

python代码热更新原理
python代码热更新原理
热更新概念
在进程不重启的前提下,修改代码并且使得修改的代码生效
热更新背景需求
紧急修复线上问题
实现不停机维护
要实现上面的用户需求,需要在原理上支持下面需求*
1.支持任意的import语法并且无顺序依赖要求
2.对应回调函数、已实例化对象等也要支持代码热更
3.已实例化对象的属性能够动态新增
python内置reload函数
接触过python应该都知道,python有内置的reload()函数来重新加载之前载入的模块。那内置的reload为什么不满足热更新的需求呢?
内置reload的局限
1.内置reload不能支持回调函数、已实例化对象代码热更新
原因是内置reload不能保证,module内函数地址不变
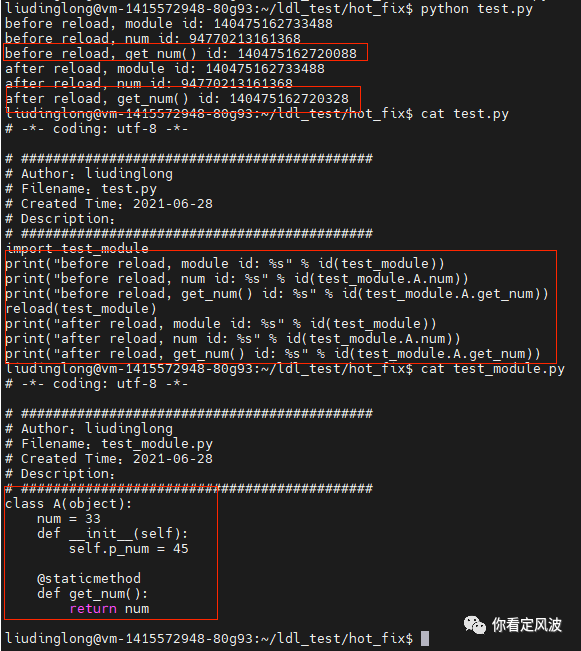
从上图可以看出内置的reload加载模块前后,模块内存地址和模块内的类变量地址可以保持不变,但是模块内的类函数地址会发生变化,这样不能满足热更新的需求,没有重启的实例的函数调用可能会发生内存访问错误。
2.内置的reload函数有import顺序依赖要求
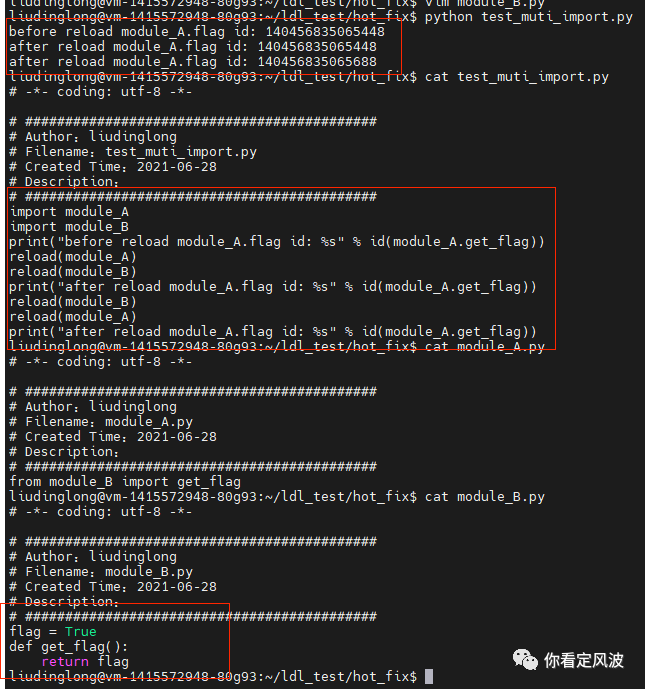
上图演示了test_multi_import.py 里面import module_A, module_A里面import module_B里面的get_flag函数 在test_multi_import.py 里面进行reload,如果先reload module_A,再reload module_B那get_flag的内存地址没有发生变化,说明函数没reload成功,因为reload module_A时,get_flag函数是从外部导入的,reload module_A不会造成module_A里的get_flag函数重新加载,reload module_B时只会重新加载module_B 里面的get_flag函数,导致module_A和test_multi_import.py里面的get_flag函数没有更新, 只有严格按照import顺序重新加载才能保证,函数更新到每一个module。
3. 内置reload函数局限的原因
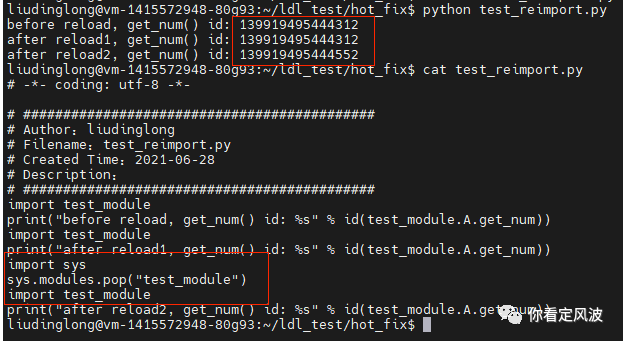
从上图可以看出先把sys.modules里面的modules pop掉再import一遍和reload效果是一样的,如果只import 会优先用sys.modules里面缓存的module对象,不会发生重新加载。
reload的本质就是把系统缓存的模块对象删除,再重新import一遍,因此要解决reload问题的局限,就要了解import过程,并自己接管import流程。
import原理
import形式
1.import module_A 导入module_A,可以通过module_A.***访问module_A的所有成员
