死磕 java同步系列之Phaser源码解析
问题
(1)Phaser是什么?
(2)Phaser具有哪些特性?
(3)Phaser相对于CyclicBarrier和CountDownLatch的优势?
简介
Phaser,翻译为阶段,它适用于这样一种场景,一个大任务可以分为多个阶段完成,且每个阶段的任务可以多个线程并发执行,但是必须上一个阶段的任务都完成了才可以执行下一个阶段的任务。
这种场景虽然使用CyclicBarrier或者CountryDownLatch也可以实现,但是要复杂的多。首先,具体需要多少个阶段是可能会变的,其次,每个阶段的任务数也可能会变的。相比于CyclicBarrier和CountDownLatch,Phaser更加灵活更加方便。
使用方法
下面我们看一个最简单的使用案例:
public class PhaserTest {
public static final int PARTIES = 3;
public static final int PHASES = 4;
public static void main(String[] args) {
Phaser phaser = new Phaser(PARTIES) {
@Override
protected boolean onAdvance(int phase, int registeredParties) {
// 【本篇文章由公众号“彤哥读源码”原创,请支持原创,谢谢!】
System.out.println("=======phase: " + phase + " finished=============");
return super.onAdvance(phase, registeredParties);
}
};
for (int i = 0; i < PARTIES; i++) {
new Thread(()->{
for (int j = 0; j < PHASES; j++) {
System.out.println(String.format("%s: phase: %d", Thread.currentThread().getName(), j));
phaser.arriveAndAwaitAdvance();
}
}, "Thread " + i).start();
}
}
}
这里我们定义一个需要4个阶段完成的大任务,每个阶段需要3个小任务,针对这些小任务,我们分别起3个线程来执行这些小任务,查看输出结果为:
Thread 0: phase: 0
Thread 2: phase: 0
Thread 1: phase: 0
=======phase: 0 finished=============
Thread 2: phase: 1
Thread 0: phase: 1
Thread 1: phase: 1
=======phase: 1 finished=============
Thread 1: phase: 2
Thread 0: phase: 2
Thread 2: phase: 2
=======phase: 2 finished=============
Thread 0: phase: 3
Thread 2: phase: 3
Thread 1: phase: 3
=======phase: 3 finished=============
可以看到,每个阶段都是三个线程都完成了才进入下一个阶段。这是怎么实现的呢,让我们一起来学习吧。
原理猜测
根据我们前面学习AQS的原理,大概猜测一下Phaser的实现原理。
首先,需要存储当前阶段phase、当前阶段的任务数(参与者)parties、未完成参与者的数量,这三个变量我们可以放在一个变量state中存储。
其次,需要一个队列存储先完成的参与者,当最后一个参与者完成任务时,需要唤醒队列中的参与者。
嗯,差不多就是这样子。
结合上面的案例带入:
初始时当前阶段为0,参与者数为3个,未完成参与者数为3;
第一个线程执行到phaser.arriveAndAwaitAdvance();时进入队列;
第二个线程执行到phaser.arriveAndAwaitAdvance();时进入队列;
第三个线程执行到phaser.arriveAndAwaitAdvance();时先执行这个阶段的总结onAdvance(),再唤醒前面两个线程继续执行下一个阶段的任务。
嗯,整体能说得通,至于是不是这样呢,让我们一起来看源码吧。
源码分析
主要内部类
static final class QNode implements ForkJoinPool.ManagedBlocker {
final Phaser phaser;
final int phase;
final boolean interruptible;
final boolean timed;
boolean wasInterrupted;
long nanos;
final long deadline;
volatile Thread thread; // nulled to cancel wait
QNode next;
QNode(Phaser phaser, int phase, boolean interruptible,
boolean timed, long nanos) {
this.phaser = phaser;
this.phase = phase;
this.interruptible = interruptible;
this.nanos = nanos;
this.timed = timed;
this.deadline = timed ? System.nanoTime() + nanos : 0L;
thread = Thread.currentThread();
}
}
先完成的参与者放入队列中的节点,这里我们只需要关注thread和next两个属性即可,很明显这是一个单链表,存储着入队的线程。
主要属性
// 状态变量,用于存储当前阶段phase、参与者数parties、未完成的参与者数unarrived_count
private volatile long state;
// 最多可以有多少个参与者,即每个阶段最多有多少个任务
private static final int MAX_PARTIES = 0xffff;
// 最多可以有多少阶段
private static final int MAX_PHASE = Integer.MAX_VALUE;
// 参与者数量的偏移量
private static final int PARTIES_SHIFT = 16;
// 当前阶段的偏移量
private static final int PHASE_SHIFT = 32;
// 未完成的参与者数的掩码,低16位
private static final int UNARRIVED_MASK = 0xffff; // to mask ints
// 参与者数,中间16位
private static final long PARTIES_MASK = 0xffff0000L; // to mask longs
// counts的掩码,counts等于参与者数和未完成的参与者数的'|'操作
private static final long COUNTS_MASK = 0xffffffffL;
private static final long TERMINATION_BIT = 1L << 63;
// 一次一个参与者完成
private static final int ONE_ARRIVAL = 1;
// 增加减少参与者时使用
private static final int ONE_PARTY = 1 << PARTIES_SHIFT;
// 减少参与者时使用
private static final int ONE_DEREGISTER = ONE_ARRIVAL|ONE_PARTY;
// 没有参与者时使用
private static final int EMPTY = 1;
// 用于求未完成参与者数量
private static int unarrivedOf(long s) {
int counts = (int)s;
return (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);
}
// 用于求参与者数量(中间16位),注意int的位置
private static int partiesOf(long s) {
return (int)s >>> PARTIES_SHIFT;
}
// 用于求阶段数(高32位),注意int的位置
private static int phaseOf(long s) {
return (int)(s >>> PHASE_SHIFT);
}
// 已完成参与者的数量
private static int arrivedOf(long s) {
int counts = (int)s; // 低32位
return (counts == EMPTY) ? 0 :
(counts >>> PARTIES_SHIFT) - (counts & UNARRIVED_MASK);
}
// 用于存储已完成参与者所在的线程,根据当前阶段的奇偶性选择不同的队列
private final AtomicReference<QNode> evenQ;
private final AtomicReference<QNode> oddQ;
主要属性为state和evenQ及oddQ:
(1)state,状态变量,高32位存储当前阶段phase,中间16位存储参与者的数量,低16位存储未完成参与者的数量【本篇文章由公众号“彤哥读源码”原创,请支持原创,谢谢!】;
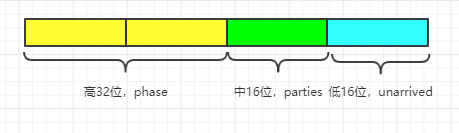
(2)evenQ和oddQ,已完成的参与者存储的队列,当最后一个参与者完成任务后唤醒队列中的参与者继续执行下一个阶段的任务,或者结束任务。
构造方法
public Phaser() {
this(null, 0);
}
public Phaser(int parties) {
this(null, parties);
}
public Phaser(Phaser parent) {
this(parent, 0);
}
public Phaser(Phaser parent, int parties) {
if (parties >>> PARTIES_SHIFT != 0)
throw new IllegalArgumentException("Illegal number of parties");
int phase = 0;
this.parent = parent;
if (parent != null) {
final Phaser root = parent.root;
this.root = root;
this.evenQ = root.evenQ;
this.oddQ = root.oddQ;
if (parties != 0)
phase = parent.doRegister(1);
}
else {
this.root = this;
this.evenQ = new AtomicReference<QNode>();
this.oddQ = new AtomicReference<QNode>();
}
// 状态变量state的存储分为三段
this.state = (parties == 0) ? (long)EMPTY :
((long)phase << PHASE_SHIFT) |
((long)parties << PARTIES_SHIFT) |
((long)parties);
}
构造函数中还有一个parent和root,这是用来构造多层级阶段的,不在本文的讨论范围之内,忽略之。
重点还是看state的赋值方式,高32位存储当前阶段phase,中间16位存储参与者的数量,低16位存储未完成参与者的数量。
下面我们一起来看看几个主要方法的源码:
register()方法
注册一个参与者,如果调用该方法时,onAdvance()方法正在执行,则该方法等待其执行完毕。
public int register() {
return doRegister(1);
}
private int doRegister(int registrations) {
// state应该加的值,注意这里是相当于同时增加parties和unarrived
long adjust = ((long)registrations << PARTIES_SHIFT) | registrations;
final Phaser parent = this.parent;
int phase;
for (;;) {
// state的值
long s = (parent == null) ? state : reconcileState();
// state的低32位,也就是parties和unarrived的值
int counts = (int)s;
// parties的值
int parties = counts >>> PARTIES_SHIFT;
// unarrived的值
int unarrived = counts & UNARRIVED_MASK;
// 检查是否溢出
if (registrations > MAX_PARTIES - parties)
throw new IllegalStateException(badRegister(s));
// 当前阶段phase
phase = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
break;
// 不是第一个参与者
if (counts != EMPTY) { // not 1st registration
if (parent == null || reconcileState() == s) {
// unarrived等于0说明当前阶段正在执行onAdvance()方法,等待其执行完毕
if (unarrived == 0) // wait out advance
root.internalAwaitAdvance(phase, null);
// 否则就修改state的值,增加adjust,如果成功就跳出循环
else if (UNSAFE.compareAndSwapLong(this, stateOffset,
s, s + adjust))
break;
}
}
// 是第一个参与者
else if (parent == null) { // 1st root registration
// 计算state的值
long next = ((long)phase << PHASE_SHIFT) | adjust;
// 修改state的值,如果成功就跳出循环
if (UNSAFE.compareAndSwapLong(this, stateOffset, s, next))
break;
}
else {
// 多层级阶段的处理方式
synchronized (this) { // 1st sub registration
if (state == s) { // recheck under lock
phase = parent.doRegister(1);
if (phase < 0)
break;
// finish registration whenever parent registration
// succeeded, even when racing with termination,
// since these are part of the same "transaction".
