dirseach的安装和使用
dirseach的安装和使用
1.dirsearch的功能
dirsearch是一个基于python的命令行工具,旨在暴力扫描页面结构,包括网页中的目录和文件
2.安装
-
去GitHub获取安装包
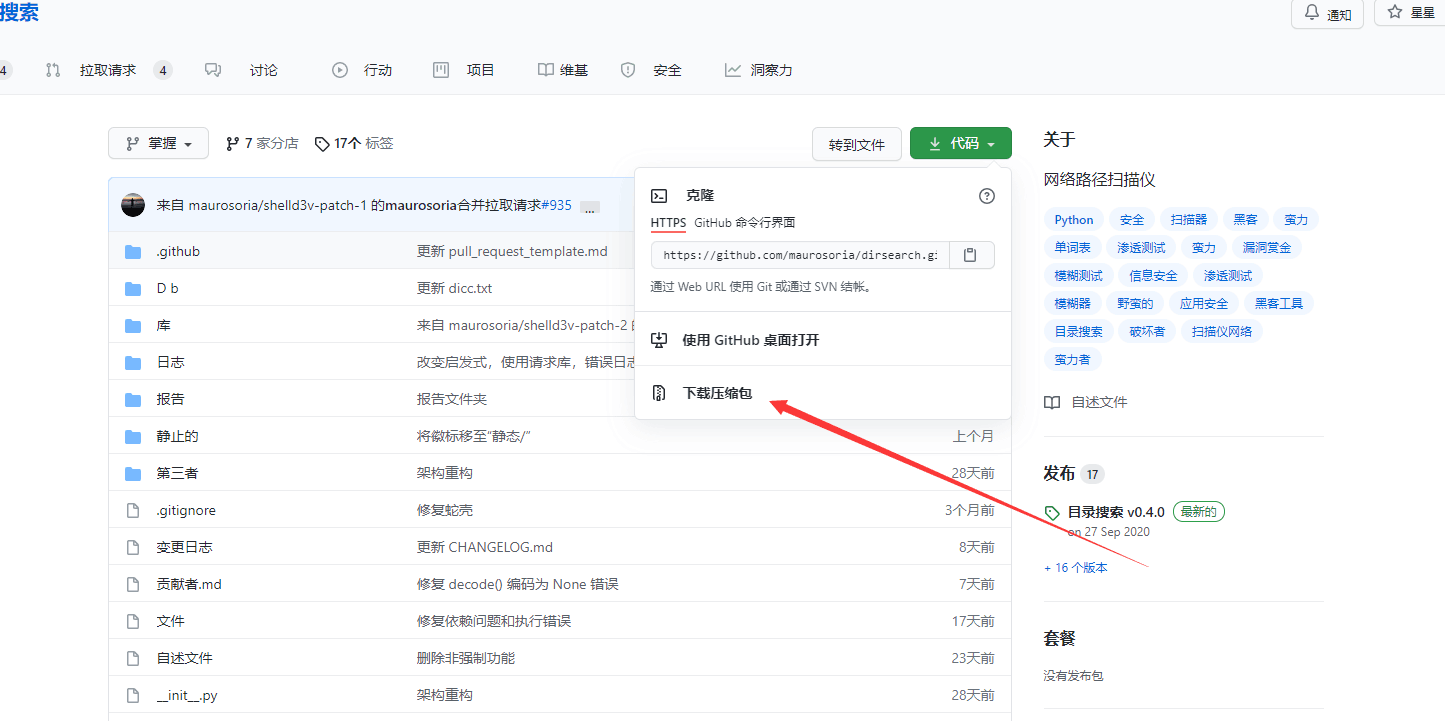
-
在CMD中安装库(一定要在该目录下打开cmd)
pip3 install -r requirements.txt

如果报红建议删掉重新来过
-
使用一个被授权的可以搜索的网站进行扫描测试
python dirsearch.py -u http://111.200.241.244:56409/ -e jsp,php该网站(http://111.200.241.244:56409/)为CTF攻防世界临时获取的场景网站。
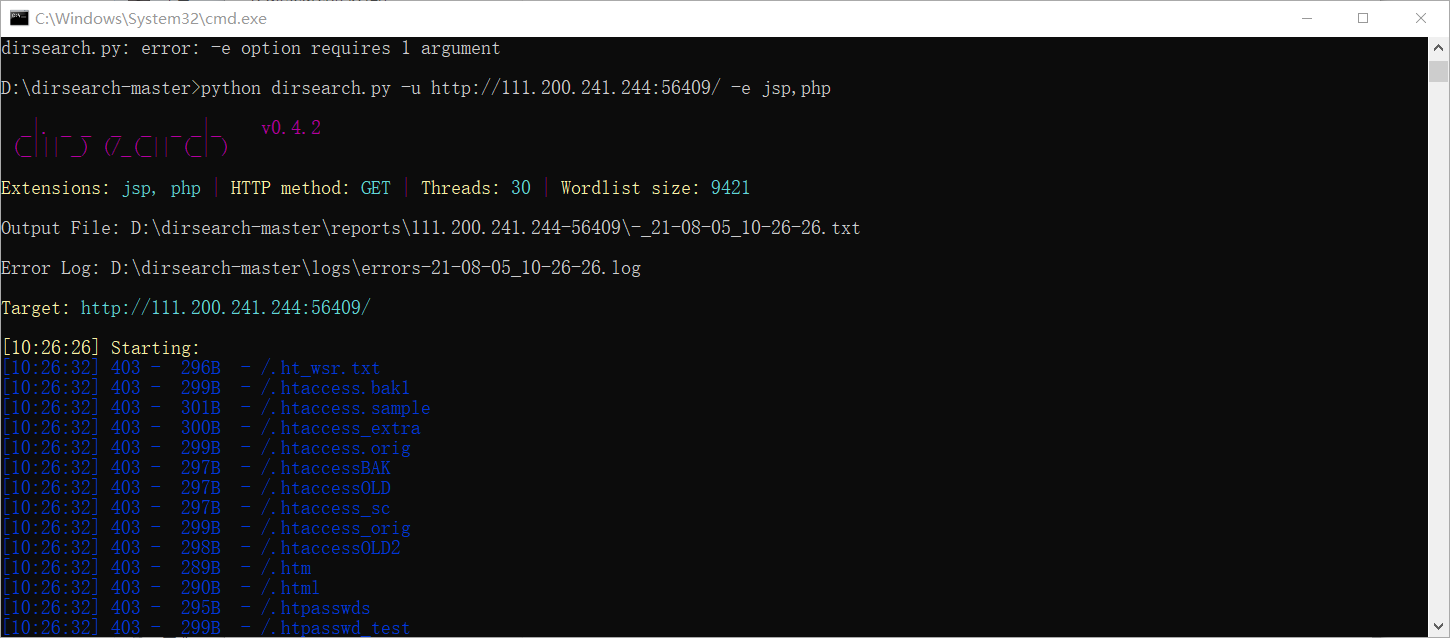
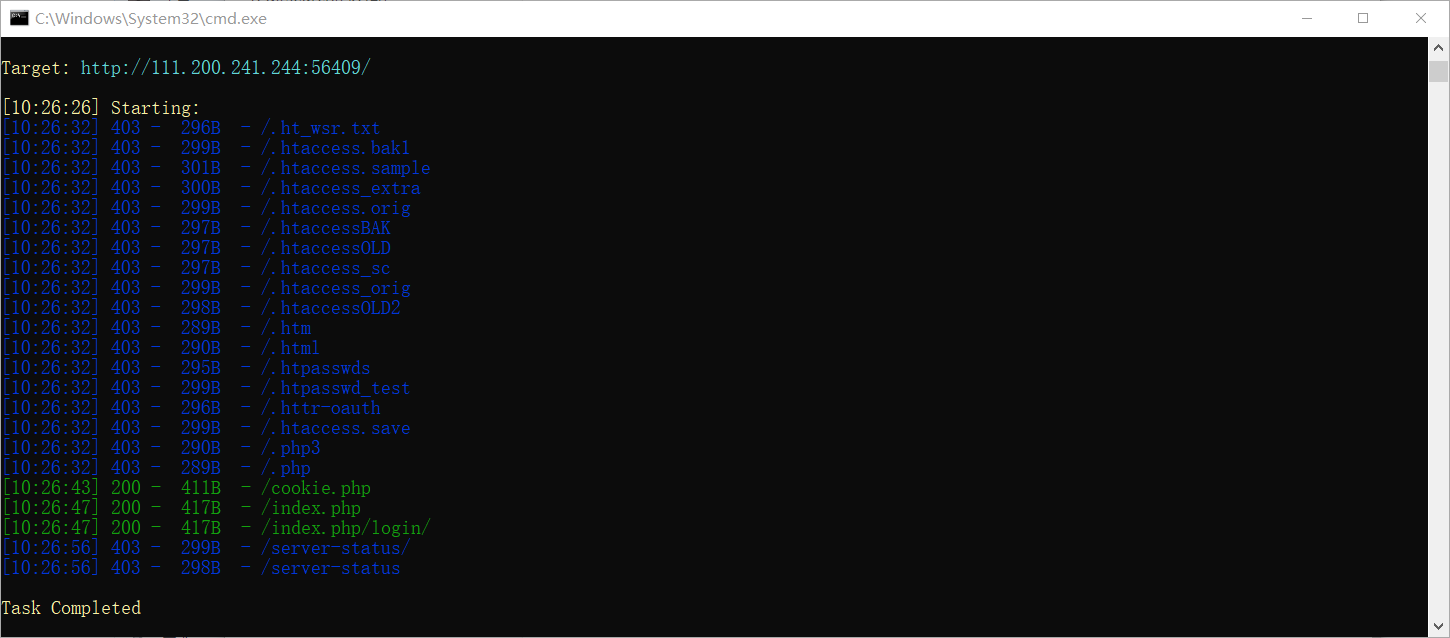
成功扫描出其中的cookie.php文件
3.使用
基本用法
dirsearch.py [-u|--url] target(目标网站) [-e|--extensions] extensions [options]
简化后
dirsearch.py -u www.****.com -e jsp,php,bak(***)
高级用法(转自别人的整理,博主太笨也看不懂 吼吼吼~)
