爬虫11天——selenium实战
一、目的:爬取阳光视频网的多个视频,下载到本地
二、网站分析:
1.网站结构分为:视频列表页和视频详情页
2.右键检查视频列表网页:

发现:每条视频都是一个class叫"title-box"的div,然后视频详情页的链接在这个div下面的a标签
3.进入视频详情页,检查网页:
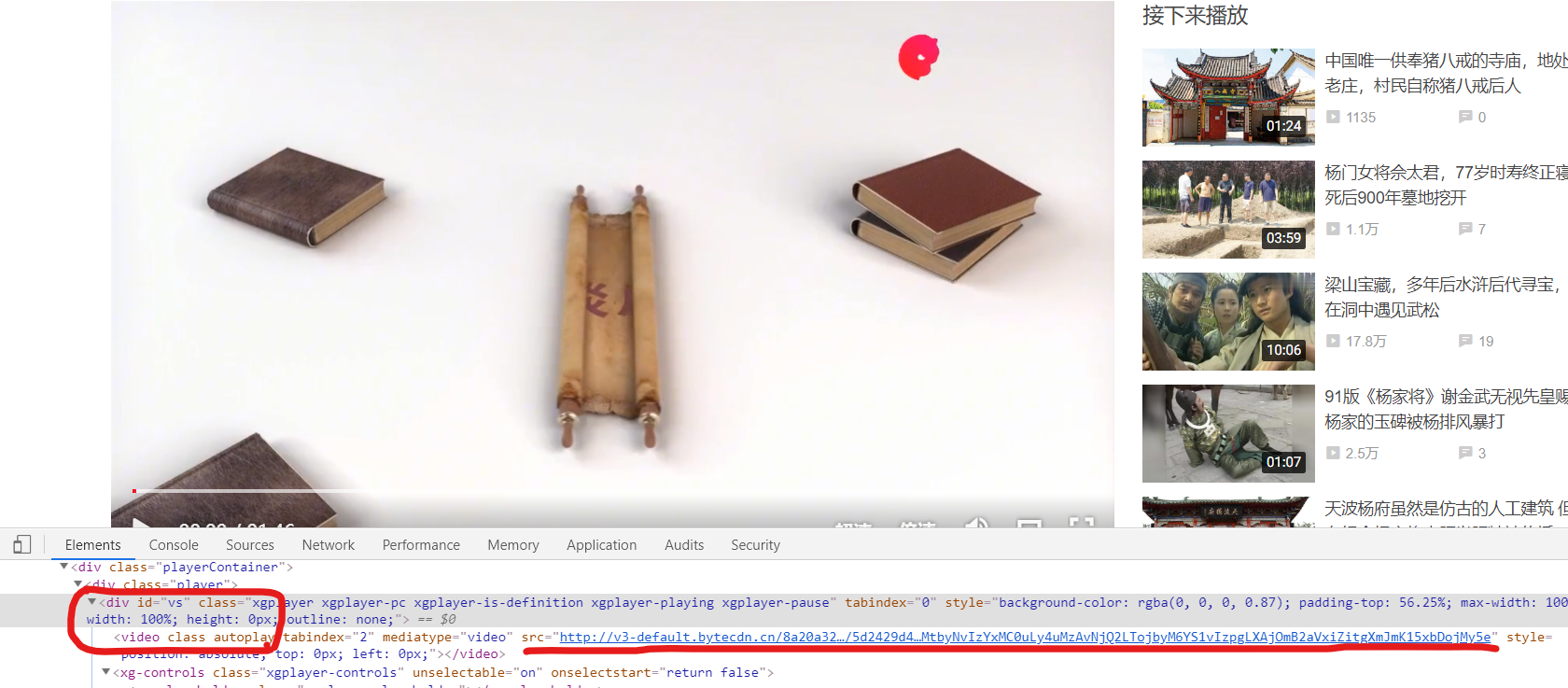
发现:视频地址在id为"vs"的div标签下面的video标签里面
三、爬取过程:
1.最初爬取代码:
#需求:爬取阳光宽频网的视频,下载到本地
from selenium import webdriver
import time
import requests
#阳光宽频网爬取类
class ygkp:
video_url_list = []
url_list = []
#1.驱动——返回驱动driver
def get_driver(self):
# 1.selenium配置
# 1.1 设置请求头
options = webdriver.ChromeOptions()
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
driver = webdriver.Chrome(options=options)
return driver
# #1.5 关闭底部banner页
# def close_bottom_banner(self,driver):
# #定位关闭按钮
# close_bt = driver.find_element_by_class_name("close-banner-icon")
# #点击关闭按钮
# close_bt.click()
#2.视频列表页——返回视频网页链接元素列表
def get_video_list_page(self,driver):
#2.进入网站
driver.get("https://365yg.com/")
time.sleep(5)
#3.获取视频详情页链接
video_div_url_list = driver.find_elements_by_class_name("title-box")
#print("video_div_url_list" + str(video_div_url_list))
for div in video_div_url_list:
#print("div" + str(div))
a = div.find_element_by_tag_name("a")
self.video_url_list.append(a)
#url = a.get_attribute("href")
#self.url_list.append(url)
#3.视频详情页——返回视频的URL
def get_video_url(self,driver,num):
time.sleep(5)
if num == 1:
driver.switch_to.window(driver.window_handles[num+1])
else:
driver.switch_to.window(driver.window_handles[-1])
driver.save_screenshot("01.png")
div = driver.find_element_by_id("vs")
#print("video_div" + str(div))
time.sleep(5)
video_src = div.find_element_by_tag_name("video").get_attribute("src")
#print("video_src" + str(video_src))
return video_src
#4.下载视频
def download_video(self,num,video_src):
response = requests.get(video_src).content
with open("shipin" + str(num+1) + ".mp4", "wb") as f:
f.write(response)
#5.运行
def run(self):
#1.获取驱动
driver = self.get_driver()
#2.获取视频详情页列表
self.get_video_list_page(driver=driver)
print(str(len(self.video_url_list)))
#3.关闭底部banner页
#self.close_bottom_banner(driver=driver)
#print("video_url_list"+str(self.video_url_list))
#4.点击每个视频链接
for i, video_web_url in enumerate(self.video_url_list):
driver.switch_to.window(driver.window_handles[0])
print("video_web_url" + str(i+1) +":" + str(video_web_url))
#print("url" + str(i+1) + ":" + str(self.url_list[i]))
time.sleep(10)
video_web_url.click()
#driver.execute_script("arguments[0].click();", video_web_url)
#5.获取每个视频的URL地址
video_src = self.get_video_url(driver=driver,num=i)
#6.下载url
self.download_video(num=i,video_src=video_src)
ygkp().run()
结果报错:
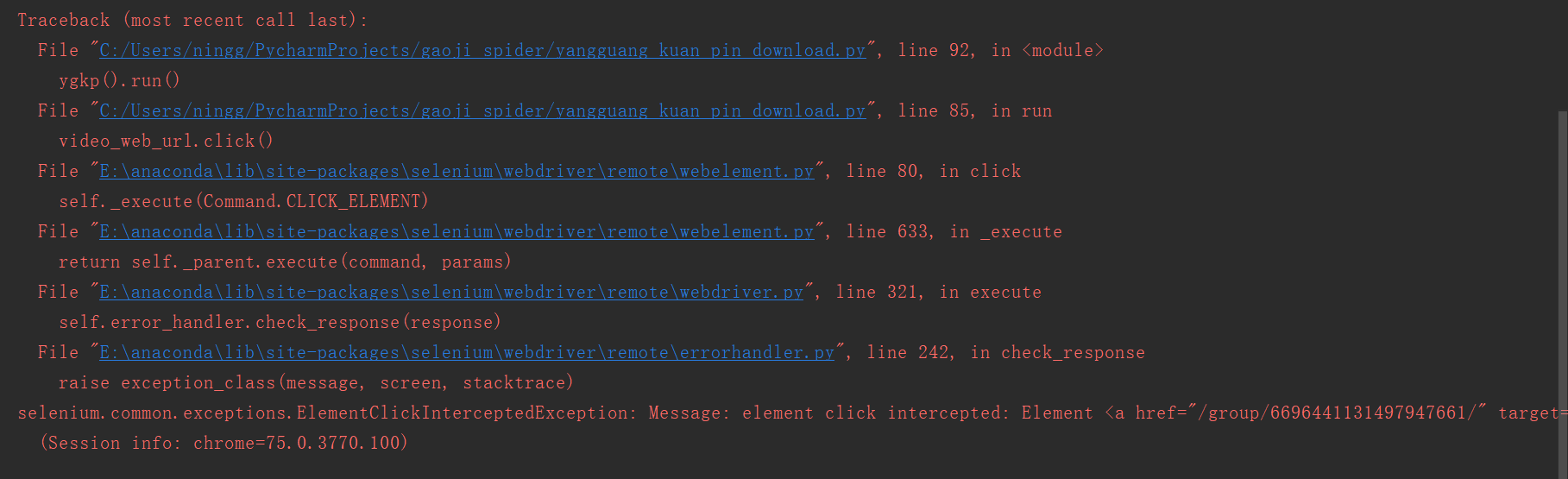
2.