2.from module_A import object_B 导入module_A里面的object_B成员,只能并且可以直接访问object_B成员
3. from module_A import object_B as B 导入module_A里面的object_B成员,并且重命名为B,可以用B来访问object_B成员
4.from module_A import *
导入module_A里面的所有成员,可以直接访问module_A内部所有成员,不用通过module_A.***来访问
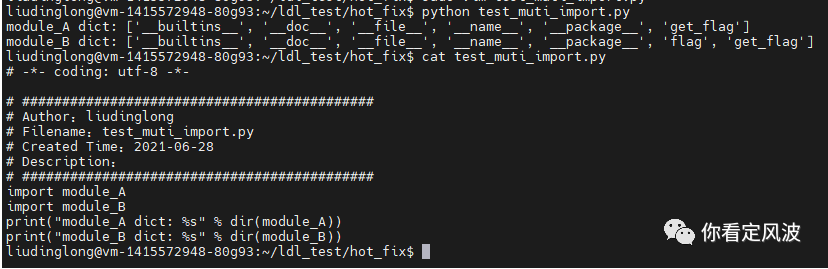
import对应字节码:

从上面字节码可以看出四种形式的import 都要调用IMPORT_NAME加载一个模块,区别在于本地命名空间绑定的变量不一样,也就是访问接口不一样。通过dir(module)可以看module有哪些属性,module.dict 可以查看一个模块绑定的所有属性及他们的值。如下图:
import实现
import首先要确定import的module的定义位于哪个python文件
static PyObject *builtin___import__(PyObject *self, PyObject *args, PyObject *kwds)
{ // [1].初始化参数列表
static char *kwlist[] = {"name", "globals", "locals", "fromlist", "level", 0};
// [2].查找当前import语句所发生的package
parent = get_parent(globals, buf, &buflen, level);
// [3].按照顺序搜索加载第一个module,如packageA
head = load_next(parent, level < 0 ? Py_None : parent, &name, buf, &buflen);
tail = head
// [4].递归调用按顺序逐个加载module
while (name) {
next = load_next(tail, tail, &name, buf, &buflen);
tail = next;
}
return tail;
}
大致的代码逻辑如上:get_parent函数的作用是获取import语句所在源文件的所在的包。load_next 是按照 import后面所带名字,一层一层地查找模块,直到所跟名字为空代表找到了。
以一个例子来讲解import确定module所在源文件的过程:
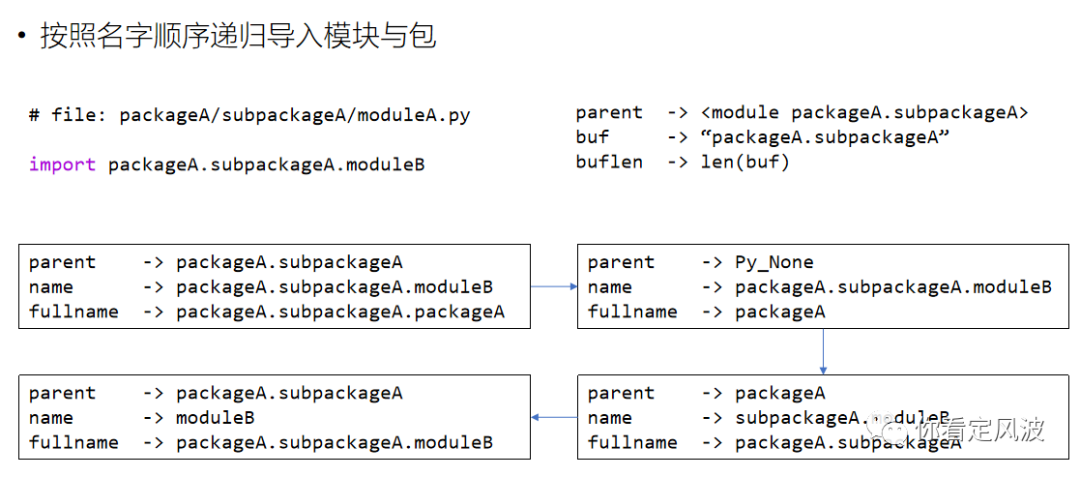
如上图在packageA/subpackageA/moduleA.py里面去import packageA.subpackageA.moduleB
-
首先找到import语句所在源文件moduleA.py所在的包是packageA.subpackageA, name参数是packageA.subpackageA.packageA
