UCB算法(帮助做出最优选择的算法)
UCB(Upper Confidence Bound)算法是一种用于解决多臂老x虎机问题的启发式方法。多臂老x虎机问题是一种用以模拟现实世界决策问题的数学模型,其中“臂”代表不同的行动或选择,而“老x虎机”代表这些行动的随机结果。UCB算法的目标是在探索(exploration)和利用(exploitation)之间找到最佳平衡,以最大化累积奖励。
UCB算法的核心思想是为每个臂维护一个置信上界,这个置信上界是基于臂的历史奖励和被选择的次数计算得出的。算法在每一步选择具有最高置信上界的臂进行操作。这样,算法会倾向于选择那些既有较高期望奖励又较少被探索的臂。
UCB算法的关键步骤包括:
1. 初始化:为每个臂设置初始的估计奖励和计数器。
2. 选择:对于每个臂,计算其UCB值。UCB值通常由以下公式给出:
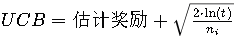
其中,t 是当前的回合数, ni是第 i 臂被选择的次数,估计奖励是第 i 臂的平均奖励估计。
3. 更新:选择具有最高UCB值的臂,并观察其结果。
4. 重复:重复步骤2和3,直到达到某个终止条件,如达到最大回合数或达到特定的性能标准。
UCB算法的优点是它不需要对奖励分布的先验知识,并且可以适应性地调整探索和利用的平衡。UCB算法在理论和实践中都得到了广泛的研究和应用,特别是在在线推荐系统、广告投放、临床试验设计等领域。
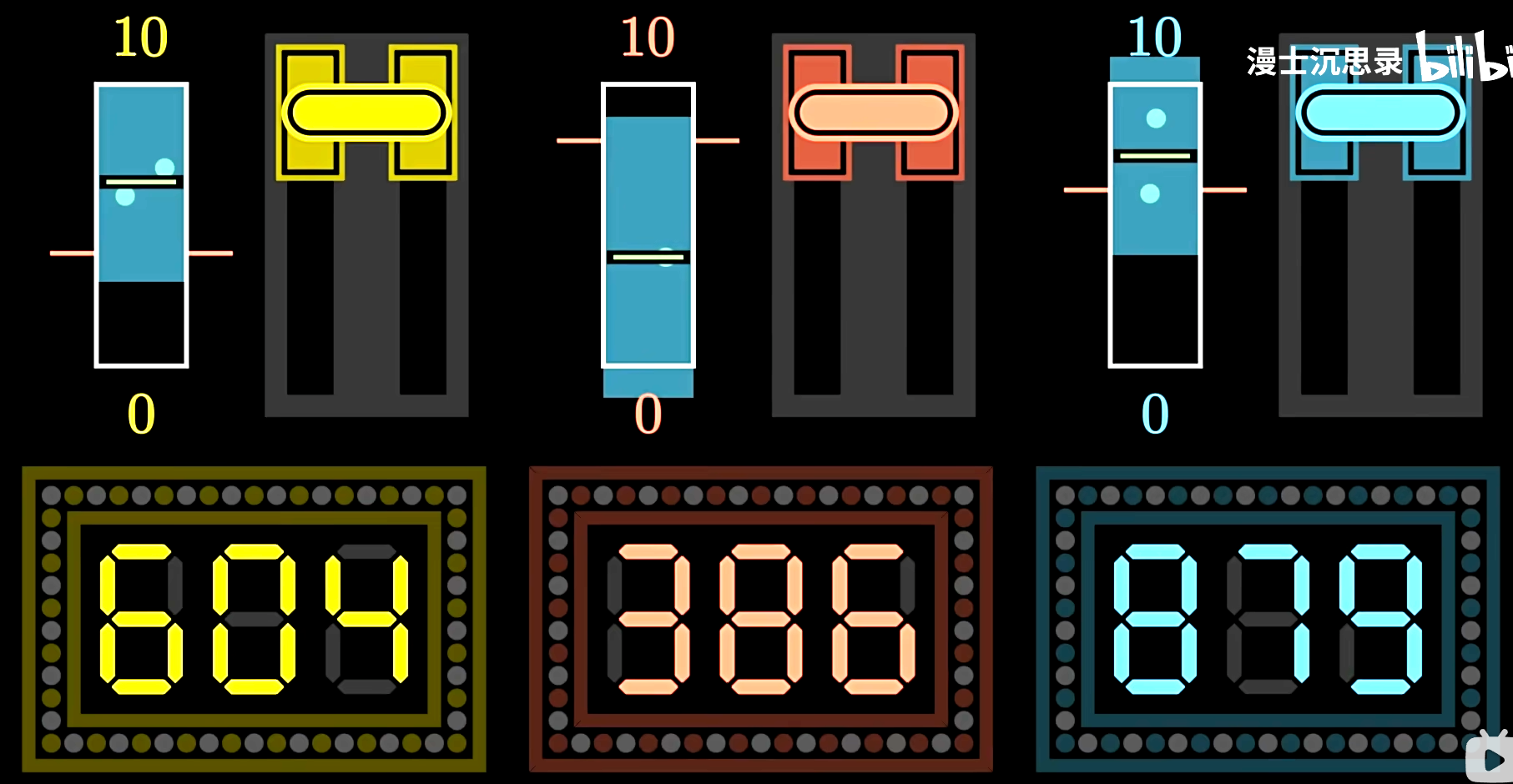
假如说你需要吃饭,你可以选择麦当劳,肯德基和汉堡王
你前三次分别尝试了肯德基,汉堡王和麦当劳。
你点的套餐是其中一种牛肉汉堡的套餐。你觉得汉堡王最好吃,那么你第4次选择了汉堡王,你尝试了别的套餐,汉堡王没有给你和上次一样好的感受,那么汉堡王的估计奖励就降低了,汉堡王的UCB参数也降低了,而麦当劳和肯德基的UCB参数随着回合数的增大,以及因为没有被选择次数的增加而增加了。直到可能麦当劳的UCB参数变大,你尝试了麦当劳,麦当劳给你的感觉依然很好,那么你尝试麦当劳的次数会增大,麦当劳的乐观加分会变小,但是由于麦当劳的估计奖励非常稳定的高,慢慢的就让平均估计奖励趋于了真值。最终你发现麦当劳是最优选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号