在网上查询到,有两种解决办法:
#方法1:
element = driver.find_element_by_css('div[class*="loadingWhiteBox"]')
driver.execute_script("arguments[0].click();", element)
#方法2:
element = driver.find_element_by_css('div[class*="loadingWhiteBox"]')
webdriver.ActionChains(driver).move_to_element(element ).click(element ).perform()
我都试了一遍,结果,不会再报这个错误,但是后面会反复进入同一个详情页,反复下载同一个视频
再次查询ElementClickInterceptedException: Message: element click intercepted报错原因:发现原来是由于已经定位到的目标元素被其他元素遮挡,所以无法点击该元素。
查看网页:
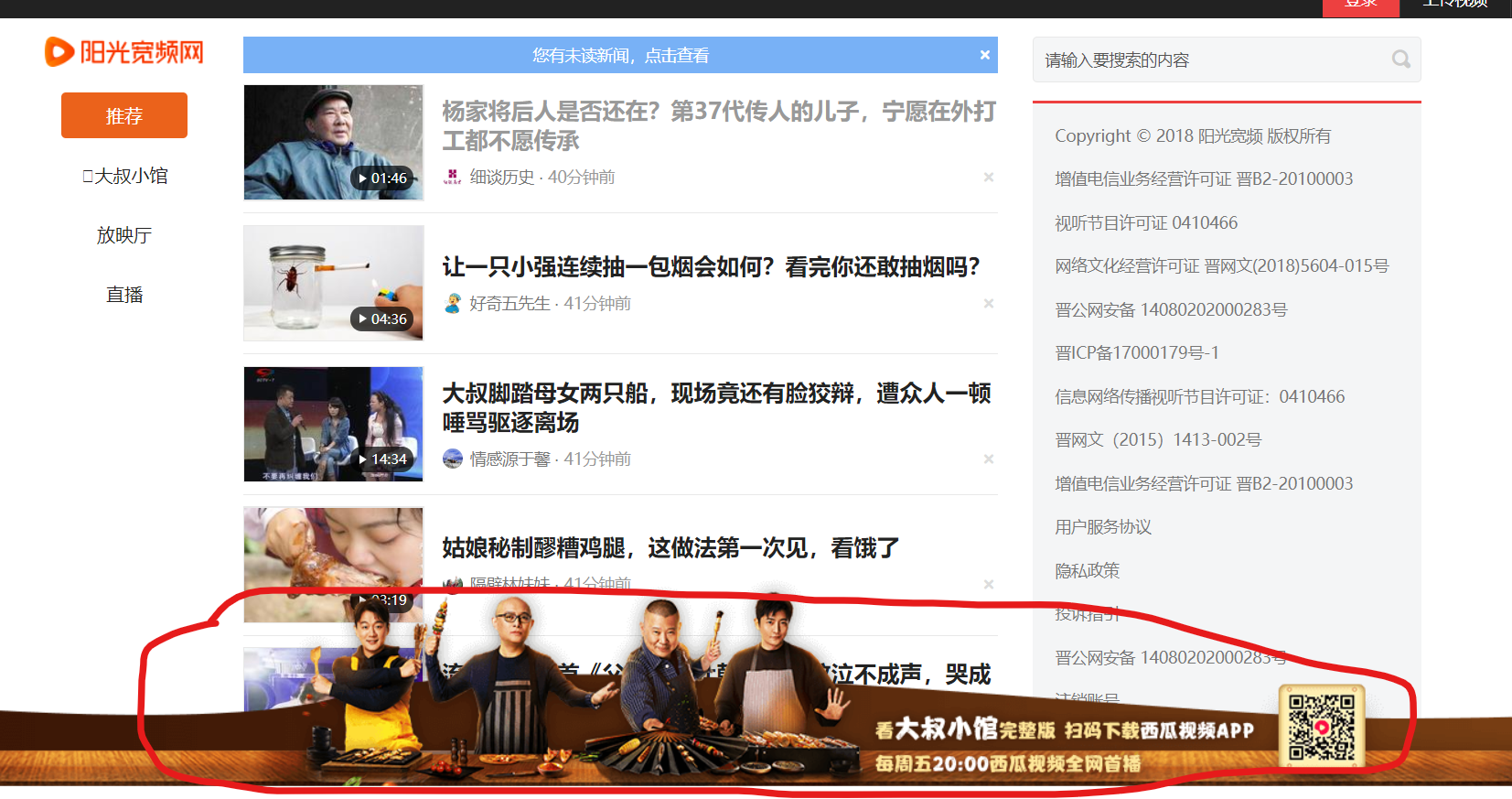
发现:视频列表页,底部有banner页,挡住了第五条视频。所以,无法点击。就像用户操作鼠标一样,当banner页覆盖了第五条视频时,用户无法用鼠标点击到该条视频。这应该就是所说的——页面元素存在遮挡
再次查看报错信息:

也是在点击第五条视频时,出现错误。
解决方法:第一次进入视频列表网页时,就先立即关闭banner页,然后再逐个点击视频。
检查网页:
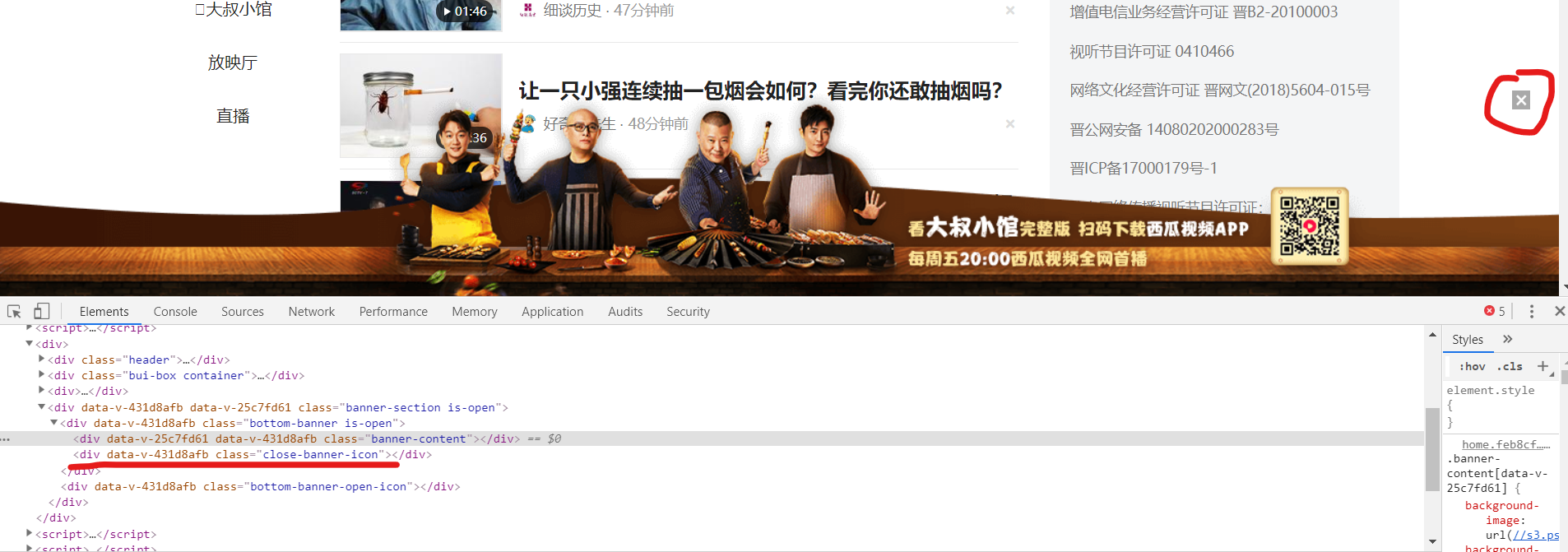
关闭banner的X按钮,class叫“close-banner-icon”
修改后代码:
#需求:爬取阳光宽频网的视频,下载到本地
from selenium import webdriver
import time
import requests
#阳光宽频网类
class ygkp:
video_url_list = []
url_list = []
#1.驱动——返回驱动driver
def get_driver(self):
# 1.selenium配置
# 1.1 设置请求头
options = webdriver.ChromeOptions()
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
driver = webdriver.Chrome(options=options)
return driver
#1.5 关闭底部banner页
def close_bottom_banner(self,driver):
#定位关闭按钮
close_bt = driver.find_element_by_class_name("close-banner-icon")
#点击关闭按钮
close_bt.click()
#2.视频列表页——返回视频网页链接元素列表
def get_video_list_page(self,driver):
#2.进入网站
driver.get("https://365yg.com/")
time.sleep(5)
#3.获取视频详情页链接
video_div_url_list = driver.find_elements_by_class_name("title-box")
#print("video_div_url_list" + str(video_div_url_list))
for div in video_div_url_list:
#print("div" + str(div))
a = div.find_element_by_tag_name("a")
self.video_url_list.append(a)
#url = a.get_attribute("href")
#self.url_list.append(url)
#3.视频详情页——返回视频的URL
def get_video_url(self,driver,num):
time.sleep(5)
if num == 1:
driver.switch_to.window(driver.window_handles[num+1])
else:
driver.switch_to.window(driver.window_handles[-1])
driver.save_screenshot("01.png")
div = driver.find_element_by_id("vs")
#print("video_div" + str(div))
time.sleep(5)
video_src = div.find_element_by_tag_name("video").get_attribute("src")
#print("video_src" + str(video_src))
return video_src
#4.下载视频
def download_video(self,num,video_src):
response = requests.get(video_src).content
with open("shipin" + str(num+1) + ".mp4", "wb") as f:
f.write(response)
#5.运行
def run(self):
#1.获取驱动
driver = self.get_driver()
#2.获取视频详情页列表
self.get_video_list_page(driver=driver)
print(str(len(self.video_url_list)))
#3.关闭底部banner页
self.close_bottom_banner(driver=driver)
#print("video_url_list"+str(self.video_url_list))
#4.点击每个视频链接
for i, video_web_url in enumerate(self.video_url_list):
driver.switch_to.window(driver.window_handles[0])
print("video_web_url" + str(i+1) +":" + str(video_web_url))
#print("url" + str(i+1) + ":" + str(self.url_list[i]))
time.sleep(10)
video_web_url.click()
#driver.execute_script("arguments[0].click();", video_web_url)
#5.获取每个视频的URL地址
video_src = self.get_video_url(driver=driver,num=i)
#6.下载url
self.download_video(num=i,video_src=video_src)
ygkp().run()
这样就能正常爬取了
四、补充:
查看视频列表长度,发现:每次只能获取7条视频。
这是因为,网站视频列表是动态加载的。每次滑动到底部会再加载新的7条视频。
如果我们要想爬取所有视频,该怎么办呢?