-
从name里面取出第一层packageA,拼到parent上,形成fullname全路径,值为packageA.subpackageA.packageA,查找这个全路径,并不存在,可以判断import不是相对于当前包路径来查找
-
full_name去掉parent前缀,即full_name=packageA,将parent置为None,name参数还是packageA.subpackageA.moduleB,此时再查找full_name可以从系统路径中找到packageA,并加载它。
-
加载成功就将当前环境所在包即parent值置为packageA,因为已经找到第一层packageA,name可以去掉一层了,变成subpackageA.packageA,fullname再取下一层,subpackageA,拼到parent,形成packageA.subpackageA,再在当前模块环境下查找full_name可以找到packageA.subpackageA ,找到后就加载packageA.subpackageA为当前模块。
-
加载packageA.subpackageA为当前模块后将parent值置为packageA.subpackageA。又找到了name的一层subpackageA,将name再去掉一层,变成moduleB,fullname再取name下一层moduleB,在当前模块查找full_name,可以查找到并加载它。
-
加载完packageA.subpackageA.moduleB后,parent置为packageA.subpackageA.moduleB,name因为已经找到了moduleB,再去掉一层变为""(空)了,full_name没法取下一层查找,这时判断name为空,可以退出循环了,已经import成功了。
根据上面逻辑可以总结出:
parent参数值代表当前已加载模块(import运行环境)所在包,full_name代表当前所要查找的包的全路径,name代表当前还需要找的(尚未遍历查找部分)包的相对路径。
当加载成功退出循环时,parent和full_name的值都是模块全路径,而name是空。
当加载失败退出循环时,name非空,而parent为空,并且在系统路径下也找不到full_name,这时可以判定模块不存在了
import的查找与加载
上一节讲了python import定位module所在源文件的过程,其中有两个重要的细节值得展开来讲,怎么根据full_name(模块全路径)来找到一个模块并加载这个模块?python查找和加载模块的底层实现包含在find_module和load_module这两个函数里面。
find_module
static struct filedescr *find_module(char *fullname, char *subname, FILE **p_fp ...)
