部署hadoop的开发环境
第一步:安装jdk
由于hadoop是java开发的,所以需要JDK来运行代码。这里安装的是jdk1.6.
jdk的安装见http://www.cnblogs.com/tommyli/archive/2012/01/06/2314706.html
第二步:创建独立的用户
useradd hadoop passwd hadoop
有些机器不能设置空密码的时候
passwd -d hadoop
这里的用户名为hadoop,如果你要调试的时候要注意名字。
比如我用windows调试linux的集群,这个名字应该是windows系统的用户名(否则你没有权限提交作业到hadoop)。
第三步:设置用户无密码登陆
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys exit
第四步:下载hadoop
mkdir /opt/hadoop cd /opt/hadoop/ wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.0/hadoop-1.2.0.tar.gz tar -xzf hadoop-1.2.0.tar.gz mv hadoop-1.2.0 hadoop chown -R hadoop /opt/hadoop cd /opt/hadoop/hadoop/
第五步:配置hadoop
vi conf/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://10.53.132.52:54310</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
vi conf/hdfs-site.xml
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description> </property>
vi conf/mapred-site.xml
<property> <name>mapred.job.tracker</name> <value>10.53.132.52:54311</value> <description>The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task. </description> </property>
第六步:开启hadoop
bin/hadoop namenode -format
bin/start-all.sh
关闭是
bin/stop-all.sh
验证开启是
jps
26049 SecondaryNameNode 25929 DataNode 26399 Jps 26129 JobTracker 26249 TaskTracker 25807 NameNode
第七步:下载并设置eclipse的hadoop插件。
插件文件是:hadoop-eclipse-plugin-1.2.0.jar
放到eclipse的plugins目录下即可。
第八步:打开eclipse创建map/reduce项目。
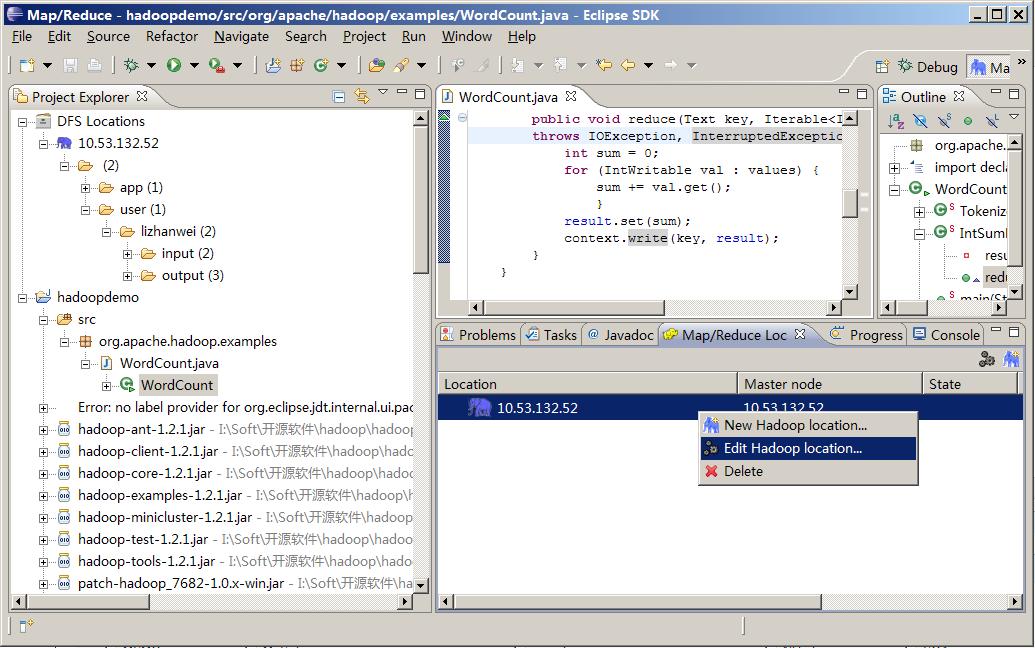
修改map/reduce和hdfs的地址和端口
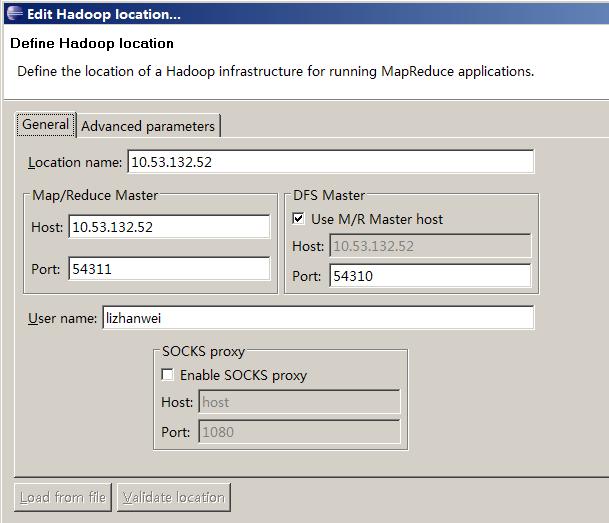
第九步:调试hadoop
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "10.53.132.52:54311");
//conf.addResource(new Path("\\soft\\hadoop\\conf\\core-site.xml"));
//conf.addResource(new Path("\\soft\\hadoop\\conf\\hdfs-site.xml"));
String[] ars=new String[]{"input","output"};
String[] otherArgs = new GenericOptionsParser(conf, ars).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
(这里是吧作业提交到远端的hadoop)
调试
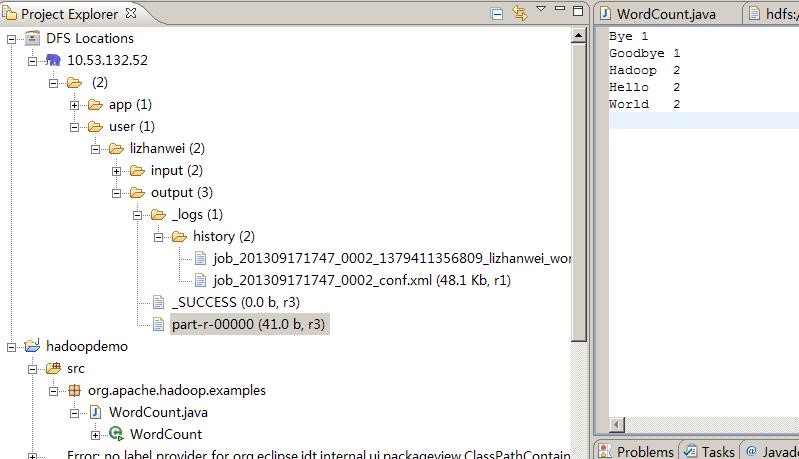
结果
13/09/17 17:50:32 INFO input.FileInputFormat: Total input paths to process : 2 13/09/17 17:50:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 13/09/17 17:50:33 WARN snappy.LoadSnappy: Snappy native library not loaded 13/09/17 17:50:33 INFO mapred.JobClient: Running job: job_201309171747_0002 13/09/17 17:50:34 INFO mapred.JobClient: map 0% reduce 0% 13/09/17 17:50:39 INFO mapred.JobClient: map 100% reduce 0% 13/09/17 17:50:47 INFO mapred.JobClient: map 100% reduce 33% 13/09/17 17:50:48 INFO mapred.JobClient: map 100% reduce 100% 13/09/17 17:50:49 INFO mapred.JobClient: Job complete: job_201309171747_0002 13/09/17 17:50:49 INFO mapred.JobClient: Counters: 29 13/09/17 17:50:49 INFO mapred.JobClient: Job Counters 13/09/17 17:50:49 INFO mapred.JobClient: Launched reduce tasks=1 13/09/17 17:50:49 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=6115 13/09/17 17:50:49 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 13/09/17 17:50:49 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 13/09/17 17:50:49 INFO mapred.JobClient: Launched map tasks=2 13/09/17 17:50:49 INFO mapred.JobClient: Data-local map tasks=2 13/09/17 17:50:49 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=8702 13/09/17 17:50:49 INFO mapred.JobClient: File Output Format Counters 13/09/17 17:50:49 INFO mapred.JobClient: Bytes Written=41 13/09/17 17:50:49 INFO mapred.JobClient: FileSystemCounters 13/09/17 17:50:49 INFO mapred.JobClient: FILE_BYTES_READ=79 13/09/17 17:50:49 INFO mapred.JobClient: HDFS_BYTES_READ=286 13/09/17 17:50:49 INFO mapred.JobClient: FILE_BYTES_WRITTEN=174015 13/09/17 17:50:49 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=41 13/09/17 17:50:49 INFO mapred.JobClient: File Input Format Counters 13/09/17 17:50:49 INFO mapred.JobClient: Bytes Read=50 13/09/17 17:50:49 INFO mapred.JobClient: Map-Reduce Framework 13/09/17 17:50:49 INFO mapred.JobClient: Map output materialized bytes=85 13/09/17 17:50:49 INFO mapred.JobClient: Map input records=2 13/09/17 17:50:49 INFO mapred.JobClient: Reduce shuffle bytes=85 13/09/17 17:50:49 INFO mapred.JobClient: Spilled Records=12 13/09/17 17:50:49 INFO mapred.JobClient: Map output bytes=82 13/09/17 17:50:49 INFO mapred.JobClient: Total committed heap usage (bytes)=602996736 13/09/17 17:50:49 INFO mapred.JobClient: CPU time spent (ms)=2020 13/09/17 17:50:49 INFO mapred.JobClient: Combine input records=8 13/09/17 17:50:49 INFO mapred.JobClient: SPLIT_RAW_BYTES=236 13/09/17 17:50:49 INFO mapred.JobClient: Reduce input records=6 13/09/17 17:50:49 INFO mapred.JobClient: Reduce input groups=5 13/09/17 17:50:49 INFO mapred.JobClient: Combine output records=6 13/09/17 17:50:49 INFO mapred.JobClient: Physical memory (bytes) snapshot=555175936 13/09/17 17:50:49 INFO mapred.JobClient: Reduce output records=5 13/09/17 17:50:49 INFO mapred.JobClient: Virtual memory (bytes) snapshot=1926799360 13/09/17 17:50:49 INFO mapred.JobClient: Map output records=8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号