python 入门
type(183) 显示的是183的数据类型int
print("183")显示183
print(183,172)显示183172
age=10
name=strehd
print("%d %s"%(age ,name))显示的是10 strehd
还有一张传参形式 print(f" {name} 11{age}")显示的是strehd1110
9//2=4
9%2=1
9**2=81
%m.nd比如%7.2d,限制了数字的宽度和精度 宽度给了7,如果数字宽度大于7,m无效,精度是四舍五入保留n位
print("345*567的结果是%d"%(345*567))
输入语句input用法,input接受的内容通通是视作字符串类型
number=input()
可以用number=int(number)转换类型
bool
可以用比较运算符显示truefalse
== !=
while循环语句
比较讲究格式对齐来区分内外层循环结构
格式是while 条件:
if条件:
else:
while 条件:
内部动作
执行外部动作
print("")是会自动换行的,怎么做到不自动换行呢
print("hello",end=' ')
print("world",end=' ')
制表符\t是表示将print扩展到8个单位的空间比如hello\tworld 会变成hello world
for循环
和c c++不同 python中的for循环感觉功能没有那么强大
格式是for 变量 in 数据集:
里面写执行语句
range语句 range(num)
比如说我range(6)就是生成{0,1,2,3,4,5}
或者range(num1,num2)
range(1,6)就是生成{1,2,3,4,5}
或者range(1,6,2)就是生成{1,3,5}
遇到了continue
循环就会中断,回到循环开始的地方重新执行
写法是for x in range(1,6):
print("语句一")
continue
print("语句二")
print("语句三")
这样语句二不会被打印,语句一打印5次后打印语句三
break跳出循环,直接执行循环外的下面的语句
函数写法
def 函数名 (参数):
写函数体
调用方法
函数名(参数)
也可以有return 返回值
如何将函数内的变量定义为全局变量
用global修饰,比如global num
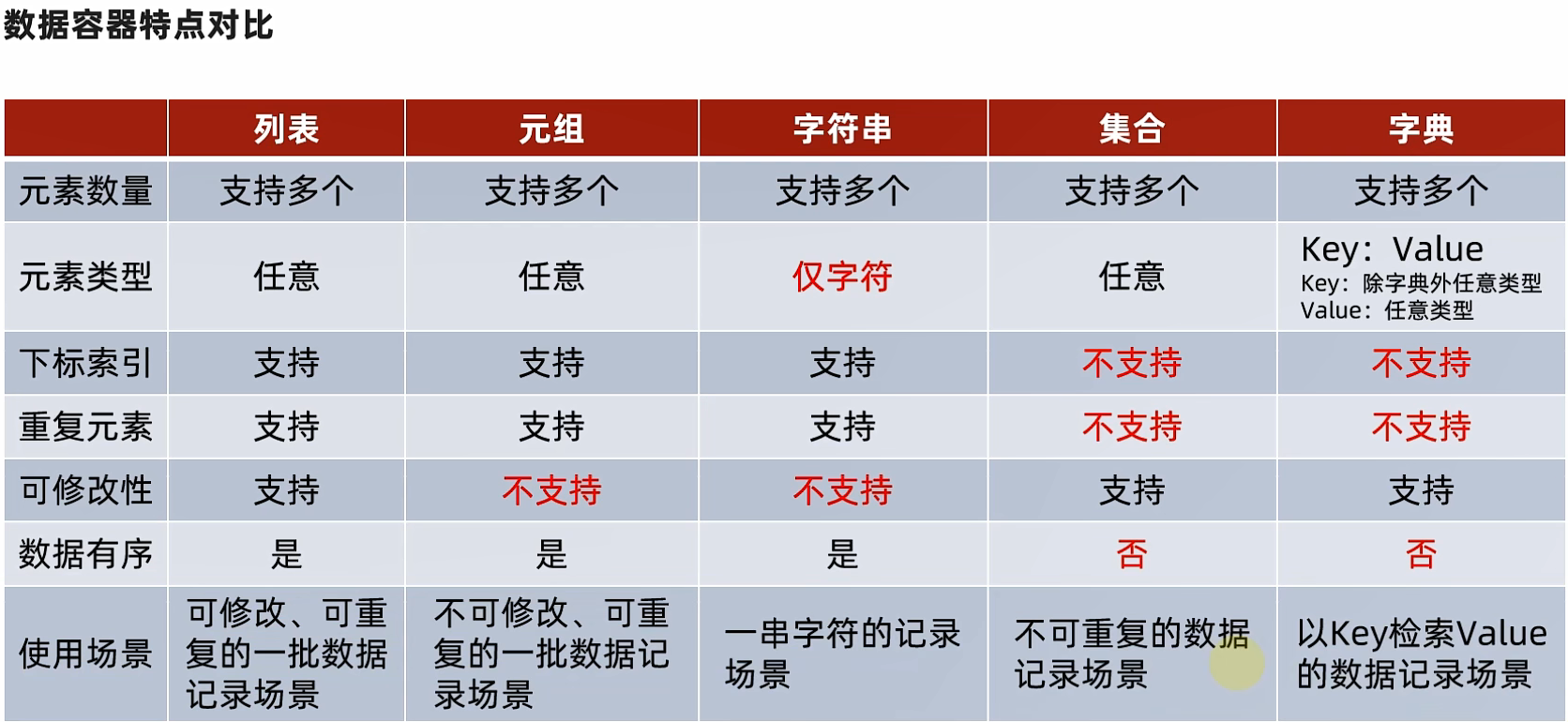
学习数据容器
数据容器有:列表(list)元组(tuple)字符串(str)集合(set)字典(dict)
列表(list)
写法:name_list=[' a',' b','c ','x ' ,'s ']
当然里面元素的数据类型是什么都可以,不受限
怎么索引列表内的元素呢???
下标索引print(name_list[0])
下标索引别超出范围了会报错
倒序索引
print(name_list[-1])
print(name_list[-2])
print(name_list[-3])
列表方法
class student:
def add(self,x,y):
return x+y
student1=Student()
num=student1.add(12,34)
解释完了方法是什么,我们来学习列表的查询功能
查找列表中指定元素的下标,找不到的话会报ValueError
写法:列表.index(元素)
修改列表内元素的值:
列表名[下标]=值
插入元素:
列表名.insert(下标,插入的元素)
插入的元素会在下标的位置,原下标的元素会往右移一位
列表名.append(元素)
会在列表的尾部添加元素
在列表尾部添加一堆元素怎么办???