{ // [1].获取搜索路径sys.path,按照列表顺序遍历查找
path = PySys_GetObject("path");
for (i = 0; i < npath; i++) {
// [2].拼接完整的路径名字,如 C://Workspace//script//packageA//
PyObject *v = PyList_GetItem(path, i);
strcpy(buf, PyString_AS_STRING(v));
strcpy(buf+len, subname);
// [3].如果路径是目录则检查是否存在__init__.py并返回
if (isdir(buf) && (find_init_module(buf))
return &{"", "", PKG_DIRECTORY};
// [4].普通文件则拼接后缀名并返回文件的句柄,后缀如 .py .pyc等
for (fdp = _PyImport_Filetab; fdp->suffix != NULL; fdp++) {
strcpy(buf+len, fdp->suffix);
*p_fp = fopen(buf, fdp->mode);
return &{".py", "U", PY_SOURCE};;
}
从上面代码大概可以总结出,查找模块的逻辑为将sys.path里面的每一个系统查找路径与full_name拼接,检查这个文件或目录是否存在,如果存在则返回文件句柄;否则什么也不做,进入下一次循环(即拼接下一条系统路径,进行文件查找),当所有系统路径和full_name拼接完都找不到这个文件,就可以判定full_name模块不存在了。
load_module
static PyObject *load_module(char *name, FILE *fp, char *pathname, int type, PyObject *loader)
{
switch (type) {
// [1].源文件类型的模块,直接加载源码进行编译创建module
case PY_SOURCE:
m = load_source_module(name, pathname, fp);
break;
// [2].目录类型,按照package的方式加载
case PKG_DIRECTORY:
m = load_package(name, pathname);
break;
}
return m;
}
load_module的逻辑主要是根据文件的不同类型来执行不同的调用,包括目录,源码文件,pyc字节码文件等,加载源码文件需要先进行一次编译,再将字节码文件加载成module对象;字节码文件可以直接转换成一个对象;目录文件可能要执行目录下的__init__.py来进行初始化,然后形成一个目录package对象。
import查找器
前面已经从C源码层面了解到了import流程查找源码文件和加载模块的流程,但是我们怎么能够自己接管import流程呢?python为我们提供了查找器这样一个接口来让我们实现自定义的查找和加载流程。
查找器(Finder)
查找器的概念可以概括为以下几点:
脚本层查找模块的钩子类
实现特定接口的python类(包含find_module接口)
返回结果为一个加载器对象
存放于sys.meta_path中
下面从源码层面讲一下查找器怎么在查找模块过程中起作用:
static struct filedescr *
find_module(char *fullname, char *subname, PyObject *path, char *buf,
size_t buflen, FILE **p_fp, PyObject **p_loader) {
// [1].参数传了p_loader指针,则检查sys.meta_path中是否存在Finder实例
if (p_loader != NULL) {
PyObject *meta_path = PySys_GetObject("meta_path");
for (i = 0; i < npath; i++) {
// [2].调用Finder的类方法find_module查找module及返回module的加载器
PyObject *hook = PyList_GetItem(meta_path, i);
PyObject *loader = PyObject_CallMethod(hook, "find_module",
"sO", fullname,path != NULL ?path : Py_None);
if (loader != Py_None) {
*p_loader = loader;
return &{"", "", IMP_HOOK};
}
// [3].顺序遍历path路径查找模块文件,并且拼接完整路径名
path = PySys_GetObject("path");
for (i = 0; i < npath; i++) {
strcpy(buf, PyString_AS_STRING(v));
...
}
之前我们已经看过find_module的源码,但其实前面省略了一些东西,就是系统查找最新会检查p_loader指针是否为空,为空才走系统的find_module逻辑,否则会走自定义的查找器逻辑。
p_loader非空,则从sys.meta_path里面找到所有的查找器(Finder类),遍历每一个查找器,调用查找器的类方法find_module来查找module并且返回module的加载器。如果自定义查找器没有找到module才会继续往前面讲的系统find_module走。
加载器(Loader)
加载器的概念可以概括为以下几点:
实现特定接口的python类(包含load_module接口)
负责实现具体模块的加载
返回值构建完成的模块对象
作为查找器的返回值
下面同样从源码层面看一下Loader的实现:
static PyObject *load_module(char *name, FILE *fp, char *pathname, int type, PyObject *loader)
{
switch (type) {
// [1].源文件类型的模块,直接加载源码进行编译创建module
case PY_SOURCE:
m = load_source_module(name, pathname, fp);
break;
// [2].目录类型,按照package的方式加载
case PKG_DIRECTORY:
m = load_package(name, pathname);
break;
// [3].钩子类型,直接调用加载器的成员方法来加载模块
case IMP_HOOK: {
m = PyObject_CallMethod(loader, "load_module", "s", name);
break;
}
return m;
}
这段代码前面同样也见过,前面介绍了源码,目录,字节码等的加载方式,Loader其实是作用于IMP_HOOK类型的加载方式,这种类型会直接调用Loader类方法load_module来实现自定义的加载模块,然后返回这个加载的module对象。