解决方法:先爬取最初的7条视频,然后每次爬取之前,都将网页滚动到浏览器底部,待加载出新的视频后,再次爬取。为了防止视频element有重复,可以使用set集合存放视频element。
#需求:爬取阳光宽频网的视频,下载到本地
from selenium import webdriver
import time
import requests
#阳光宽频网类
class ygkp:
video_url_list = set()
url_list = set()
#1.驱动——返回驱动driver
def get_driver(self):
# 1.selenium配置
# 1.1 设置请求头
options = webdriver.ChromeOptions()
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
driver = webdriver.Chrome(options=options)
return driver
#1.5 关闭底部banner页
def close_bottom_banner(self,driver):
#定位关闭按钮
close_bt = driver.find_element_by_class_name("close-banner-icon")
#点击关闭按钮
close_bt.click()
#2.视频列表页——返回视频网页链接元素列表
def get_video_list_page(self,driver):
# #2.进入网站
# driver.get("https://365yg.com/")
# time.sleep(5)
#3.获取视频详情页链接
video_div_url_list = driver.find_elements_by_class_name("title-box")
#print("video_div_url_list" + str(video_div_url_list))
for div in video_div_url_list:
#print("div" + str(div))
a = div.find_element_by_tag_name("a")
self.video_url_list.add(a)
url = a.get_attribute("href")
self.url_list.add(url)
#3.视频详情页——返回视频的URL
def get_video_url(self,driver,num):
time.sleep(5)
if num == 1:
driver.switch_to.window(driver.window_handles[num+1])
else:
driver.switch_to.window(driver.window_handles[-1])
driver.save_screenshot("01.png")
div = driver.find_element_by_id("vs")
#print("video_div" + str(div))
time.sleep(5)
video_src = div.find_element_by_tag_name("video").get_attribute("src")
#print("video_src" + str(video_src))
return video_src
#4.下载视频
def download_video(self,num,video_src):
response = requests.get(video_src).content
with open("shipin" + str(num+1) + ".mp4", "wb") as f:
f.write(response)
#5.运行
def run(self):
#1.获取驱动
driver = self.get_driver()
# 2.进入网站
driver.get("https://365yg.com/")
time.sleep(5)
# 3.关闭底部banner页
self.close_bottom_banner(driver=driver)
#2.获取视频详情页列表
for i in range(5):
self.get_video_list_page(driver=driver)
print(str(len(self.video_url_list)))
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(5)
#print("video_url_list"+str(self.video_url_list))
#4.点击每个视频链接
# for i, video_web_url in enumerate(self.video_url_list):
# driver.switch_to.window(driver.window_handles[0])
# print("video_web_url" + str(i+1) +":" + str(video_web_url))
# print("url" + str(i+1) + ":" + str(self.url_list[i]))
# time.sleep(10)
# video_web_url.click()
# #driver.execute_script("arguments[0].click();", video_web_url)
# #5.获取每个视频的URL地址
# video_src = self.get_video_url(driver=driver,num=i)
# #6.下载url
# self.download_video(num=i,video_src=video_src)
ygkp().run()
运行结果:
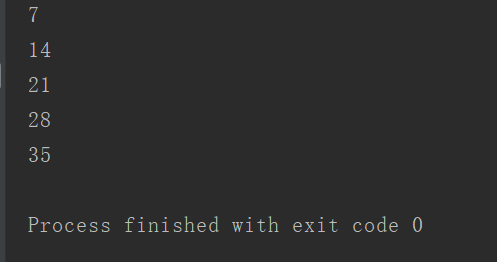
可以看到:视频列表的长度增加了。
如果想爬取所有视频,可以将for循环改成while循环。
五:总结:
我学到了:
1.元素element定位有多种方式:
https://i.cnblogs.com/EditPosts.aspx?postid=11127907
2. 获取element的属性值:get_attribute("属性名")
3.下载视频、图片:
https://i.cnblogs.com/EditPosts.aspx?postid=11127907
4.报错:element click intercepted的原因
是由于网页上,存在页面元素相互遮挡,无法点击到目标元素
解决方法:
#方法1:
element = driver.find_element_by_css('div[class*="loadingWhiteBox"]')
driver.execute_script("arguments[0].click();", element)
#方法2:
element = driver.find_element_by_css('div[class*="loadingWhiteBox"]')
webdriver.ActionChains(driver).move_to_element(element ).click(element ).perform()
方法3:
关闭掉,遮挡元素;总之,想法设法将被遮挡的点击目标元素,露出来。
5.selenium滑动浏览器:
#移动到元素element对象的“顶端”与当前窗口的“顶部”对齐
driver.execute_script("arguments[0].scrollIntoView();", element);
driver.execute_script("arguments[0].scrollIntoView(true);", element);
#移动到元素element对象的“底端”与当前窗口的“底部”对齐
driver.execute_script("arguments[0].scrollIntoView(false);", element);
#移动到页面最底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)");
#移动到指定的坐标(相对当前的坐标移动)
driver.execute_script("window.scrollBy(0, 700)");
#结合上面的scrollBy语句,相当于移动到700+800=1600像素位置
driver.execute_script("window.scrollBy(0, 800)");
#移动到窗口绝对位置坐标,如下移动到纵坐标1600像素位置
driver.execute_script("window.scrollTo(0, 1600)");
#结合上面的scrollTo语句,仍然移动到纵坐标1200像素位置
driver.execute_script("window.scrollTo(0, 1200)");
6.python中set集合的用法:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号