用列表.extend(其他数据容器)
写法:列表名1.extend(列表名2)
删除列表元素方法1:del 列表[下标]
方法2:列表名.pop(下标)
这个方法2还能把pop出来的元素记录,比如element = 列表名.pop(2)
列表.remove(元素):删除列表中出现的第一个要删除的元素
比如list1=[1,2,3,22,2,2,2,2,2,3,4,5,5]
list1.remove(2)就是拿走list1[1]的这个2
list1就变成[1,3,22,2,2,2,2,2,3,4,5,5]
清空列表:列表名.clear()
统计某元素在列表内的数量:列表名.count(元素)
比如list1.count(22)
今天来学习用while循环语句将list容器遍历:
使用给列表中的元素定义下标,让下标的值不超过列表的长度来实现循环
比如
index=0
listnumber1=[1,2,3,4,5,6,7,8,9,7,6]
while index<len(listnumber1):
a=listnumber1[index]
print(f"现在的a是{a}")
index+=1
这样我们就遍历了listnumber1,提取出了里面的元素并输出了他们
现在我们来学习用for循环语句将list容器遍历:
for 变量 in 容器:
对变量进行操作
这么说的话
listnumber2=[1,3,4,5,8,9,0,0,7,6]
for x in listnumber2:
print(x)
这样就完成了对listnumber2容器的遍历
今天我们学习元组
列表list是可以被修改的,很不好的一点是这些数据会被篡改。
如果想要不被别人篡改但是要分享,list就不合适了
元组和列表一样,可以封装多个、不同类型的元素
但是元组一旦被定义,不可被修改
定义元组:用小括号(),用逗号隔开元素,数据类型可以不同
比如:
elements=('au','se','re','yui')
这样得到了有内容的元组
t2=()
t3=tuple()
这是一个空的元组
这个也是一个空的元组
怎么定义一个只有单个元素的元组???
t4=("hello",)
这个逗号非常关键,有它才是元组
元组通过下标索引其中元素和list是一样的
写法:元组名称[下标]
或者嵌套元组的话 元组名[下标][下标]
由于元组不可修改的性质,有很多list方法是不能用的
index方法
index1=元组名.index(要查找的元素名)
这样index1就存放了元素在元组中的下标
count方法
number2=元组名.count(要查找的元素名)
这样number2就存放了这个元素在元组中的数量
len方法
lengthhowmuch=len(元组名)
这样lengthhowmuch会显示元组元素的数量
元组的遍历:while循环来遍历元组
while index <len(元组名):
index=0
print(f"元组的元素依次是{元组名[index]}")
index+=1
for循环遍历元组
for element in 元组名:
print 元组名[element]
元组的内容是不能修改的
但是元组中如果嵌套了一个list,那么这个list的值是可以修改的
比如tupel1=(1,2,3,4,[2,3,4,5])
tuple1[4][0]="sexylady"
print(tuple1[4][0])
字符串容器
字符串支持下标索引,写法:
变量名=字符串名[index]
这里index指的是下标,即0,1,2,3这样子的字符在字符串中的位置
字符串和元组一样是不可修改的容器,也就是说
添加元素append()、修改指定下标的字符 :字符串名[index]="a"、移除特定下标的字符字符串.pop()、字符串.remove()、del 字符串[index] 这些操作都是不可以的
替换原字符串的字符,让这个操作存放在新的字符串内
newstr=my_str.replace("it","wild")
这个操作下来my_str不变内容,newstr内容就是替换了my_str里面的it成wild的新字符串
replace(old:"" ,new:"" )前一个地方传参是原字符串的想要被替换的字符内容,后一个地方传参是要被替换上去的字符内容
my_str="itheima and itcast"
b=my_str.split(" ")可以将字符串my_str按照空格进行拆分,变成一个列表b
print(b) 打印出来为['itheima','and','itcast']
strip用法 写法:字符串.strip()意思是字符串前后的空格会被去除
如果写法是 字符串.strip(12)那么字符串前后的1、2这两个字符都会被去除
count用来统计字符串中出现的字符的次数
写法:字符串名.count("字符")
统计字符串的长度用len()
字符串只可以存储字符串,允许重复,支持for循环
序列
常用操作:切片
写法: 序列[起始下标:结束下标:步长]
步长是1的话,其实相当于按顺序取数,所以可以不写步长
如果说是要遍历序列来取,那么起始结束下标也可以省略不写,但是冒号要写的
如果说什么都不写,那么就写成序列[ : ]
如果说步长是-1,那么从开始取到最后就是从后向前取,回文数!
集合容器
空集 set()
有元素的集合set1={1,2,3,1,2,3,4,1,2}
print(set1)会输出{1,2,3,4}
集合是不允许重复元素的,这很好理解
集合是无序的,也就是说你不能通过下标索引的方式访问里面的元素
集合和list是一样的,可以修改里面的元素
怎么修改呢???
set1.add("python1")#添加元素
set1.remove(1212)#移除了集合中叫1212的整型元素
set1.pop()#随机取数
set1.clear()#清空集合
set3=set1.difference(set2)#取两个元素的差集,就是set1里面有的而set2里面没有的
set3=set1.difference_update(set2)#消除两个集合的差集,就是在set1里面去除set2里的元素
print(set2)#不会被修改
print(set3)#set1里的元素,并且里面没有set2里的元素
set3=set1.union(set2)#合并两个集合,也就是取全集
set1和set2的内容不会变
len(set1)#统计集合元素数量(会去重的)
for x in set1:
print(f"集合的元素有{x}") #遍历集合
字典容器
字典存在的意义是通过字去找到字的含义
也就是key对应value--> key:value
写法:
字典名={key:value,key:value,key:value}
空字典定义:
字典名={}
或者
字典名=dict()
字典是不允许key重复的,会自动舍弃掉重复的key
字典是通过key取到value,不可以通过下标去取到
写法是 字典名[key]
字典可以嵌套使用。字典的key是可哈希的,不能是可修改的
怎么访问嵌套后的字典里的数据呢???
字典名[key1][key1.1]
字典名[key]=value#修改值或新增键值对
情况1:如果key不存在,就新增一对键值对
情况2:如果key存在,修改value的值
字典名.pop(key)#取出元素或者说删除元素
字典名.clear()#清空元素
keys=字典名.keys()#获取全部的key
for x in keys:
print(f"字典的key值是{x}") #遍历字典
print(f"key所对的值是{字典名[x]}"
字典中有几个键值对呢???
num=len(字典名)
max(容器名称)
min(容器名称)
容器转列表 : list(容器名称)
容器转元组:
容器转字符串:
容器转集合:
容器转字典是没有的
sorted(容器名)#对容器元素从小到大排序
sorted(容器名,reverse=True)#对容器元素从大到小排序
字符串是怎么进行大小比较的???