导入器(Importor)
从前面两节我们已经了解到实现find_module函数的类是查找器,实现load_module函数是加载器,并了解了它们的作用原理。如果同时实现了这两个函数,那这个类就称为导入器(Importor)。
同时实现查找器与加载器接口
存于sys.path_hooks列表中
可以对不同的路径使用不同的导入器
path对应的importor会缓存在sys.path_importer_cache
导入器和查找器的作用原理是一样的,不过查找器对于所有路径都是使用一样的查找器(sys.meta_path里面遍历),但是Importor可以对于不同路径可以使用不同的Importor。sys.path_importer_cache可以获取并缓存每个路径所使用的Importor。
import流程总结
至此我们已经知道,自定义实现Finder,Loader 或者Importor,并把Finder添加到sys.meta_path或者把Importor添加到sys.path_hooks里面就可以实现用自定义逻辑来接管import流程。
代码热更新实现
function reload实现原理简述
至此我们终于知道,从何处来实现我们自定义的重新加载代码——通过修改find_module和load_module逻辑来做到reload的热更新。
再回顾一下内置reload的两个局限是:
1.reload有顺序依赖,必须按照import顺序来reload才能保证所有模块都加载最新代码
2.reload前后模块内类与函数地址会发生变化
针对这两个问题,分别有以下解决对策:
顺序依赖问题是由import语句本身导致的
将所有要热更的module从sys.modules中删除可以触发加载流程
通过钩子(Finder&Loader)接管import流程
热更新之后保持旧函数与类的地址不变或者代码更新
将新的函数与类的代码复制给旧函数就能实现代码的更新
将替换更新之后的旧函数设置回module中就可以保持函数对象不变
总结一下就是,我们可以把reload一个模块时,在自定义find_module查找模块时,不使用sys.modules缓存的module对象,而是把它pop删除,每次都重新加载所有依赖的模块的最新代码,这样就能保证不必关心reload顺序,也能保证所有依赖模块都更新到最新代码。另外我们把系统加载和缓存的旧module对象备份下来,之后重新加载的对象的所有成员(dict 属性对),都拷贝回旧对象,就能保证module成员的函数对象地址不变,但是函数代码又更新到最新。
reimport代码具体实现
# -*- coding: utf-8 -*-
import sys
import imp
import inspect
sys.old_modules = {}
sys.old_module_attrs = {}
_ignore_attrs = {
'__module__', '_reload_all', '__dict__', '__weakref__', '__doc__',
}
def reimport():
pass
def backup_module(full_name):
# [1].将module从缓存删除用以激活加载流程并备份module的函数与类
old_module = sys.modules.pop(full_name)
sys.old_modules[full_name] = old_module
sys.old_module_attrs[full_name] = dict(old_module.__dict__)
return old_module
def update_module(old_attrs, module):
for name, attr in inspect.getmembers(module):
if isinstance(attr, type) and attr is not type:
old_class = old_attrs.get(name)
if old_class:
update_type(old_class, attr, getattr(attr, '_reload_all', False))
setattr(module, name, old_class)
elif inspect.isfunction(attr):
old_fun = old_attrs.get(name)
if not update_fun(old_fun,attr):
old_attrs[name] = attr
else:
setattr(module, name, old_fun)
if not getattr(module, '_reload_all', False):
module.__dict__.update(old_attrs)
def update_fun(old_fun, new_fun, update_cell_depth=2):
old_cell_num = 0
if old_fun.func_closure:
old_cell_num = len(old_fun.func_closure)
new_cell_num = 0
if new_fun.func_closure:
new_cell_num = len(new_fun.func_closure)
if old_cell_num != new_cell_num:
return False
setattr(old_fun, 'func_code', new_fun.func_code)
setattr(old_fun, 'func_defaults', new_fun.func_defaults)
setattr(old_fun, 'func_doc', new_fun.func_doc)
if old_fun.func_dict:
# 直接赋值,会使func上的旧有的属性丢失
old_fun.func_dict.update(new_fun.func_dict)
else:
setattr(old_fun, 'func_dict', new_fun.func_dict)
if not (update_cell_depth and old_cell_num):
return True
for index, cell in enumerate(old_fun.func_closure):
if inspect.isfunction(cell.cell_contents):
update_fun(cell.cell_contents, new_fun.func_closure[index].cell_contents, update_cell_depth - 1)
return True
def update_type(old_class, new_class, reload_all):