每一列的含义分别是:扫描时间,状态码,大小,扫描的目录,重定向的地址参数列表: -h, --help 查看帮助 -u URL, --url=URL 设置url -L URLLIST, --url-list=URLLIST 设置url列表 -e EXTENSIONS, --extensions=EXTENSIONS 网站脚本类型 -w WORDLIST, --wordlist=WORDLIST 设置字典 -l, --lowercase 小写 -f, --force-extensions 强制扩展字典里的每个词条 -s DELAY, --delay=DELAY 设置请求之间的延时 -r, --recursive Bruteforce recursively 递归地扫描 –scan-subdir=SCANSUBDIRS, --scan-subdirs=SCANSUBDIRS 扫描给定的url的子目录(用逗号隔开) –exclude-subdir=EXCLUDESUBDIRS, --exclude-subdirs=EXCLUDESUBDIRS 在递归过程中排除指定的子目录扫描(用逗号隔开) -t THREADSCOUNT, --threads=THREADSCOUNT 设置扫描线程 -x EXCLUDESTATUSCODES, --exclude-status=EXCLUDESTATUSCODES 排除指定的网站状态码(用逗号隔开) -c COOKIE, --cookie=COOKIE 设置cookie –ua=USERAGENT, --user-agent=USERAGENT 设置用户代理 -F, --follow-redirects 跟随地址重定向扫描 -H HEADERS, --header=HEADERS 设置请求头 –random-agents, --random-user-agents 设置随机代理 –timeout=TIMEOUT 设置超时时间 –ip=IP 设置代理IP地址 –proxy=HTTPPROXY, --http-proxy=HTTPPROXY 设置http代理。例如127.0.0.1:8080 –max-retries=MAXRETRIES 设置最大的重试次数 -b, --request-by-hostname 通过主机名请求速度,默认通过IP –simple-report=SIMPLEOUTPUTFILE 保存结果,发现的路径 –plain-text-report=PLAINTEXTOUTPUTFILE 保存结果,发现的路径和状态码 –json-report=JSONOUTPUTFILE 以json格式保存结果 ———————————————— 版权声明:本文为CSDN博主「rose never fade」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq1045553189/article/details/86221203
posted on 2021-08-05 11:24 Tom_liuのblog 阅读(1519) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号