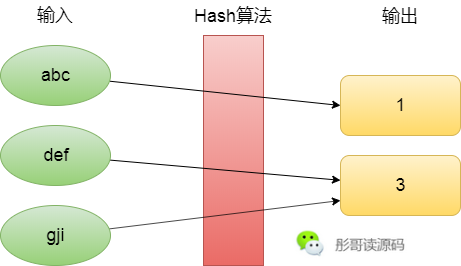
既然是固定长度的输出,那就意味着输入是无限多的,输出是有限的,必然会出现不同的输入可能会得到相同的输出的情况,所以,Hash算法一般来说也是不可逆的。
那么,Hash算法有哪些用途呢?
哈希算法的用途
哈希算法,是一种广义的算法,或者说是一种思想,它没有一个固定的公式,只要满足上面定义的算法,都可以称作Hash算法。
通常来说,它具有以下用途:
- 加密密码,比如,使用MD5+盐的方式来加密密码;
- 快速查询,比如,哈希表的使用,通过哈希表能够快速查询元素;
- 数字签名,比如,系统间调用加上签名,可以防止篡改数据;
- 文件检验,比如,下载腾讯游戏的时候通常都有有一个MD5值,安装包下载下来之后计算出来一个MD5值与官方的MD5值进行对比,就可知道下载过程中有没有文件损坏,有没有被篡改等;
好了,说起Hash算法,或者Hash函数,在Java中,所有对象的父类Object都有一个Hash函数,即hashCode()方法,为什么Object类中需要定义这么一个方法呢?
严格来说,Hash算法和Hash函数还是有点区别的,相信你能根据语境进行区分。
让我们来看看JDK源码的注释怎么说:

请看红框的部分,翻译一下大致为:为这个对象返回一个Hash值,它是为了更好地支持哈希表而存在的,比如HashMap。简单点说,这个方法就是给HashMap等哈希表使用的。
// 默认返回的是对象的内部地址
public native int hashCode();
此时,我们不得不提起Object类中的另一个方法——equals()。
// 默认是直接比较两个对象的地址是否相等
public boolean equals(Object obj) {
return (this == obj);
}
hashCode()和equals又有怎样的纠缠呢?
通常来说,hashCode()可以看作是一种弱比较,回归Hash的本质,将不同的输入映射到固定长度的输出,那么,就会出现以下几种情况:
- 输入相同,输出必然相同;
- 输入不同,输出可能相同,也可能不同;
- 输出相同,输入可能相同,也可能不同;
- 输出不同,输入必然不同;
而equals()是严格比较两个对象是否相等的方法,所以,如果两个对象equals()为true,那么,它们的hashCode()一定要相等,如果不相等会怎样呢?
如果equals()返回true,而hashCode()不相等,那么,试想将这两个对象作为HashMap的key,它们很大可能会定位到HashMap不同的槽中,此时就会出现一个HashMap中插入了两个相等的对象,这是不允许的,这也是为什么重写了equals()方法一定要重写hashCode()方法的原因。
比如,String这个类,我们都知道它的equals()方法是比较两个字符串的内容是否相等,而不是两个字符串的地址,下面是它的equals()方法:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
所以,对于下面这两个字符串对象,使用equals()比较它们是相等的,而它们的内存地址并不相同:
String a = new String("123");
String b = new String("123");
System.out.println(a.equals(b)); // true
System.out.println(a == b); // false
此时,如果不重写hashCode()方法,那么,a和b将返回不同的hash码,对于我们常常使用String作为HashMap的key将造成巨大的干扰,所以,String重写的hashCode()方法:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
这个算法也很简单,用公式来表示为:s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]。
好了,既然这里屡次提到哈希表,那我们就来看看哈希表是如何一步步进化的。
哈希表进化史
数组
讲哈希表之前,我们先来看看数据结构的鼻祖——数组。
数组比较简单,我就不多说了,大家都会都懂,见下图。

数组的下标一般从0开始,依次往后存储元素,查找指定元素也是一样,只能从头(或从尾)依次查找元素。
比如,要查找4这个元素,从头开始查找的话需要查找3次。
早期的哈希表
上面讲了数组的缺点,查找某个元素只能从头或者从尾依次查找元素,直到匹配为止,它的均衡时间复杂是O(n)。
那么,利用数组有没有什么方法可以快速的查找元素呢?
聪明的程序员哥哥们想到一种方法,通过哈希函数计算元素的值,用这个值确定元素在数组中的位置,这样时间复杂度就能缩短到O(1)了。
比如,有5个元素分别为3、5、4、1,把它们放入到数组之前先通过哈希函数计算位置,精确放置,而不是像简单数组那样依次放置元素(基于索引而不是元素值来查找位置)。
假如,这里申请的数组长度为8,我们可以造这么一个哈希函数为hash(x) = x % 8,那么最后的元素就变成了下图这样:

这时候我们再查找4这个元素,先算一下它的hash值为hash(4) = 4 % 8 = 4,所以直接返回4号位置的元素就可以了。
进化的哈希表
事情看着挺完美,但是,来了一个元素13,要插入的哈希表中,算了一下它的hash值为hash(13) = 13 % 8 = 5,纳尼,它计算的位置也是5,可是5号已经被人先一步占领了,怎么办呢?
这就是哈希冲突。
为什么会出现哈希冲突呢?
因为我们申请的数组是有限长度的,把无限的数字映射到有限的数组上早晚会出现冲突,即多个元素映射到同一个位置上。
好吧,既然出现了哈希冲突,那么我们就要解决它,必须干!
How to?
线性探测法
既然5号位置已经有主了,那我元素13认怂,我往后挪一位,我到6号位置去,这就是线性探测法,当出现冲突的时候依次往后挪直到找到空位置为止。

然鹅,又来了个新元素12,算得其hash值为hash(12) = 12 % 8 = 4,What?按照这种方式,要往后移3次到7号位置才有空位置,这就导致了插入元素的效率很低,查找也是一样的道理,先定位的4号位置,发现不是我要找的人,再接着往后移,直到找到7号位置为止。
二次探测法
使用线性探测法有个很大的弊端,冲突的元素往往会堆积在一起,比如,12号放到7号位置,再来个14号一样冲突,接着往后再数组结尾了,再从头开始放到0号位置,你会发现冲突的元素有聚集现象,这就很不利于查找了,同样不利于插入新的元素。
这时候又有聪明的程序员哥哥提出了新的想法——二次探测法,当出现冲突时,我不是往后一位一位这样来找空位置,而是使用原来的hash值加上i的二次方来寻找,i依次从1,2,3...这样,直到找到空位置为止。
还是以上面的为例,插入12号元素,过程是这样的,本文来源于公主号彤哥读源码:

这样就能很快地找到空位置放置新元素,而且不会出现冲突元素堆积的现象。
然鹅,又来了新元素20,你瞅瞅放哪?
发现放哪都放不进去了。
研究表明,使用二次探测法的哈希表,当放置的元素超过一半时,就会出现新元素找不到位置的情况。
所以又引出一个新的概念——扩容。
什么是扩容?
已放置元素达到总容量的x%时,就需要扩容了,这个x%时又叫作扩容因子。
很显然,扩容因子越大越好,表明哈希表的空间利用率越高。
所以,很遗憾,二次探测法无法满足我们的目标,扩容因子太小了,只有0.5,一半的空间都是浪费的。
这时候又到了程序员哥哥们发挥他们聪明特性的时候了,经过996头脑风暴后,又想出了一种新的哈希表实现方式——链表法。
链表法
不就是解决冲突嘛!出现冲突我就不往数组中去放了,我用一个链表把同一个数组下标位置的元素连接起来,这样不就可以充分利用空间了嘛,啊哈哈哈哈~~
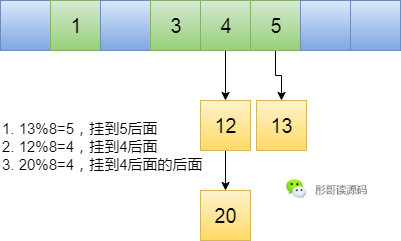
嘿嘿嘿嘿,完美△△。
真的完美嘛,我是一名黑客,我一直往里面放*%8=4的元素,然后你就会发现几乎所有的元素都跑到同一个链表中去了,呵呵,最后的结果就是你的哈希表退化成了链表,查询插入元素的效率都变成了O(n)。
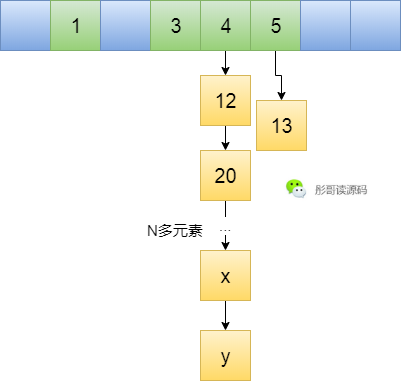
此时,当然有办法,扩容因子干啥滴?
比如扩容因子设置为1,当元素个数达到8个时,扩容成两倍,一半的元素还在4号位置,一半的元素去到了12号位置,能缓解哈希表的压力。
然鹅,依旧不是很完美,也只是从一个链表变成两个链表,本文来源于公主号彤哥读源码。
聪明的程序员哥哥们这次开启了一次长大9127的头脑风暴,终于搞出了一种新的结构——链表树法。
链表树法
虽然上面的扩容在元素个数比较少的时候能解决一部分问题,整体的查找插入效率也不会太低,因为元素个数少嘛。
但是,黑客还在攻击,元素个数还在持续增加,当增加到一定程度的时候,总会导致查找插入效率特别低。
所以,换个思路,既然链表的效率低,我把它升级一下,当链表长的时候升级成红黑树怎么样?
嗯,我看行,说干就干。
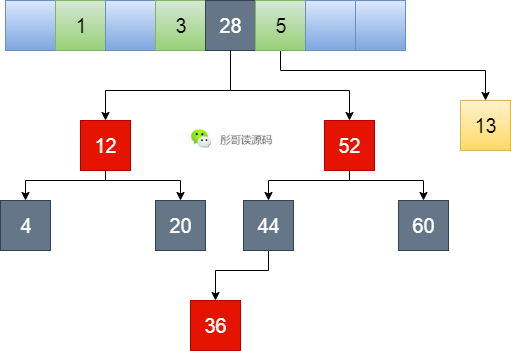
嗯,不错不错,妈妈再也不怕我遭到黑客攻击了,红黑树的查询效率为O(log n),比链表的O(n)要高不少。
所以,到这就结束了吗?
你想多了,每次扩容还是要移动一半的元素好么,一颗树分化成两颗树,这样真的好么好么好么?
程序员哥哥们太难了,这次经过了12127的头脑风暴,终于想出个新玩意——一致性Hash。
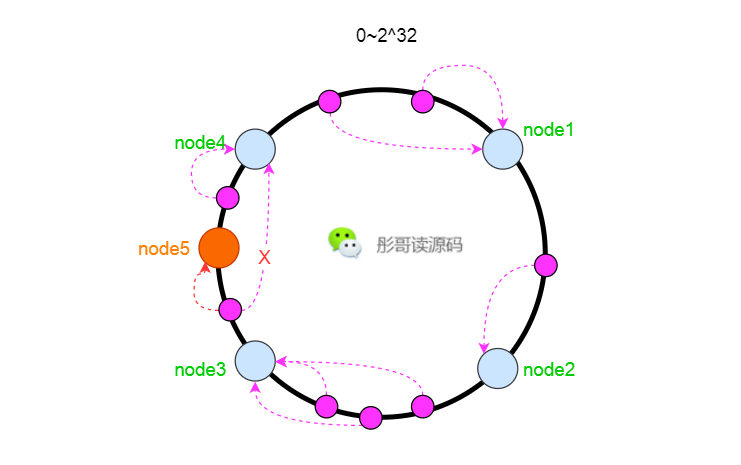
一致性Hash
一致性Hash更多地是运用在分布式系统中,比如说Redis集群部署了四个节点,我们把所有的hash值定义为0~2^32个,每个节点上放置四分之一的元素。
此处只为举例,实际Redis集群的原理是这样的,具体数值不是这样的。
此时,假设需要给Redis增加一个节点,比如node5,放在node3和node4中间,这样只需要把node3到node4中间的元素从node4移动到node5上面就行了,其它的元素保持不变。
这样,就增加了扩容的速度,而且影响的元素比较少,大部分请求几乎无感知。
好了,到这里关于哈希表的进化历史就讲到这里了,你有没有Get到呢?
后记
本节,我们一起重新学习了关于哈希、哈希函数、哈希表相关的知识,在Java中,HashMap的终极形态是以数组+链表+红黑树的形式呈现的。
据说,这个红黑树还可以换成其它的数据结构,比如跳表,你造吗?
下一节,我们就来聊聊跳表这个数据结构,并使用它来改写HashMap,欲获取最新推广,快点来关注我吧!
关注公号主“彤哥读源码”,解锁更多源码、基础、架构知识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号