for name, attr in old_class.__dict__.items(): # delete function
if name in new_class.__dict__:
continue
if not inspect.isfunction(attr):
continue
type.__delattr__(old_class, name)
for name, attr in new_class.__dict__.iteritems():
if name not in old_class.__dict__: # new attribute
setattr(old_class, name, attr)
continue
old_attr = old_class.__dict__[name]
new_attr = attr
if inspect.isfunction(old_attr) and inspect.isfunction(new_attr):
if not update_fun(old_attr, new_attr):
setattr(old_class, name, new_attr)
elif isinstance(new_attr, staticmethod) or isinstance(new_attr, classmethod):
if not update_fun(old_attr.__func__, new_attr.__func__):
old_attr.__func__ = new_attr.__func__
elif reload_all and name not in _ignore_attrs:
setattr(old_class, name, attr)
class Finder(object):
def find_module(self, full_name, path):
backup_module(full_name)
# [2].将module放回去缓存中,实现在加载过程中不要创建新的module实例
sys.modules[full_name] = sys.old_modules[full_name]
# [3].标准库提供的对于 find_module/load_module 的封装,重新加载module
fd, path, des = imp.find_module(full_name.split('.')[-1], path)
module = imp.load_module(full_name, fd, path, des)
print("Finder name= %s mid= %s" % (full_name, id(module)))
# [4].将备份的old_attrs与更新后module进行代码更新与替换并返回更新后的module
update_module(sys.old_module_attrs[full_name], module)
return Loader(module)
reimport模块的只要逻辑就在查找器的find_module函数里面,首先备份当前已经加载的module,用sys.old_modules, sys.old_module_attrs分别记录备份的所有module和每个module的所有属性。然后用系统标准库提供的find_module和load_module重新加载模块,这时加载出来的新模块的函数地址,相对于旧模块时发生变化的。我们调用update_module把更新后的新模块都拷贝到sys.old_module_attrs的属性值里面,并返回更新的module,这个module就是更新代码已更新,但是module内的类和函数地址不变的module对象。
验证reimport实现了代码热更
验证reimport实现保证了代码更新但函数地址不变
先看测试代码:
# -*- coding: utf-8 -*-
# ############################################
# Author:liudinglong
# Filename:test.py
# Created Time:2021-06-28
# Description:
# ############################################
import reimport
import sys
import time
from string import Template
filename = "test_module.py"
template_src = """
class A(object):
@staticmethod
def print_attr():
print("$tag")
return "$tag"
def print_val():
print("$tag")
return "$tag"
"""
s = Template(template_src)
old_format= {'tag' : 'old'}
def write_src(filename, src):
with open(filename, 'w') as file_object:
file_object.write(src)
write_src(filename, s.substitute(old_format))
import test_module
print("before reload, module id: %s" % id(test_module))
print("before reload, class method print_attr id: %s" % id(test_module.A.print_attr))
print("before reload, call class method print_attr: %s" % test_module.A.print_attr())
print("before reload, module method print_val id: %s" % id(test_module.print_val))
print("before reload, call method print_val: %s" % test_module.print_val())
time.sleep(2)
# sys.meta_path.append(reimport.Finder())
new_format= {'tag' : 'new'}
write_src(filename, s.substitute(new_format))
reload(test_module)
print("after reload, module id: %s" % id(test_module))
print("after reload, class method print_attr id: %s" % id(test_module.A.print_attr))
print("after reload, call class method print_attr: %s" % test_module.A.print_attr())
