
架构设计之分布式数据访问
1:前言
看到这个题目也许有的朋友会问对数据访问层扩展为分布式有没有意义,因为不管怎样到最后都是对数据库进行访问,瓶颈在数据库上。对于这个问题我的答案是“我们提供分布式的查询能力然后和缓存结合让数据库中的数据缓存起来”。解决这个问题后我们来进入正题,如何对数据访问层进行封装。其实数据访问层的方法我们常用的是ExecuteDataset,ExecuteNonQuery,ExecuteReader,ExecuteScalar等这四个方法。
2:类图
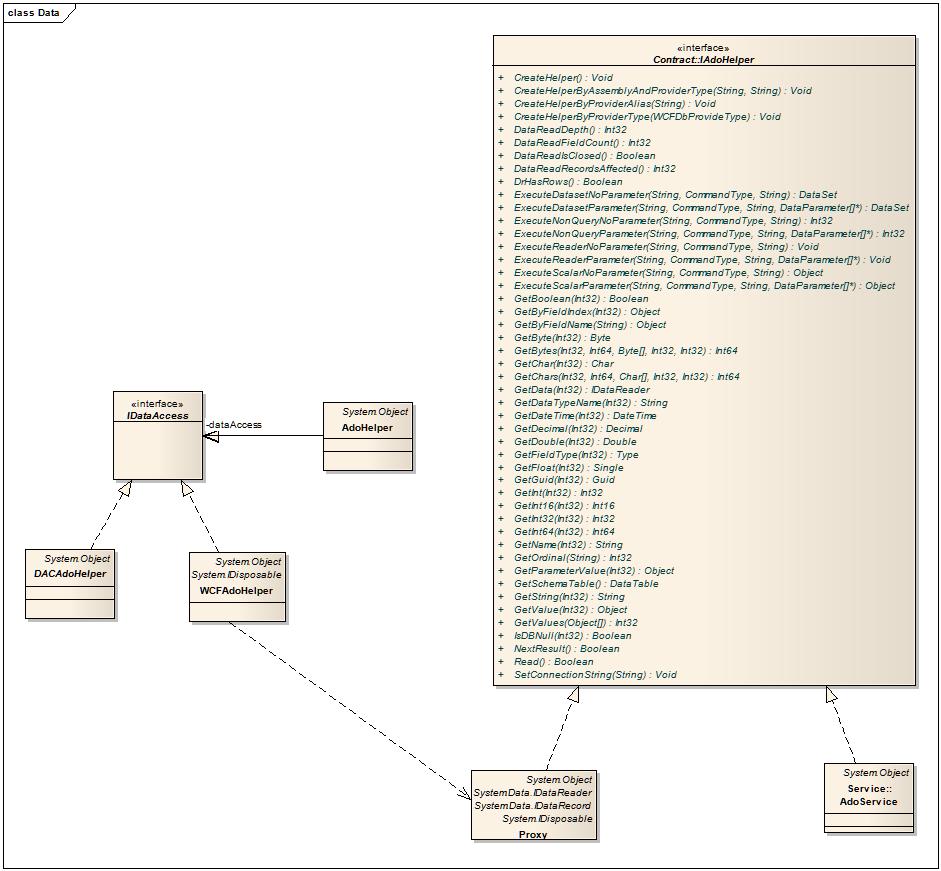
3:原理
WCF中可以返回序列化的对象而DataRead是不能被序列化的(网上有人说可以让一个序列化的对象持有DataRead属性,这个方法根本不行)
这里我们就说说如何通过WCF来返回DataReader。
看过底层代码(System.Data.SqlClient)的都知道,微软在实现ExecuteReader这个方法的时候是用了一个类似于游标的东西。每Read一次游标就向下走一行。
这里我们可以借鉴这个思想。我们首先把所有IDataReader中的方法定义到契约中。然后让客户端实现该契约,这样客户端每Read一次服务端也同样Read一次。这样我们就可以获取到该行相应的字段值了。不过这种方法要求WCF的实例模型是PerSession而并发模型是Multiple。
4:一些问题
WCF在开启信道的时候如果通过这种方法
new ChannelFactory<IAdoHelper>(EndpointconfigKey).CreateChannel();
在压力测试的时候会报错。只有通过以下方法
new ChannelFactory<IAdoHelper>(bind, address).CreateChannel();
还有就是WCF中的信道池不知道怎么开启。MaxConnection好像不起作用,因此自己就实现了对象池来解决信道池的问题。【哪位仁兄知道不吝赐教】


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述