
pyspark 基本api使用说明(一)
1.Array Schema转换到Sting Schema ——array_join()方法
使用案例:
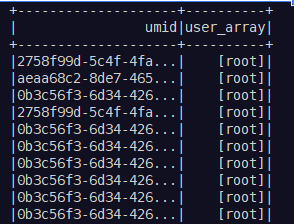
原始数据如下图所示:
df.show()
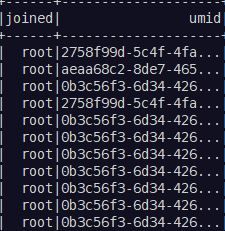
df1 = df.select(array_join(df3.user_array, ",").alias("joined"), 'umid', 'user_array')
df1.show()
2.Sting Schema 转换成 Array Schema
其中,主要有以下三种方式:
2.1 split()方法
2.2 Array()方法
2.3 自定义udf函数(灵活,但是效率低)
案例:
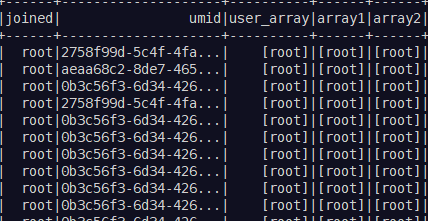
原始数据如上图所示,
df2 = df1.withColumn('array1', array('joined')).withColumn('array2', split(col('joined'), ','))
df2.show()
3.针对Array[Array]Schema,变换成Array[String]的方法——flatten()方法
pyspark中flatten()方法,实现的功能类似于下面的案例:
[1,3,[4,5], [7,9.9]] --->(flatten)----->[1,3,4,5,7,9,9]
4.字符串聚合操作——collect_set \ collect_list
这两个都是针对String类型的聚合操作,类似于数值类型的sum、avg等,使用案例为
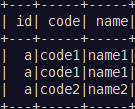
df = spark.createDataFrame([
("a", "code1", "name1"),
("a", "code1", "name1"),
("a", "code2", "name2"),
], ["id", "code", "name"])
df.groupBy('id').agg(collect_set('code').alias('collect_set_test'), collect_list('name').alias('collect_list_test')

备注:
1)collect_set和collect_list的区别是:collect_set实现去重的功能。
2)针对Array Schema的DataFrame直接落地es中,需要额外注意(将在下节中,spark数据库连接中进行特殊说明)
posted on 2020-10-27 16:09 random_boy 阅读(685) 评论(0) 编辑 收藏 举报