print("after reload, module method print_val id: %s" % id(test_module.print_val))
print("after reload, call method print_val: %s" % test_module.print_val())
测试脚本定义一个类静态函数(print_attr)和模块内全局函数(print_val),分别打印一个tag,更新代码前两个函数都打印 old, 更新代码后两个函数都应该打印new。前后我们分别打印出,模块id,类静态函数(print_attr)id,模块内全局函数(print_val)id, ,类静态函数(print_attr)调用结果,模块内全局函数(print_val)调用结果。
注意第一次修改代码后,调用了time.sleep(2),休眠了2s才修改文件,是因为只有load_module加载模块时,当检测到有pyc字节码文件后,会检测py文件有没有发生改变,这个检测是通过记录文件时间戳来分辨的,如果中间不休眠,在同一秒内修改文件,load_module过程不会重新编译pyc字节码文件会导致代码无法更新。
测试代码中使用sys.meta_path.append(reimport.Finder())添加了自定义的查找器,来实现热更。
我们先注释这行,看原生查找器下,reload的效果:
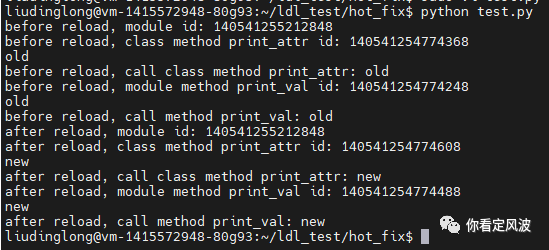
从测试结果可以看出,原生查找器下reload能更新类静态函数和模块内全局函数,但是会改变函数地址。
再看用自定义查找器后,reload的效果:
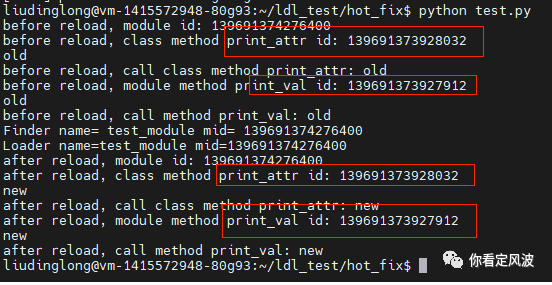
从上图可以看出代码更新了,而且函数地址不会发生改变,达到了热更代码要的效果。
验证reimport实现保证了代码reload不依赖于import顺序
# -*- coding: utf-8 -*-
# ############################################
# Author:liudinglong
# Filename:module_A.py
# Created Time:2021-06-28
# Description:
# ############################################
from module_B import print_val
# -*- coding: utf-8 -*-
# ############################################
# Author:liudinglong
# Filename:test_muti_import.py
# Created Time:2021-06-28
# Description:
# ############################################
import reimport
import sys
import time
from string import Template
filename = "module_B.py"
template_src = """
def print_val():
print("$tag")
return "$tag"
"""
s = Template(template_src)
old_format= {'tag' : 'old'}
def write_src(filename, src):
with open(filename, 'w') as file_object:
file_object.write(src)
write_src(filename, s.substitute(old_format))
time.sleep(2)
import module_A
import module_B
print("before reload module_A.print_val id: %s" % id(module_A.print_val))
print("before reload module_A.print_val(): %s" % module_A.print_val())
# sys.meta_path.append(reimport.Finder())
new_format= {'tag' : 'new'}
write_src(filename, s.substitute(new_format))
reload(module_A)
reload(module_B)
print("before reload module_A.print_val id: %s" % id(module_A.print_val))
print("before reload module_A.print_val(): %s" % module_A.print_val())
reload(module_B)
reload(module_A)
print("before reload module_A.print_val id: %s" % id(module_A.print_val))
print("before reload module_A.print_val(): %s" % module_A.print_val())
同样直接看测试代码,module_A里面执行from module_B import print_val,引入module_B的print_val函数。module_B.py在test_muti_import.py里面动态生成, print_val先打印old,后面更新代码改成打印new。
同样注释掉# sys.meta_path.append(reimport.Finder()), 执行一遍test_muti_import.py测试文件,得到如下结果:
从上图可以看出,原生查找器下的reload,先reload module_A根本不会更新代码,函数地址和函数代码都没更新;先reload module_B才会更新代码,但是函数地址会发生变化。
再看加上sys.meta_path.append(reimport.Finder()),用自定义查找器reload的结果: 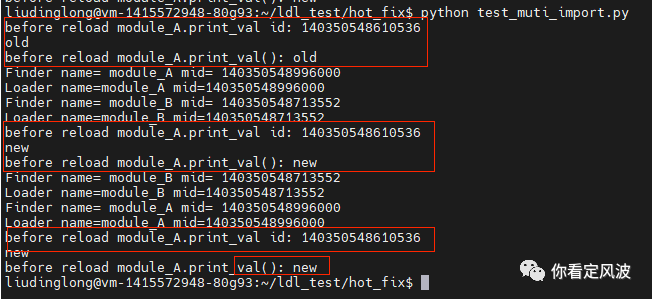
从上图可以看出无论reload顺序是怎样的,代码始终能更新,而且函数地址不会发生变化。因此 这个查找器实现也解决了原生reload依赖于import顺序的问题。
热更新原理总结
至此,我们已经了解了热更新的原理,并自定义实现了查找器来进行热更新代码,并且验证了热更新是有效的。热更新的原理就是通过接管find_module和load_module流程,来实现自己对module对象的属性做更新,但是还保留源module的成员地址。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY