第二章:深入分析java I/O的工作机制
。2.1 java的I/O类库的基本架构
I/O的机器获取和交换信息的主要渠道,在当今数据大爆炸时代,I/O问题尤其突出,很容易成为一个性能瓶颈,Java在I/O上也一直做持续的优化,现在也引入了NIO,提升了I/O的性能。
java.io下大概有80个类,主要分为以下4种:
◉ 基于字节操作的I/O接口:InputStream 和 OutputStream
InputStream和OutputStream的类层次结构。
写网络其实也是写文件,只是多了一步,就是让底层操作系统再将数据传送到其他地方而不是本地磁盘。
◉ 基于字符操作的I/O接口:Writer 和 Reader
Writer类的层次结构,Reader类的层次结构
不管是Writer类还是Reader类,它们都只定义了怎么写或怎么读,但是没有规定数据要写到哪里。
◉ 基于磁盘操作的I/O接口:File
◉ 基于网络操作的I/O接口:Socket(不在java.io包下)
前两组主要是传输数据的数据格式。后两组是传输数据的方式。
字节与字符的转化接口:数据持久化或网络传输都是以字节进行的,所以必须有从字符到字节或从字节到字符的转化。
字符解码相关类结构,字符编码相关类结构。
2.2 磁盘I/O工作机制
读入和写入文件I/O操作都调用操作系统提供的接口。只要是系统调用就可能存在内核空间地址和用户空间地址切换的问题。这是操作系统为了保护系统本身的运行安全,而将内核程序运行使用的内存空间和用户程序运行的内存空间进行隔离造成的。这样虽然保证了内核程序运行的安全性,但是也必然存在数据可能需要从内核空间向用户空间复制的问题。
访问文件的方式有以下几种:
1.标准访问文件的方式
访问:当应用程序调用read()接口时,操作系统检查在内核的高速缓存中有没有需要的数据,如果已经缓存了,直接返回,若无,直接从磁盘中读取,然后缓存在操作系统的缓存中。
写入:用户的应用程序调用write()接口将数据从用户地址空间复制到内核地址空间的缓存中。这对于用户来说写入操作已经完成。但是何时写入磁盘由操作系统决定,除非显式的调用sync同步命令。
2.直接I/O方式
应用程序直接访问磁盘数据,而不经过操作系统内核数据缓冲区。这样的好处是可以减少一次从内核缓冲区到用户缓存的数据复制。
这种访问方式通常是在对数据的缓存管理由应用程序实现的数据库管理系统中。例如:在数据库中,系统明确是知道应该缓存哪些数据,应该失效哪些数据,还可以对一些热点数据进行预加载,提前将热点数据加载到内存,可以加速数据的访问效率。
缺点:如果访问的数据不在应用程序缓存中,每次数据都会直接从磁盘上加载,这种直接加载会非常缓慢。
所以通常直接I/O与异步I/O结合使用,会得到比较好的性能。
3.同步访问文件的方式
数据的读取和写入都是同步操作。
与标准访问文件的方式不同的是:只有当数据被成功写到磁盘时才返回给应用程序成功的标志。
4.异步访问文件的方式
当访问数据的线程发出请求之后,线程会接着去处理其他事情,而不是阻塞等待。当请求的数据返回后继续处理下面的操作。
作用:明显提高应用程序的效率,但不会改变访问文件的效率。
5.内存映射的方式
操作系统将内存中的某一块区域与磁盘中的文件关联起来,当要访问内存中的一段数据时。转换为访问文件的某一段数据。
目的:减少数据从内核空间缓存到用户空间缓存的数据复制操作。
关于将数据写到何处,其中一个主要的方式就是将数据持久化到物理磁盘。
数据在磁盘中的唯一最小描述就是文件,文件也是操作系统和磁盘互动器交互的最小单元,Java中的File并不代表一个真实存在的文件对象,它会返回一个代表这个路径的虚拟对象。
只有真正读取这个文件时,才会检查文件存不存在。
java访问磁盘文件:
1.传入文件路径。
2.根据路径创建File对象来标识这个文件
3.根据File对象创建真正读取文件的操作对象FileDescriptor(文件描述符),通过这个对象可以直接控制这个磁盘文件
4.StreamDecoder类将byte解码为char格式
至于如何从磁盘驱动器上读取一段数据,操作系统帮我们完成。
如何将数据持久化到磁盘以及如何建立数据结构,取决于操作系统使用何种文件系统。
java序列化:将一个对象转化成一串二进制表示的字节数组,通过保存或转移这些字节数据来达到持久化的目的。需要持久化,对象必须继承java.io,Serializable接口。
反序列化:将这个字节数组再重新构造成对象。反序列化时,必须有原始类作为模板,才能将这个对象还原。
序列化的数据并不会像class文件那样保存类的完整的结构信息。
序列化数据中保存的信息:
1.序列化文件头:序列化协议,序列化协议版本,声明这是一个新的对象
2.要序列化的类的描述:声明一个新的class,class名字的长度,完整类名,序列化ID,标记支持序列化,包含的域
3.对象中各个属性项的描述:域类型(int),名字长度,属性的名称(例num)
4.该对象的父类信息描述:若有父类,。格式同 2,若无:对象块结束的标志,说明没有其他超类的标志。
5.对象的属性项的实际值:例:num的实际值
java序列化的一些情况总结:
当父类继承Serializable接口时,所有子类都可以被序列化。
子类实现了Serializable接口,父类没有,父类中的属性不能序列化(不报错,数据会丢失),但是在子类中属性仍能正确序列化。
如果序列化的属性是对象,则这个对象也必须实现Serializable接口,否则会报错。
在反序列化时,如果对象的属性有修改或删减,则修改的部分属性会丢失,但不会报错。
在反序列化时,如果serialVersionUID被修改,则反序列化时会失败。
用java序列化存储后,很难用其他语言还原出结果,尽量存储通用的数据结构,例如:Json或XML结构。
2.3网络I/O工作机制
ACK代表确认的意思。
TCP的三次握手:
发送端发送一个SYN=1,ACK=0标志的数据包给接收端,请求进行连接,这是第一次握手
接收端收到请求并且允许连接的话,就会发送一个SYN=1,ACK=1标志的数据包给发送端,告诉它,可以通讯了,并且让发送端发送一个确认数据包。
发送端发送一个SYN=0,ACK=1的数据包给接收端,告诉它连接已被确认
如何建立和关闭一个TCP连接?
1.在超时或连接关闭时进入CLOSED状态
2.Server端在等待连接时进入LISTEN状态
3.客户端发起连接,发送SYN给服务器端,这个是SYN-SENT状态。(如果服务端不能连接,则直接进入CLOSED状态)。
4. 第一种情况:服务端接收了客户端的SYN请求,变成了SYN-RCVD状态,同时服务器端回应一个ACK,发送一个SYN给客户端
第二种情况:客户端在发起SYN的同时收到了服务器端的SYN请求。客户端会由SYN-SENT状态转换到SYN-RCVD状态。
5.服务器端和客户端完成3次握手后进入ESTABLISHED状态,说明已经可以开始传输数据了。
6.主动关闭的一方,发生FIN给对方,进入FIN-WAIT1状态。
7.接收到FIN后同时发送ACK,被动关闭的一方进入CLOSE-WAIT状态(这里和原书顺序有差异,但不影响)
8.主动关闭的一方,收到了对方的对他发的FIN回应的 ACK,进入了FIN-WAIT2状态。
9.被动关闭的一方,发送FIN给对方,同时在接到ACK的同时进入了CLOSED状态。
10.若两边同时发起关闭请求(接收到一个FIN请求,同时相应一个ACK),会由FIN-WAIT-1状态直接进入CLOSING状态。
11.TIME-WAIT状态:
FIN-WAIT-2→TIME-WAIT 主动关闭的一方收到了被动关闭一方的FIN,于是发送ACK,于是进入TIME-WAIT状态。
CLOSING→TIME-WAIT 双方同时发起关闭,收到了对面对自己的回应ACK,进入TIME-WAIT状态。
FIN-WAIT-1→TIME-WAIT 同时接收到了对方发送的FIN和ACK回应。与CLOSING转换的区别在于,它的本身发起的FIN回应的ACK先于对方的FIN请求到达。CLOSING转换是FIN先到达。
将一份数据从一个地方正确的传输到另一个地方所需要的时间称之为相应时间。
影响这个响应时间的因素有:网络带宽(bit/s),传输距离,TCP拥塞控制(传输方和接收方的步调要一致,通过拥塞控制来调节,有一个TCP缓冲区)
java Socket的工作机制
建立通信链路:
客户端创建一个Socket实例,操作系统为这个实例分配一个没有被使用的本地端口号,并创建一个包含本地地址、远程地址和端口号的套接字数据结构。
tcp3次握手协议完成后,Socket实例对象将创建完成,否则抛出IOException错误。
服务端创建一个ServerSocket实例,操作系统为它创建一个底层数据结构,包含指定监听的端口号和包含监听地址的通配符,通常情况下是“*”,监听所有地址。
之后调用accep()方法,进入阻塞状态,等待客户端的请求。
数据传输:
传输数据是建立连接的主要目的。(这里涉及InputStream和OutputStream连接的底层类)。
由于可能会发生阻塞,所以网络I/O与磁盘I/O不同的是数据的写入和读取还要有一个协调的过程,如果两边同时传输数据可能会产生死锁。
2.4 NIO的工作方式
BIO带来的挑战:
BIO,即:阻塞IO。 数据在写入OutputStream或从InputStream中读取时可能会阻塞。一旦有阻塞,线程就会失去cpu的使用权。
在当前大规模访问量和有性能要求的情况下是不能被接受的。
解决方法:1.一个客户端对应一个处理线程,这样,出现阻塞只是一个线程阻塞而不会影响其他线程工作。2. 采用线程池的方法来减少线程的创建和回收的成本
解决不了的缺点:1.同时保持几百万的http连接时,不可能同时创建那么多线程来保持连接。2.给某些客户端更高的服务优先级时,很难通过设计线程的优先级来完成。3.这些客户端在不同线程中访问静态资源,所以需要同步,实现这种同步操作远比用单线程复杂得多。
NIO ,即:非阻塞I/O 关于NIO、BIO、AIO的区别,会另开一篇博客介绍。
Channel: 相当于汽车或高铁 ---------比socket要具体很多
Selector: 相当于车辆运行调度系统,负责监控每辆车的当前运行状态。
Buffer: 相当于车上的座位 ----------比stream具体 在buffer中我们可以控制buffer的容量,是否扩容以及如何扩容。
NIO工作方式的socket请求的处理过程:
1.调用selector的静态工厂创建一个选择器
2.把这个通信信道设置为非阻塞模式
3.调用selector的selectedkeys方法来检查已经注册在这个选择器上的所有通信信道是否有需要的事件发生。
4.如果有某个事件发生,将会返回所有的selectionkey
5.通过这个对象的channel方法就可以取得这个通信信道对象,从而读取通信的数据。
注意:一般在应用中,我们会把server端的监听连接请求的事件和处理请求的事件放在两个线程里。
线程一负责专门监听客户端的连接请求,而且是以阻塞的方式执行的
线程二负责专门处理请求,这个专门处理请求的线程才会真正采用nio的方式
Buffer的工作方式(selector检测到通信信道I/O有数据传输时,通过select()取得socketChannel,将数据读取或写入Buffer缓冲区,那么buffer是如何接收和写出数据的呢?)
Buffer:可以简单的理解为一组基本数据类型的元素列表,通过几个变量来保存这个数据的当前位置状态,也就是说,有4个索引。
capacity:缓冲区数组的总长度。
position:下一个要操作的数据元素的位置
limit:缓冲区中不可操作的下一个元素的位置,limit<=capacity
mark:用于记录当前position的前一个位置或者默认是0
例如:创建一个11 byte的数组缓冲区,并写入5个字节。
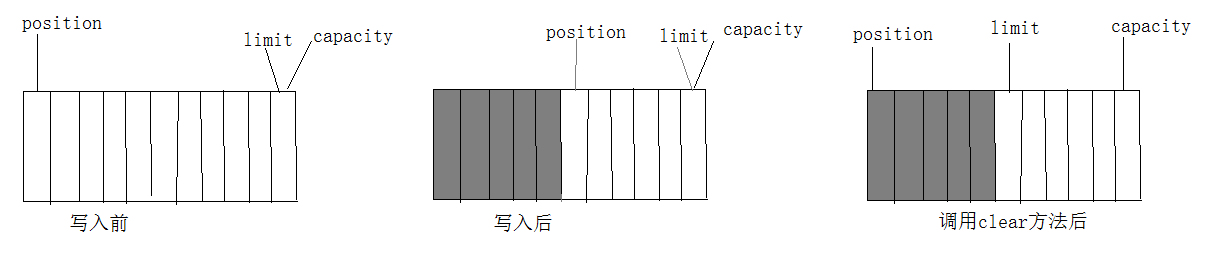
当我们调用mark()方法时,它将记录当前position的前一个位置,当我们调用reset时,position将恢复mark记录下来的值。
1.通过channel获取的I/O数据首先要经过socket缓冲区,再将数据复制到buffer中。这个操作系统的缓冲区就是底层的TCP所关联的RecvQ或者SendQ队列。
2.从操作系统缓冲区到用户缓冲区复制数据比较耗性能,buffer提供了另外一种直接直接操作操作系统缓冲区的方式,即:ByteBuffer.allocateDirector(size),这个方法返回的DirectByteBuffer就是与底层存储空间关联的缓冲区,它通过native代码操作非jvm堆的内存空间,每次创建或释放的时候都调用一次system.gc(),注意:这里有可能会引起jvm内存泄漏问题。
NIO的数据访问方式(FileChannel.transferTo FileChannel.transferFrom FileChannel.map)
1.FileChannel.transferXXX
与传统的访问文件方式相比可以减少数据从内核到用户空间的复制,数据直接在内核空间中移动。
2.FileChannel.map
将文件按照一定大小块映射为内存区域,当程序访问这个内存区域时将直接操作这个文件数据,这种方式省去了数据从内核空间向用户空间复制的损耗,适合对大文件的只读性操作 。
2.5 I/O调优
2.6 java I/O中的适配器模式
2.7java I/O中的装饰者模式
2.8 适配器模式和装饰者模式的区别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号