通过比较ASC||码
字符串之间是一位位比较的,其中一位大,后面就不用比了
函数进阶
函数多个返回值问题
如果一个函数有两个return:
def test_return():
return 1
return 2
那么执行完第一个return就会退出当前函数,也就是说第二个return不会执行
那么如何返回多个返回值呢???
def test_return():
return 1,2,3,"hello"
x,y,z,q = test_return()#这里的x,y,z,q是分别返回了1,2,3,"hello"
返回值的类型不受限
函数的多种传参
函数:
def hanshu(name,gender):
print(f"他的名字是{name}性别是{gender}")
位置传参
hanshu("小明","male")
关键字传参
def hanshu(name="xiaoming",age=20,gender="male")#通过键值对的形式来传入参数
不按照固定顺序
def hanshu(age=2,gender="female")
和位置参数混用,位置参数必须在前面,还要匹配参数的顺序
hanshu("xiaoming","20",gender="male")
缺省传参
比如说函数是def hanshu(gender='男',age)
print(f"{age}")
那你调用函数写 hanshu()
会默认gender='男'
设置默认值的话,多个参数,设置了默认值的参数要放在最后,否则会报错
不定长参数、也叫可变参数
def hanshu(*args):
print(args)
这个args是指接受数量无限的参数,收录成一个元组给函数
def hanshu(**kwargs)
print(kwargs)
hanshu(name='Tom',age=18,gender='nan',id=1880)
++这个kwargs就是接受所有的键值对,并把键=值收录,组成字典
函数作为参数 传参
比如
def hanshu1(hanshu2):
result = hanshu2(1,2)
print(result)
def hanshu2(x,y)
return x+y
hanshu1(hanshu2)
这是把一种计算逻辑传递进另一个函数,而不是把参数这个数据传递进去
lambda匿名函数
函数定义可以是def 加上函数名
也可以是lambda 加上传入的参数:函数体 #这个就只能用一次不能重复调用
传参这里写的是形参,函数体只能写一行
具体的作用就是比如之前函数作为参数传参的话
def hanshu1(hanshu2):
result1=hanshu1(2,3)
print("result1")
def hanshu2 (x,y):
return x+y
hanshu1(hanshu2)
是不是很长?现在我们用lambda
def hanshu1(hanshu2):
result=hanshu2(1,2)
print("result")
hanshu1(lambda x,y:x+y)
这个hanshu1()括号里的东西就是一次性的函数hanshu2,可以算作是一次性的定义了hanshu2的运算逻辑来对hanshu1里面的参数进行逻辑运算
文件编码
计算机只认识0和1
所有的文本内容都可以被翻译成0和1的组合,计算机认识了以后,再翻译回来给你
这个翻译的过程就是编码
编码是用编码本或者说密码本来实现的,不同的编码会让相同的文本变成不同的二进制
比如说我们的文本文档就是用UTF-8来实现的编码,我们看到的文本都是通过这个编码看到的
一般来讲,现在主流的就是用UTF-8编码
我们对文件进行的操作:读 写 打开 关闭
打开一个文件:f=open("文件路径","访问类型",encoding="解码类型")
比如说要打开一个D盘的文本文件,
f=open("D:/wenjianming.txt","r",encoding="UTF-8")
read()可以读取文件
比如说这个文件,我想读取10个字符
我可以f.read(10)
read()一次之后,第二次read()会从上次结束的地方开始read,你可以理解成这个光标就是指在上次结束的地方
#读取文件的全部行
duhang=f.readlines()
这个读取完的所有行会存放在list中
当然,读取所有的行,读取的操作他光标是会停留住的,也就是说如果你前面用read()读了两行字符,那么你readlines()会从第二行的指针位置继续下去,上面度过的两行就不会读取并存放成列表了
那么怎么能够又读了数据
又读全部行呢
不知道
readline()#一次读取一行数据
如何用for循环读取所有行数据呢
因为文件默认一行是一个元素,所以
for line in f:
print(f"每一行数据是{line}")
就可以了
当然这个line不是什么关键词,你换成dawugui,sexylady也是可以的
#关闭文件
程序不关闭就会一直占用着内存
f.close()#停止文件对内存的占用
with open
怎么写呢,有什么用呢???
with open("文件路径","访问类型",encoding="解码协议"):
操作
with open 的用处就,你在这个with open():这个冒号后面写的东西,这一大瓜子操作完她会帮你自动关掉这个文件。
duixoang2=对象名.strip()#可以去除开头和结尾的空格以及换行符
#对文件进行写入操作
文件名.write('helloworld')
#内容刷新
文件名.flush()
那么这个flush()有什么用呢
当我们对文件进行了 文件名.write("写的内容")操作以后 写的内容会在程序中新建一块内存存放这块内容
那么直到我们close()或者flush()操作以后,那么这块在程序内存中的内容才会正式的写入文件中,存入硬盘内
time.sleep(1000000)#让程序睡1000000秒
如果说你write()操作是对一个里面有内容的对象,它会把里面的内容清空再做写入操作。
a模式
append的意思,就是说对文件进行追加写入操作
不会在对文件清空后写入,而是接着原有的内容写下去
#python异常
很好理解,我们最熟悉的bug
捕获异常
世界上没有完美的程序,我们能做到的就是在力所能及的范围内,对可能出现的bug进行提前准备提前处理
这种行为,我们就叫做捕获异常(异常处理)
写法:
try:
可能发生错误的代码
except:
如果出现异常要执行的代码
也就是说设计了一个try plan A if plan A failed try plan B
你也可以捕获指定的异常
使用
try:
xxxx
except 异常名 as 变量名:
xxxxx
如果要捕获多个异常,那就可以使用元组的形式把这些异常写在一起
try:
xxxx
except (异常名1,异常名2) as 变量名:
xxxxx
我想捕获所有的异常,可以吗???
当然可以我们用
try:
except:
写法或者
try:
except Exception as e:
这两种写法都是可以的
好,我们接着写下去
try:
xxxxxx
except:
xxxxxx
else:
xxxxxx#如果没有异常,那么我们try完还可以else 继续做事情,这样的话我们就可以把我们担心的可能会出现问题的代码和我们不担心的分割开来了,如果说报错,不做了,没报错的话,做。
finally:
xxxxxxx#这个是无论有没有bug都要执行的代码。
异常的传递性 异常是具有传递性的,比方说我在函数1里面的东西写错了,报了异常。我在函数2中调用了函数1,我在主函数中调用了函数1和函数2,我在主函数中捕获异常,那么我可以捕获到函数1的异常吗???
是可以的,我们会在函数1,函数2,主函数里都捕获到异常。
python模块
模块就是一个python文件,里面有类、函数、变量等等,我们可以导入模块用里面的东西。
模块的导入方式:
[from 模块名] import [模块|类|变量|函数|*] [as 别名]#中括号的意思是这些东西是可选的,也就是可以写可以不写
常见的组合形式:
import 模块名
from 模块名 import 类、变量、方法等
from 模块名 import *
import 模块名 as 别名
from 模块名 import 功能名 as 别名
比如我们从time模块导入sleep函数
那么就这么写:from time import sleep
*表示全部的意思
比如说from time import *
就是说time模块里所有的东西我全都要
那么跟import time这个写法有什么不同呢??
功能是一样的,都是可以用time模块的所有功能
写法不一样上面那个如果要调用sleep函数需要写time.sleep()
而如果是写from time import *的话,调用sleep可以只写sleep()
from time import sleep as sl#偷懒,后面可以直接写sl()代替sleep(),意思是一样的
如果是import time as t
那以后写time.sleep就可以写成t.sleep
#自己制作自定义模块
新建一个Python文件,命名为my_module1.py,并定义test函数
如果说在两个不同名的模块里有两个同名不同实现的函数,那么我们先导入模块1里的函数,再导入模块2里面的函数
事实情况就是你调用这个函数的话,模块2的函数会被调用,前一个导入的函数声明会被后一个声明覆盖。
如果说我们在自己开发的模块里调用了自己定义的函数,那么当我们把这个模块导入到别的文件中去用的时候,也是会执行模块中的调用函数操作的。
那么就很烦,我既需要对这个自己开发的模块进行测试,我又要调用它去方便我其他文件的开发,我又不想在开发的时候执行我的测试用例,怎么办???
我们可以打出一个main,系统会提示我们输入这么一行:if _ _name_ _=='_ _main_ _':
在这一行下面写的东西就是说不会去别的文件内执行了,这个name变量是每个文件内置的变量,当我from这个模块文件调用xxx的时候,这个name就不是这个文件了,就变成了调用者文件名,所以这一层if下面的代码就不会被执行了。
如果说我们在模块文件写上一个_ _all_ _=[test_a]
那么我们在from 模块名 import *的话,我们所有能调用的东西就是这个test_a函数了
那我现在想要调用模块文件里的test_b怎么办???
那我们就写from 模块名 import test_b 这样就可以了,这个all的写法是针对*用的
#python包
为什么会有python包,如果说模块太多了,会造成管理上的混乱,这个时候需要报来管理模块
如果说模块是一个一个的文件,那么包就是那个文件夹
形式上的话,module1,module2是文件,当然里面要有一个特殊的python文件: _ _init_ _.py
这个文件在文件夹内的时候,这个文件夹才能被叫做python包
调用包内的模块,就写成import 包名.模块名 或者from 包名.模块名 import 模块函数名
我们可以在 _ _init_ _.py文件里面写上 _ _all_ _=['函数1']
这样的话 就是说你import 包名 from*的话,就里面的函数1是可用的了
python的第三方包:
科学计算常用:numpy
数据分析常用:pandas
大数据计算常用:pyspark、apache-flink
图形可视化常用:matplotlib、pyecharts
人工智能常用:tensorflow
因为这些包是第三方开发的所以要安装,导入,才能使用
JSON是一种轻量级的数据交互格式。可以按照JSON指定的格式去组织和封装数据
JSON本质上是一个带有特定格式的字符串
主要功能:json就是一种在各个编程语言中流通的数据格式,负责在不同编程语言中的数据传递和交互,类似于:英语 普通话 这种语言的感觉
我们怎么将json翻译成python???
首先import json
python转化为json格式的文件 名=json.dumps(python格式文件,ensure_ascii=False)#将python格式的东西转换成json格式的方法,中文不动输出
json转化为python格式的文件 名=json.loads(json格式文件)#json格式转化成python文件的方
学习数据可视化:pyecharts
比如说我现在要指定一个折线图反映三个国家gdp的值
那么首先,导包: from pyecharts.charts import Line
然后我们声明一个变量来存放调用Line类的实例返回值
line=Line()
现在这个line具备Line()定义里面的性质,我们给它调用函数方法录入数据
line.add_xaxis(["中","美","英"])
line.add_yaxis("GDP",[30,20,10])
至此我们已经构建好了我们想要的一张折线图,现在我们想看到这张图
line.render()#render是呈现的意思,我们渲染完之后出现图像
pyecharts有很多对于图标元素的配置。
分为全局配置和系列配置,我们看看全局配置
可以使用set_global_opts方法来进行配置,全局配置主要是对什么做添加和改变呢???
主要是图标的一些标题元素、大的一些框架,工具箱的配置,视觉效果的配置。
方法的使用就是比方说你要给这张图加全局配置,那就line1.set_globai.opts(这个里面就可以调用全局配置里的各种方法来配置你需要的东西)
比如说我们要给图标一个标题,line只是逻辑上它的名字,这个名字的存在只是为了创建一个对象来接受Line()的返回值
那么我们先from pyecharts.options import TitleOpts
然后我们全局配置的话
line.set_global_opts(
title_opts=titleoptions(True,"GDP值写于20231217"),
)
这边我使用的是位置传参,也就是按照函数方法定义时规定的参数顺序把参数类型对应的东西传进去。
我们可以按CTRL+P查看传参具体信息。
那么我们看到这个标题是在左上角显示的,有没有办法移动它到我们想要的位置呢???
具体的写法是:pos_left="center",pos_bottom="1%" #position距离left是center的位置 position距离bottom的长度是1%
那么我们还要别的配置,怎么加
就是在这个set方法里面加
记得我们加完一行比如说我们要工具箱功能
我们写toolbox_opts=ToolboxOpts(is show=True),
写完这一行后这个逗号要加上非常重要别忘记了。如果不加的话,后面import的函数方法是不会被成功创建、引用的
那么功能太多了我记不住或者说我不知道具体怎么写怎么办????
看官网上面有的。
框架有了,现在我们学一下怎么处理数据,就是说形式搞好了,现在搞内容。
我们要学会用json模块处理数据
首先我们得到的json文件很可能是不规范的,里面有垃圾信息和不符合格式的信息,我们要通过代码去去除这些东西,那么庞大的信息我们怎么去看,或者说怎么将数字们变成我们看得懂的东西,这就是数据可视化。
我们把标准的json文件复制后,打开网站ab173.com 或者http://www.esjson.com
我们通过这个网站去呈现这个数据文件代码的核心:两个字典,key status对应value 0,key msg对应value success 一个字典,key data对应value是一个[ ] 也就是list形式的value,在这个list里面有两个字典,一个字典key name对应value 美国 一个字典key trend 对应value 是一个{ }也就是dictionary形式的value,在这个dictionary里面有两个字典,一个是key updataDate 对应value是一个list[ ],这个list里面存放的是544个字符串型的元素,还有一个是key list对应一个value list[ ],这个list里面有四个字典,都是按照name:“ ” data:[ "" ,""....]
的形式存放的。
我们现在搞清楚了它这个文件写的代码是什么意思,我们也知道了我们要取的数据怎么取,现在我们通过代码把这个json文件里我们要的东西取到我们的python文件里然后通过pyecharts来可视化出来。
首先我们要处理数据,我们读取文件
对我们不需要的不规范的信息进行字符串的替换
那么如果说我们原字符串在文件中重复的太多,我们存在一个误删的操作,这个方法就不能用,我们通过给序列切片的操作来取数据,比如我只要这整个文件除去最后两个字符的文件,怎么切片???
我们写 序列名[:-2]#这个省略了开始切片的位置和切片步长,默认我们从头开始切片,步长是1,结束切片的位置是倒数第二个元素,也就是说倒数第二个元素之前的所有东西我都要了。
怎么理解-2是不包含倒数第二个元素的???如果说我们不写的话,是不是默认我们要了最后一个元素,那么我们写了-1的话,我们是不是最后一个元素不要了,那么我们写-2的话,我们倒数第二个就不要了。
接下来是对规范的json文件进行类型转换,使用json.loads()将json文件变成python文件。
接着按照字典序的查找语法取出trend数据,并将日期存入x轴变量,人数存入y轴变量。
最后render一下图。
折线图line我们就学到这里。
地图map
学map的话,主要是一个visualmapopts里面我们写
is_show=true,
is_piecewise=True,
pieces=[
{"min":1,"max":34,"label":"1-34人","color":"##FFFF"},
{},
]
我们第一步的话打开文件,读取数据,关闭文件,
我们把json文件转换成python文件,这样字典型的文件就有了
我们从字典里面取出数据以后,把需要的两组数据变成一对,存在元组里面,然后一对一对一对是排列存放在一个列表里面
#柱状图
基础的柱状图怎么建???
from pyecharts.charts import Bar
from pyecharts.options import *
bar11=Bar()
bar11.add_xaxis(["中国","美国","英国"])
bar11.add_yaxis("GDP",[12,20,30])
bar11.render("我想起的名.html")
这样就建好了
bar11.reversal_axis()#对调或者说翻转x和y轴
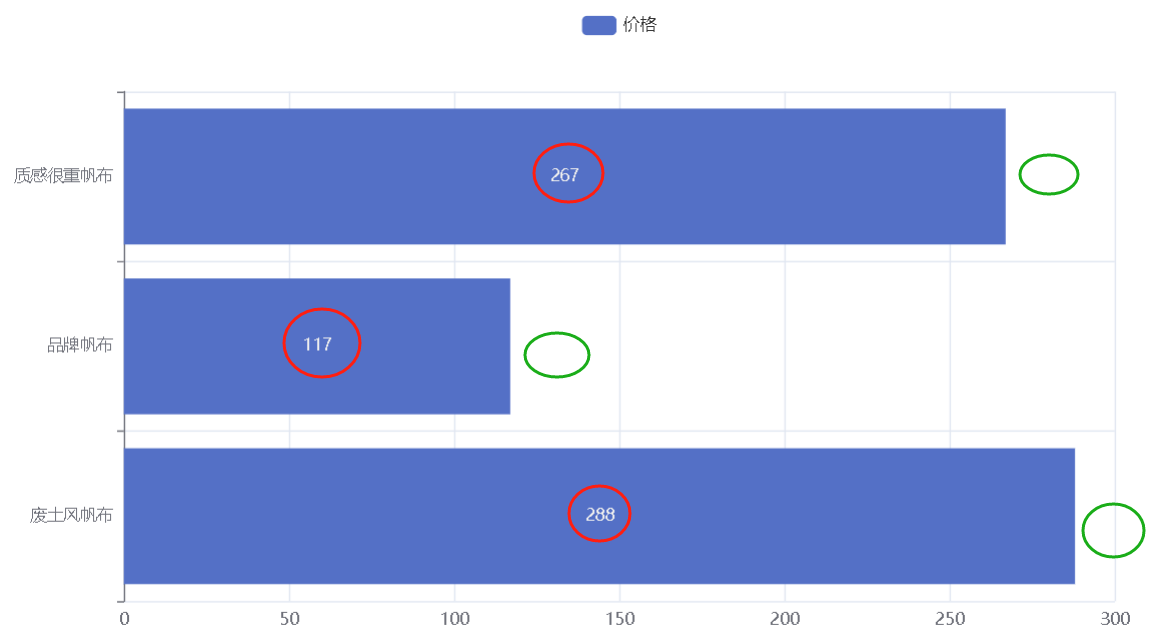
我们现在想解决一个小问题,我们想让这个数字在绿色处显示。
怎么做???
我们在bar11.add_yaxis("价格",[288,117,267],label_opts=LabelOpts(positon="right"))#标签位置是bar的右边
我们来学一下#基础的时间线配置动态图表
然后我们要学习#设置主题更改颜色样式
柱状图很难描述动态的变化,我们这里结合时间线来补足这个缺点
Timeline() 时间线
时间线是什么样子的一种模板呢???
就是一个一维的x轴,上面每一个点对应一个bar图表
Timeline 是一个方法,它是在pyecharts.charts里面的
然后我们#创建时间线
timeline1=Timeline()
#添加bar1,bar2进去
timeline1.add(bar1,"2021年GDP")
timeline1.add(bar2,"2022年GDP")#这里这个"2022年GDP"是会显示在时间线上面的标签,不是这张bar2表的表标题。
现在我们解决第二个小问题
让时间线自动播放和自动循环播放
我们需要写一个
timeline1.add_schema(
play_interval=1000,#自动播放的时间间隔,单位是毫秒
is_timeline_show=True,
is_auto_play=True,#自动放
is_loop_play=True#自动循环
)
设置时间线的主题
timeline1=Timeline(
{"theme":ThemeType.LIGHT}
)
这边主题的话
有WHITE LIGHT DARK CHALK ESSOS INFOGRAPHIC MACARONS PUPPLE_PASSION ROMA ROMANTIC
我们来学GDP动态柱状图的绘制
第一步:sort方法对列表排序,配合lambda匿名函数
第二步:完成需求的数据处理
第三步:绘图
列表里面我们学过sorted方法,但这个方法不能按照自定义的规则排序
写法就是:
列表名.sort(key=你排序用的函数,reverse=True|False)
#参数key,是传入一个函数,表示将列表的每一个元素传入函数中,返回排序的依据
#参数reverse ,是否反转排序的结果,True是升序,False是降序
匿名函数的写法就是直接写一行代码在这个sort方法里面去声明函数
列表名.sort(key=lambda element:element[1],reversse=True)#意思就是我传入这个lambda函数,接受变量叫element,我们按照element[1]位置的元素来排序,降序排列
或者我们写带名函数
def havenametosort(element):
return element[1]
用的话,把havenametosort写到key=后面就可以了
接下来我们对数据进行处理以满足我们对可视化的要求
1,数值的单位是亿
2,数值标签在bar右
3,只显示rank前8个
4,显示表的标题,年份随时间轴变化
5,做时间轴
ANSI是windows的默认编码格式
我们如果用的编码格式是GB2312的话,我们就可以看的更方便。
# 面向对象编程
好比我们设计一张表格,打印这张表格让人去填写
我们设计类,就是设计这张表格
class Student:
name=None
我们打印出这张表格,就是创建了对象
stu_1=Student()
我们填写这张表格,就是给类里面定义的变量去赋值
stu_1.name="小王"
好我们来写一下
class Student:
name=None
gender=None
nationality=None
native_place=None
age=None
stu_1=Student()
stu_1.name="小王"
print(stu_1.name)
#类的定义和使用的语法
#成员方法的使用
#self关键字的作用
python写类的话
class 类名:
类的属性(成员变量)
类的行为(成员方法)
对象名=类名()#创建类的对象
我们可以在类里面写函数,意思就是这个类会有这个函数方法,我们可以用对象.函数名()的方式来调用
类内定义的函数,我们叫成员方法,简称方法
也就是说以后我们说函数,那就是类外的东西,类内的叫方法。
成员方法的定义方式是
def 方法名(self,形参1,形参2.....形参N):
方法体
这个跟函数的定义差了一个self关键字,如果你写的是成员方法,一定要写这个self,这个self你在位置传参的时候是不影响的,第一个传进去的参数就是形参1会去接受参数
这个self有什么用呢???
我们在这个成员方法的内部写方法体,如果我们要访问类内的变量,我们一定要用self 写法就是比如类内我有个name变量,那么我在方法体里面写name我要写self.name
#什么是面向对象
类只是设计图纸,对象是把图纸上的东西造出来了,这就是面向对象编程
设计类,生成对象,对象来干活
我们传变量的参数很麻烦,
stu_01.name="小兄弟"
stu_01.gender="男"
..............
有没有办法方便的传参呢一次性传呢???
用_ _init_ _()方法,这个叫构造方法
它有两个用处:
1,在创建类的对象的时候,会自动执行方法,无需调用
2,在创建类的对象的时候,将传入的参数自动传递给__init__方法使用
#我们来实现一行代码传入要传的变量参数
class Student:
name=None
gender=None
phonenum=None
def __init__(self,name,gender,phonenum):
m self.name=name
self.gender=gender
self.phonenum=phonenum
stu_01=Student("小张","男","1234567889")
类里面的属性可以不写,只要在构造函数里面赋值的时候就相当于自动定义了
#常用的类内置方法
这些类的内置方法,各自有特殊功能,我们叫他们:魔术方法
魔术方法:
__init__ 构造方法
__str__ 字符串方法
__lt__ 小于、大于符号比较
__le__ 小于等于、大于等于符号比较
__eq__ ==符号比较
等等等等。。。。。
魔术方法的命名就是在方法名的前后有"__方法名__"这样两个下划线
#__str__ 字符串方法
我们在打印对象的时候,会打印这个对象指向的地址,没什么用。我们想看到这个对象的静态属性
这个时候我们在类内写字符串方法
def __str__(self):
return f"学生的姓名:{self.name},性别:{self.gender},手机号:{self.number}"
#__lt__ 小于、大于符号比较
def__lt__(self,other):
return self.age<other.age#这边你想写什么都是可以的,本质就是重写了运算符,这里就是说在写了stu1和stu2用"<"比较的时候,就是在比较stu1和stu2的年龄大小。
我们写完后比如print(stu1<stu2) 如果stu1<stu2,那就会输出True
#__le__ 小于等于、大于等于符号比较
def__le__ (self,other):
return self.age<=other.age#这边你想写什么都是可以的,本质就是重写了运算符,这里就是说在写了stu1和stu2用"<="比较的时候,就是在比较stu1和stu2的年龄大小。
#__eq__ ==符号比较
def__le__ (self,other):
return self.age==other.age#这边你想写什么都是可以的,本质就是重写了运算符,这里就是说在写了stu1和stu2用"=="比较的时候,就是在比较stu1和stu2的年龄大小。
#封装
其实就是把成员变量和成员方法都装在类里,那么也不是说我装在类里的东西,你调用了类创建了对象,都可以给你用
比如一台手机,你买了。你可以用的功能,它有。它还有你不可以用的功能,它也有。
这些不给你开放的功能,就是类中的私有成员变量和私有成员方法
怎么定义私有成员变量和方法呢???
在变量/方法名前面写上两个下划线:
__变量名=None
def __方法名(self):
#类的对象无法访问类中私有成员,类中的其他成员是可以访问类的私有成员的
我们通过一个手机具有私有的5g开关方法,公有的打电话方法来体会到私有成员的意义是什么
我的手机用户不需要知道我的5g开关是怎么实现的,5g能不能用,开了没开的判断细节是厂商的私有成员
将这些实现细节对用户隐藏,可以方便用户调用打电话的功能,也保护了手机厂商的开发隐私。
这个其实就是体会到了封装
#继承
iphone从6出到8,长得差不多
iphone从X出到15 ,长得差不多
这体现了继承的思想。
比如说我原来设计的手机,有厂商序列号,有4g通话功能
现在我要新出一个手机,我是重新写4g功能,重新写序列号再往上加5g功能,面部识别功能还是直接在之前的类里面加上去呢???
我们继承类的写法是:
class phone2022(phone):
face_id=True
def call_by_5g(self):
print("2022最新5g通话")
也就是说父类叫phone
子类叫phone2022
那么我们的写法就是class 子类(父类):
内容体
继承分为单继承和多继承。上面实现的是一个单继承,也就是把父类的非私有的成员变量和方法都复制过来,具有了。
我们学习一下多继承:
写法就是class 子类(父类1,父类2,.......,父类N):
类内容体
比如说我们写了一个手机类,里面只放了手机的型号和序列号。
我们写了一个NFC读卡器的类,里面是实现这个读卡器的变量和方法。
我们写了一个红外遥控器类,里面有实现红外遥控功能的变量和方法
现在我要写一个小米手机类,这一类的小米手机是同一批次的,具有红外遥控,nfc功能
那么我就写成class xiaomiphone(手机,红外遥控器,NFC读卡器):
类内容体
如果说你现在这个子类,已经通过多继承实现了需要的功能,你一个字都不用写了,但是按照语法规则,你在类内容体内需要写点什么
这时候就可以写上pass关键字,这个就代表这里什么都没有。
如果说子类继承的父类1父类2有同名的成员变量,那么先输出靠近子类的父类的成员变量,也就是谁越靠左,谁优先。
#复写
子类对父类提供的功能不满意,我们通过复写来修改。
写法:
比如说父类里面有一个方法是
def call_5g(self):
print("父类的5g")
子类里面写成
def call_5g(self):
print("子类5gnb")
复写的话,方法名相同,重写里面的函数体的实现就可以了。
成员属性的复写是一样的,改变值就可以了,变量名保持相同。
复写以后再调用复写后的方法,会调用子类的方法。
那么这样的话如果说我成员变量也在子类里面复写过了
当我想调用父类的成员,该怎么做呢???
#第一种方法
父类名.成员变量
父类名.成员方法(self)
#第二种方法,用super()
super().成员变量
super().成员方法()
这个应用场景就比如说,我这个手机要在5g通话上设计一些UI上去,那个手机要在5g上面设计另一些UI上去
如果说我子类1重写了父类的5g通话,那么我子类2在1的5g通话上面根本改不了,但是由于子类1已经重写了父类方法,调用不到父类的5g方法,所以这里用到这两种方法就可以让子类2调用到基础的5g实现了。
#类型注解
为什么使用类型注解???
当我们在pycharm上面打了一个list.ap的时候,
会有浮窗提示我们有append(self,object)
那么为什么pycharm的工具能够知道这个对象有append方法的?
因为PyCharm确定这个对象是list类型的
而比如说我们
def func(data):
data.app
我们想的是这个data接受list,然后往data里面去加元素
但是这个时候pycharm就不知道data是什么类型的了,也就无法提供list的append方法了。
为什么内置的模块可以让pycharm知道类型,自己定义的pycharm就不知道数据类型
这就是为什么要使用类型注解!!!
写法
比如说我们有一个变量 a=10
我们现在写一下让a是整型的
a:int=10
也就是说在变量后面加上":类型"
对容器的类型注解和对变量是一样的,如果要对容器内的变量进行注解
可以是list1:list[int]=[1,2,3,4]
tuple1:tuple[str,int,bool]=("itheima",666,True)
dic1:dict[str,int]={"heima":234}
也可以在注释里写,比如
a=10 #type:int 这个在注释里写成这样是有效果的
那么当我们调用包的方法的时候,我们打出方法名,按alt+enter可以自动去找方法名对应的包,自动去导包
#对函数方法的形参做类型注解
还是老例子,
def func1(data):
data.app
func1()#data
跳不出来list的append方法提示,也不提示data传什么类型的数据进去
类型注解写法:
def 函数名(形参:类型名,形参:类型名,。。。。):
pass
这样就可以了,跟变量的注解很像。
#对函数方法的返回值做类型注解
def 函数名(形参:类型名,。。。。)->返回值类型:
pass
就是在函数的冒号前面写上箭头返回值的类型
#union类型
前面的数据都非常的干净
我们搞一个脏一点的:
list1=[1,2,"itheima","speed"]
dict1={"name":"tom","age":18}
这种无法通过list1:list[int] dict1:dict[str,str]来描述的情况怎么办呢???
我们
from typing import Union
那我们的写法是
list1:int[Union[int,str]]=[1,2,"itheima","speed"]
dict1:dict[str,Union[str,int]]={"name":"tom","age":18}
Union[]的意思就是这个对象里面有的数据类型,我这里都有,联合了这些类型。
像是在函数的形参,返回值的注解里面,也可以这么写
(形参:Union[类型名1,类型名2],。。。)->Union[类型名1,类型名2]
#多态
多态就是说不同的对象在完成某个行为时展现不同的状态
比如说行为是飞
飞机的飞和鸟类的飞,有不一样的状态。
虽然都是fly()
但是在各自类里都重写了fly方法的实现细节
也就是说同样的一个函数,传入的对象不同,得到的状态不同
那么我们可以将父类写成一个空有方法名,没有方法实现的抽象类,因为行为是抽象的,实现行为的动作是特殊化的,具体的。
这个就叫做顶层设计
真正去工作的是抽象类的子类,抽象类负责制定子类的行为。
比方说我们
def makecoolwind(airconditioner:AC):
aironditioner.makecoolwind()
midia1=media()
gre11=gree()
makecoolwind(midia1)
makecoolwind(gre11)
传入的是抽象类的子类作为参数
得到的返回值是两个子类各自的状态
#用面向对象的设计思路实现从json,text文件,到柱状图。
SQL入门和实战
为什么学python要学SQL,SQL语言是开发人人必备的技能
在大数据的实际操作中,我们需要使用SQL完成数据的存储与处理
当然SQL语言博大精深,这里就简单的掌握
#基础语法
#MySQL数据库软件的基础使用
数据分为数据的存储、数据的计算
编程是对数据的计算
数据的存储通过TXT、EXCEL,这些是日常的存储。
在开发人员眼里,是用数据库来存储数据的。
Excel存储数据的话,我们会把报名登记表和宿舍分配表两个表格放到2021年文件夹里
那么数据库的话,就是把两张表放到2021数据库里,说白了数据库就是文件夹
也就是说索引数据是按照库--表--数据的形式去调用数据的
怎么管理数据库形式的数据呢??我们要借助数据库管理系统,也就是数据库软件
比如oracle mysql sqlserver postgresql
数据库在存储数据的过程中会用到SQL语言。
SQL语言就是一种对数据库、数据进行操作、管理、查询的工具。
我们这里使用的数据库软甲是MySQL
MySQL是由瑞典的DataKonsultAB公司研发的,这家公司被Sun公司收购,Sun公司又被Oracle公司收购,现在MySQL是Oracle旗下的产品
MySQL分为社区版和商业版。体积小 速度快 拥有成本低,一般开发都选MySQL作为数据库
免费版:
MySQL Community Server#社区版本,免费,MySQL不提供官方支持
MySQL Cluster#集群版,开源免费,可将几个MySQL Server封装成一个Server
收费版:
MySQL Enterprise Edition#商业版,收费版本,可以试用30天,官方提供技术支持
MySQL Cluster CGE#高级集群版,需付费
我们用第一个
SQL按照功能分为
数据定义:DDL(Data Definition Language)
数据操纵:DML(Data Manipulation Language)
数据控制:DCL(Data Control Language)
数据查询:DQL(Data Query Language)
SQL对大小写不敏感,可以单行、多行书写,最后用分号";"结尾
SQL的注释:
单行注释: -- 注释的内容(--的后面有一个空格)
单行注释:# 注释的内容
多行注释:/* 注释的内容*/
什么叫可以多行书写???
不是写一行给一个分号
分号是在写完SQL语句之后写上分号,表示我写完了
#学习DDL(Data Definition Language)
关于库-------------------------------------------
-- 库管理
show databases;
-- 使用数据库
use 数据库名;
-- 查看当前使用的数据库
select database(); #可以通过选中语句来单独运行选中的语句
-- 创建数据库
create database 数据库名[charset utf8]; #这边的中括号[ ]表示可选,也就是说中括号里的东西是可写可不写的,不是说要把中括号写上去
create database 数据库名;#这样也是可以的
create database 数据库名 charset utf8;#这样也是可以的
-- 删除数据库
drop database 数据库名;
关于表---------------------------------------------------
-- 查看库中有哪些表
show tables;
-- 创建表
create table 表名称(
列名称 列类型,
列名称 列类型,
列名称 列类型
);
#列类型有int float varchar(长度) date(日期类型) timestamp(时间戳类型)
varchar(8)表示这个数据是文本类型的 限制这个数据的长度是8,长度限制最大是255
-- 删除表
drop table 表名;
drop table if exsits 表名;
#学习DML(Data Menipulation Language)
#掌握INSERT
#掌握DELETE
#掌握UPDATE
INSERT语法:
INSERT INTO 表名[(列1,列2,.......,列N)]VALUES(值1,值2,.......,值N)[,(值11,值21,.......,值N1),(值12,值22,.......,值N2),(值1N,值2N,.......,值NN)]
基本上就是insert into 表名[(这里写需要被插入的列的名称)]VALUES[(这里写被插入的列对应的插入的值)][这里是可选的,如果想插入两列数据给这一列]
#!!!!!!中括号是不写上去的,知识表达一个可选的意思
##写法
INSERT INTO 表名(列名称1,列名称2)VALUES(插入的数据,插入的数据),(插入的第二份数据,插入的第二份数据),(插入的第三份数据,插入的第二份数据);#这边如果说只选择部分列插入部分数据,别的地方的数据会用NULL补上,不会报错。
varchar型的数据,在插入的时候要用' '或" "括起来的
这边我们省略的写法可以是:
INSERT INTO 表名VALUES(值1,值2,.......,值N)#把可选都不写了 相当于位置传参了
DELETE语法:
DELETE FROM 表名[WHERE 条件]#条件是 列 判断符 值
UPDATE语法:
UPDATE 表名 SET 列名=值[WHERE 条件]
#学习DQL(Data Query Language)
#SELECT基础查询
SELECT 字段列表|*FROM 表名[WHERE 条件]
*就是全选
字段列表就是列名 可以写成列名1,列名2
如果说我想通过多个条件来筛选需要显示的数据,用&&和||来连接多个条件,&&表示且,||表示或
#GROUP BY分组聚合查询
比如说我们有一个需求,#统计班级中男生和女生的人数#
第一步,按性别分两个组
第二步,统计每个组的人数
分组聚合是两步
#分组
SELECT [列名,]聚合函数 FROM 表名[WHERE 条件] GROUP BY 列名
这个意思就是按照GROUP BY 的列名进行分组,按照聚合函数进行对值的操作
#聚合
聚合函数有
AVG(列名)#求平均值
COUNT(列名)#求数量总和
SUM(列名)#求和
MIN(列名)#求最小值
MAX(列名)#求最大值
当然我们举个例子,我们一张表有id name age
现在我通过姓名分组,求得age>35的AVG(age),我显示name,AVG(age),这样是可以的,avg是一个值,按照姓名分组后,这个组里都是一个姓名。
现在如果我SELECT name,id,AVG(age)FROM 表 WHERE age>35 GROUP BY name 是会报错的,你说这些叫oldlady的平均年龄43.5,用谁的id?id数据是没有共性的。
##归纳下,分组聚合时没有被group by的 不能被select ##
一条分组聚合语句里面可以写多个聚合函数的。
#对查询的结果进行排序ORDER BY
写在DQL语句的最后 ORDER BY 列名[ASC|DESC] #升序|降序
#对查询结果进行分页或者限制查询的数量LIMIT
LIMIT n [ , m]
#意思就是查完的数据,我只想显示n行数据,n,m表示我要从第n条开始往后取m条
那比如10,5 就是从第10条开始,往后取5条,那么就是第11,12,13,14,15条数据
我们的DQL语句顺序是
SELECT 列名|聚合函数|* FROM 表名
WHERE 条件
ORDER BY 列名[desc|asc]
LIMIT n [,m]
#Python 操作MySQL
第一步 调库 pip install pymysql
第二步 创建到MySQL的数据库链接
from pymysql import Connection
conn1=Connection(
host='localhost',
port=3306,
user='root',
password='826020'
)
第三步,写SQL语句,分为非查询/查询性质语句
#非查询性质
cursor1=conn1.cursor()#第一步,获取游标对象
conn1.select_db("库名")#选择数据库 这里相当于MySQL里面的use 库名
cursor.execute("CREATE TABLE student_female(id int,info varchar(255))")#这里是用cursor.execute(创建表)来创建了一张表
#查询性质
cursor1=conn1.cursor()#第一步,获取游标对象
conn1.select_db("库名")#选择数据库 这里相当于MySQL里面的use 库名
cursor.execute("SELECT*FROM student_female")#用cursor执行查询语句
result:tuple=cursor.fetchall()#获取查询语句,用.fetchall()方法 这边的result接收数据库里的东西默认是元组型的。
for r in result:
print(r)
conn1.close
输出的形式是((),(),())
大元组嵌套小元组,一个小元组是一行的数据
#学习数据插入
插入数据的操作是不能通过cursor.execute("插入数据的代码")
这种操作实现的,为什么啊???
pymysql在执行数据插入或者其他产生了数据的更改的SQL语句时,默认时需要提交(或者说上报)更改的,就是说需要通过代码‘确认’这种更改行为。
怎么做呢???
通过链接对象.commit()就可以确认此行为。
在通过cursor.execute(执行SQL语句)后
写上conn1.commit()
就可以了,就是确认了插入数据的操作。
或者方法二:
在conn1=Connection(
autocommit=True#设置自动提交
)
是一种更简便的方法
#案例 使用SQL语句和pymysql库开发
#pyspark实战
spark是apache旗下的分布式计算框架,调动成百上千的服务器集群来计算很大的数据量
spark框架对python语言的支持:pyspark第三方库
pyspark库可以当作普通的python库来调用功能进行数据处理
或者把数据处理部分的代码提交到spark集群中进行分布式计算
为什么要学习pyspark???
python的两大应用场景是大数据开发和人工智能
pyspark coding第一步,获取SparkContext类对象
STEP1导包
from pyspark import SparkConf,SparkContext
STEP2创建SparkConf对象
conf1=SparkConf().setMaster("local[*]").\
setAppName("test_spark_app")
STEP3创建SparkContext对象
shengcheng1=SparkContext(conf=conf1)
#这里通过.version看一眼sparkcontext对象的版本
print(shengcheng.version)
#shengcheng.stop()#停止PySpark程序
spark编程的模型就是
要有一个SparkContext的类对象作为一个入口
第一步是input data,通过一个RDD对象的各种方法来处理数据
第二步是处理数据
第三步是output data
ison文件,数据库数据,文本文件。。。都会被转化为这个SparkContext类对象,然后这个SparkContext类对象会自动变成RDD类对象
通过RDD的各种成员方法(算子)之后,输出成list tuple形式、文本文件形式、数据库数据。。。
RDD(Resilient Distributed Datasets)#弹性分布式数据集
通过SparkContext类对象的parallelize方法,可以将python里面的数据容器对象转化为PySpark的RDD对象
写法
rdd1=shengcheng1.parallelize(数据容器对象)
如果要查看rdd的内容,用collect()
各种数据容器类型,在输出的时候都是按照list形式输出,字符串会按照单个字符输出,字典型只会输出key不会输出value
我们有了rdd对象,就可以调用非常丰富的API
#用textFile方法,读取文件到spark,变成rdd对象
rdd1=shengcheng1.textFile("要读取的文件路径")
#RDD的map方法
map算子:功能是将rdd的数据按照一条条的处理(处理的逻辑就是map方法会接受一个处理rdd文件的函数作为参数),返回新的rdd
rdd1.map(func1).map(func2)
#链式调用
#RDD的flatMap方法
简单来讲,flatmap方法就是对rdd做map操作以后,做解除嵌套操作。
#解除嵌套
list1=[[1,2,3],[4,5,6],[7,8,9]]#嵌套的list
list2=[1,2,3,4,5,6,7,8,9]#解除了嵌套的list
我们拿到SparkContext类对象后:
rdd=shengcheng2.parallelize(["a b c","sd jg yh","oie jiu hua"])
rdd2=rdd.map(lambda x: x.split(" "))
print(rdd2.collect())
#正则表达式re
re.findall(r'\d+',text)
r'\d+'表示匹配一个或多个数字
text表示在其中查找匹配的字符串

 浙公网安备 33010602011771号
浙公网安备 33010602011771号