Postgres高可用环境搭建
Postgres高可用环境搭建
1. postgreSQL HA配置
基础PG的流模式加上pgpool软件实现双机热备,类似于Orical DG的FSF功能。pgpool-1与pgpool-2作为中间件,将主备pg节点加入集群,实现读写分离,负载均衡和HA,故障自动切换。两个pgpool节点使用一个虚拟IP节点,作为应用程序访问的地址,两节点之间通过watchdog进行监控,当pgpool-1宕机时,pgpool-2会自动接管虚拟IP继续对外提供不间断的服务。
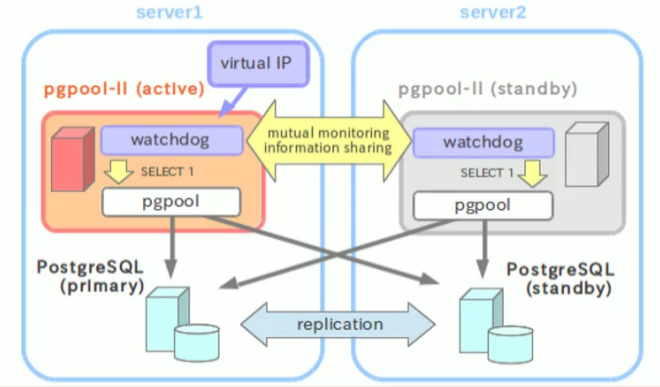
2.pgpool主备模式
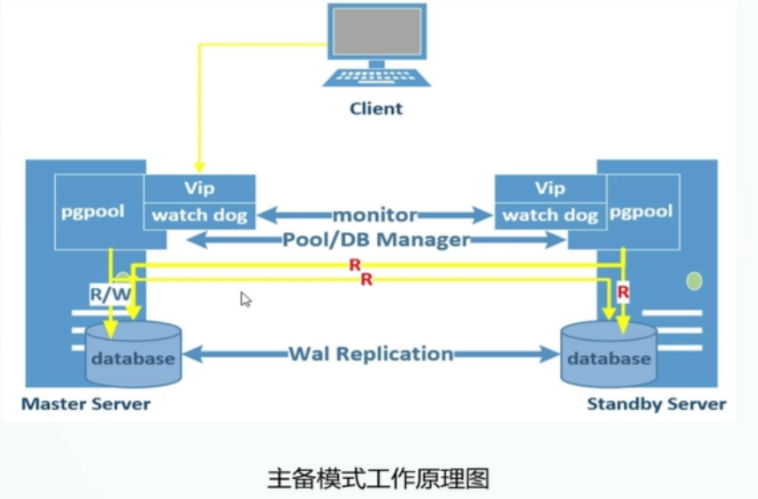
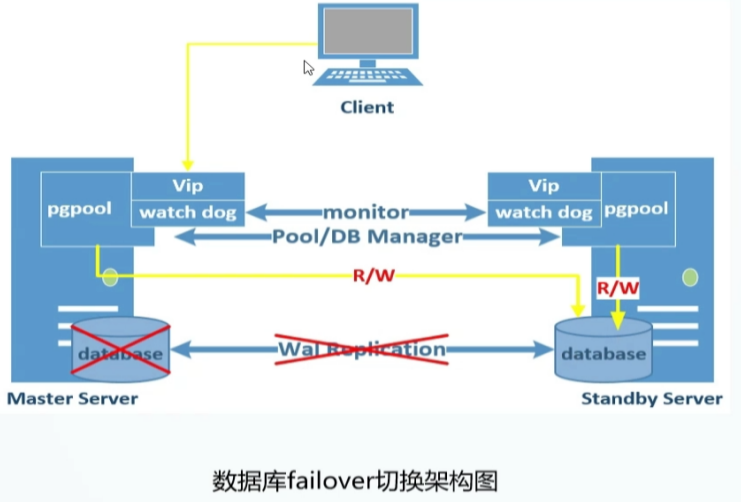
3.pgpool常用命令
# 查询 pgpool节点状态
psql -h 192.168.230.55 -p 9999 -c "show pool_nodes"
# 查看备库状态
psql -p 5433 -c "show transaction_read_only"
# 查看节点状态
psql -p 9999 -c "show pool_nodes" test
# 启动pgpool
pgpool -n -d > /tmp/pgpool.log 2>&1 &
show pool_version
show pool_nodes
show pool_status
show pool_pools
show pool_processes


主机规划
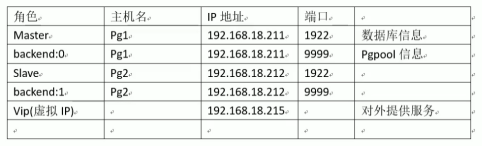
1.)配置域名
vim /etc/hosts
192.168.18.211 pg1
192.168.18.212 pg2
192.168.18.215 vip
2.)下载pgpool-3.7.13
下载地址:http://pgpool.net/mediawiki/index.php/Downloads
3.)配置节点互信
# pg1和pg2都执行以下命令,生成公钥
ssh-kengen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
# 公钥互相拷贝
scp ~/.ssh/authorized_keys postgres@pg2:~/.ssh/ # pg1主机
scp ~/.ssh/authorized_keys postgres@pg1:~/.ssh/ # pg2主机
# 验证,两个主机均执行如下命令
ssh postgres@pg2 uptime
ssh postgres@pg1 uptime
4.)安装pgpool
mkdir /usr/local/pgpool # root用户
chown postgres:postgres /usr/local/pgpool # root
cd /osft/pgpool-II-3.7.13
./configure --prefix=/usr/local/pgpool --with-pgsql=/usr/local/pg12.2/
make
make install
5.)安装pgpool相关的函数,可选,建议安装
cd /soft/pgool-II-3.7.13/src/sql
make
make install
cd sql
psql -f insert_lock.sql
6.)配置postgres用户环境变量(pg1,pg2)
vim .bash_profile
export PGPOOL_HOME=/usr/local/pgpool
export PATH=$PATH:$PGPOOL_HOME/bin
7.)配置pgpool
首先配置pg1上的pool_hba.conf,该文件是对登录用户进行验证的,要和pg的pg_hba.conf保持一致。
cd /usr/local/pgpool/etc/
cp pool_hba.conf.sample pool_hba.conf
vim pool_hba.conf
host replication repl pg2 trust
host replication repl 192.168.18.0/24 trust
host all all 192.168.18.0/24 trust
其次,配置pcp.conf(pg1,pg2),该文件用于pgpool自己登录管理使用的,一些操作pgpool的工具会要求提供密码等,比如节点的添加和删除等,配置如下:
cd /usr/local/pgpool/etc
cp pcp.conf.sample pcp.conf
# 使用pg_md5生成配置的用户名和密码
pg_md5 postgres
xxx
vim pcp.conf
postgres:xxx # xxx标识上面pg_md5生成的内容
配置pgpool.conf,在pgpool中添加pg数据库的用户名和密码(pg1,pg2)
# 创建pgpool.conf文件
cp pgpool.conf.sample-master-slave pgpool.conf
pg_md5 -p -m -u postgres pool_passwd
# 输入数据库登录用户postgres密码,生成pool_passwd文件
more pool_passwd # 查看生成的文件
最后,配置pgpool.conf,该文件是最核心的文件,HA是否能够正常云霄路,与该文件息息相关,该配置文件分为不同的模块,需要根据不同的模块来配置。





pg2主机上的pgpool.conf其他配置同上,不同之处如下:


8)切换脚本的编辑(pg1,pg2)
vim /usr/local/pgpool/failover_stream.sh

赋予执行权限:
chmod +x /usr/local/pgpool/failover_stream.sh
9.)设置ip arping等setuid权限,执行failover_stream.sh时会用到,否则无法启动IP(pg1,pg2)
chmod u+x /sbin/ip
chmod u+x /sbin/arping
10)启动集群守护进程
pg1、pg2启动数据库与pgpool进程
pg_ctl start -l pg.log
pgpool -n -d -D > /usr/local/pgpool/pgpool.log 2>&1 & #-d 标识debug状态
- 查看pgpool后台进程
ps -ef |grep pgpool
12)启动顺序:
先启动主库的pg数据库,然后再启动主库的pgpool守护进程,这样vip会在主库上生成,否则会在备库上产生,但是不影响业务的访问。可以看出vip是可以在不同的集群上漂移,跟以往的双机热备有区别的。接着再启动备库的pg数据库,最后启动pgpool进程。
13)故障切换
场景一:模拟主库pgpool进程中断,此时备库主机的pgpool会把vip接管过来,但是主备库的角色没有发生变化。
pgpool -m start stop
show pool_nodes; # 先连数据库,再查看
pg_controldata |grep cluster
场景二:模拟主库数据库关闭,pg_ctl -m fast stop 此处备库的pgpool切换脚本会把备库切换成主库,提供主库服务。检查postgresql.auto.conf文件,需要将primary_conninfo注释掉,否则不会承担主库的责任,向备库发送日志,重启数据库。
场景三:将原来的主库编程备库,创建standby.signal文件:


执行pg_ctl promote命令会进行主从切换,执行后发现standby.signal备删除了,查看最新状态pg_controlddata |grep cluster 原来备库的postgresql.auto.conf中自动添加了一行primary_conninfo的信息,需要把这行注释,否则虽然现在是主库,但是配置还是当做备库,日志会报错background worker logical replication launcher exited with exit code
启动备库,注意rewind会自动把standby.signal文件删除,以及修改postgres.auto.conf文件,需要手动修改,主库数据库如果管理或者发生异常中断,pgpool会将备库切换成主库,提供服务,不会影响业务,但是恢复主备库之间的关系,需要人为干预,不够智能。所以如果需要维护数据库,需要先停止pgpool进程再关闭主库,否则发生切换,害的修复备库。
14)压力测试
方法一:通过第三台机器网络连接测试:

方法二:pgbench工具测试
pgbench -c 30 -T 60 -h vip -p 9999 -U postgres -r postgres
pgbench -c 30 -T 60 -S -h vip -p 9999 -U postgres -r postgres # select压力测试,两个节点负载均衡
方法三:把备库脱离出集群,进行单机测试:
pcp_detach_node -h vip -p 9898 -U postgres -n 0
pgbench -c 30 -T 60 -S -h vip -p 9999 -U postgres -r postgres

 浙公网安备 33010602011771号
浙公网安备 33010602011771号