while (!UNSAFE.compareAndSwapLong
(this, stateOffset, s,
((long)phase << PHASE_SHIFT) | adjust)) {
s = state;
phase = (int)(root.state >>> PHASE_SHIFT);
// assert (int)s == EMPTY;
}
break;
}
}
}
}
return phase;
}
// 等待onAdvance()方法执行完毕
// 原理是先自旋一定次数,如果进入下一个阶段,这个方法直接就返回了,
// 如果自旋一定次数后还没有进入下一个阶段,则当前线程入队列,等待onAdvance()执行完毕唤醒
private int internalAwaitAdvance(int phase, QNode node) {
// 保证队列为空
releaseWaiters(phase-1); // ensure old queue clean
boolean queued = false; // true when node is enqueued
int lastUnarrived = 0; // to increase spins upon change
// 自旋的次数
int spins = SPINS_PER_ARRIVAL;
long s;
int p;
// 检查当前阶段是否变化,如果变化了说明进入下一个阶段了,这时候就没有必要自旋了
while ((p = (int)((s = state) >>> PHASE_SHIFT)) == phase) {
// 如果node为空,注册的时候传入的为空
if (node == null) { // spinning in noninterruptible mode
// 未完成的参与者数量
int unarrived = (int)s & UNARRIVED_MASK;
// unarrived有变化,增加自旋次数
if (unarrived != lastUnarrived &&
(lastUnarrived = unarrived) < NCPU)
spins += SPINS_PER_ARRIVAL;
boolean interrupted = Thread.interrupted();
// 自旋次数完了,则新建一个节点
if (interrupted || --spins < 0) { // need node to record intr
node = new QNode(this, phase, false, false, 0L);
node.wasInterrupted = interrupted;
}
}
else if (node.isReleasable()) // done or aborted
break;
else if (!queued) { // push onto queue
// 节点入队列
AtomicReference<QNode> head = (phase & 1) == 0 ? evenQ : oddQ;
QNode q = node.next = head.get();
if ((q == null || q.phase == phase) &&
(int)(state >>> PHASE_SHIFT) == phase) // avoid stale enq
queued = head.compareAndSet(q, node);
}
else {
try {
// 当前线程进入阻塞状态,跟调用LockSupport.park()一样,等待被唤醒
ForkJoinPool.managedBlock(node);
} catch (InterruptedException ie) {
node.wasInterrupted = true;
}
}
}
// 到这里说明节点所在线程已经被唤醒了
if (node != null) {
// 置空节点中的线程
if (node.thread != null)
node.thread = null; // avoid need for unpark()
if (node.wasInterrupted && !node.interruptible)
Thread.currentThread().interrupt();
if (p == phase && (p = (int)(state >>> PHASE_SHIFT)) == phase)
return abortWait(phase); // possibly clean up on abort
}
// 唤醒当前阶段阻塞着的线程
releaseWaiters(phase);
return p;
}
增加一个参与者总体的逻辑为:
(1)增加一个参与者,需要同时增加parties和unarrived两个数值,也就是state的中16位和低16位;
(2)如果是第一个参与者,则尝试原子更新state的值,如果成功了就退出;
(3)如果不是第一个参与者,则检查是不是在执行onAdvance(),如果是等待onAdvance()执行完成,如果否则尝试原子更新state的值,直到成功退出;
(4)等待onAdvance()完成是采用先自旋后进入队列排队的方式等待,减少线程上下文切换;
arriveAndAwaitAdvance()方法
当前线程当前阶段执行完毕,等待其它线程完成当前阶段。
如果当前线程是该阶段最后一个到达的,则当前线程会执行onAdvance()方法,并唤醒其它线程进入下一个阶段。
public int arriveAndAwaitAdvance() {
// Specialization of doArrive+awaitAdvance eliminating some reads/paths
final Phaser root = this.root;
for (;;) {
// state的值
long s = (root == this) ? state : reconcileState();
// 当前阶段
int phase = (int)(s >>> PHASE_SHIFT);
if (phase < 0)
return phase;
// parties和unarrived的值
int counts = (int)s;
// unarrived的值(state的低16位)
int unarrived = (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);
if (unarrived <= 0)
throw new IllegalStateException(badArrive(s));
// 修改state的值
if (UNSAFE.compareAndSwapLong(this, stateOffset, s,
s -= ONE_ARRIVAL)) {
// 如果不是最后一个到达的,则调用internalAwaitAdvance()方法自旋或进入队列等待
if (unarrived > 1)
// 这里是直接返回了,internalAwaitAdvance()方法的源码见register()方法解析
return root.internalAwaitAdvance(phase, null);
// 到这里说明是最后一个到达的参与者
if (root != this)
return parent.arriveAndAwaitAdvance();
// n只保留了state中parties的部分,也就是中16位
long n = s & PARTIES_MASK; // base of next state
// parties的值,即下一次需要到达的参与者数量
int nextUnarrived = (int)n >>> PARTIES_SHIFT;
// 执行onAdvance()方法,返回true表示下一阶段参与者数量为0了,也就是结束了
if (onAdvance(phase, nextUnarrived))
n |= TERMINATION_BIT;
else if (nextUnarrived == 0)
n |= EMPTY;
else
// n 加上unarrived的值
n |= nextUnarrived;
// 下一个阶段等待当前阶段加1
int nextPhase = (phase + 1) & MAX_PHASE;
// n 加上下一阶段的值
n |= (long)nextPhase << PHASE_SHIFT;
// 修改state的值为n
if (!UNSAFE.compareAndSwapLong(this, stateOffset, s, n))
return (int)(state >>> PHASE_SHIFT); // terminated
// 唤醒其它参与者并进入下一个阶段
releaseWaiters(phase);
// 返回下一阶段的值
return nextPhase;
}
}
}
arriveAndAwaitAdvance的大致逻辑为:
(1)修改state中unarrived部分的值减1;
(2)如果不是最后一个到达的,则调用internalAwaitAdvance()方法自旋或排队等待;
(3)如果是最后一个到达的,则调用onAdvance()方法,然后修改state的值为下一阶段对应的值,并唤醒其它等待的线程;
(4)返回下一阶段的值;
总结
(1)Phaser适用于多阶段多任务的场景,每个阶段的任务都可以控制得很细;
(2)Phaser内部使用state变量及队列实现整个逻辑【本篇文章由公众号“彤哥读源码”原创,请支持原创,谢谢!】;
(3)state的高32位存储当前阶段phase,中16位存储当前阶段参与者(任务)的数量parties,低16位存储未完成参与者的数量unarrived;
(4)队列会根据当前阶段的奇偶性选择不同的队列;
(5)当不是最后一个参与者到达时,会自旋或者进入队列排队来等待所有参与者完成任务;
(6)当最后一个参与者完成任务时,会唤醒队列中的线程并进入下一个阶段;
彩蛋
Phaser相对于CyclicBarrier和CountDownLatch的优势?
答:优势主要有两点:
(1)Phaser可以完成多阶段,而一个CyclicBarrier或者CountDownLatch一般只能控制一到两个阶段的任务;
(2)Phaser每个阶段的任务数量可以控制,而一个CyclicBarrier或者CountDownLatch任务数量一旦确定不可修改。
推荐阅读
3、死磕 java同步系列之JMM(Java Memory Model)
8、死磕 java同步系列之ReentrantLock源码解析(一)——公平锁、非公平锁
9、死磕 java同步系列之ReentrantLock源码解析(二)——条件锁
10、死磕 java同步系列之ReentrantLock VS synchronized
11、死磕 java同步系列之ReentrantReadWriteLock源码解析
13、死磕 java同步系列之CountDownLatch源码解析
15、死磕 java同步系列之StampedLock源码解析
16、死磕 java同步系列之CyclicBarrier源码解析
欢迎关注我的公众号“彤哥读源码”,查看更多源码系列文章, 与彤哥一起畅游源码的海洋。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号