ScheduledThreadPoolExecutor源码分析-你知道定时线程池是如何实现延迟执行和周期执行的吗?
Java版本:8u261。
1 简介
ScheduledThreadPoolExecutor即定时线程池,是用来执行延迟任务或周期性任务的。相比于Timer的单线程,定时线程池在遇到任务抛出异常的时候不会关闭整个线程池,更加健壮(需要提一下的是:ScheduledThreadPoolExecutor和ThreadPoolExecutor一样,如果执行任务的过程中抛异常的话,这个任务是会被丢弃的。所以在任务的执行过程中需要对异常做捕获处理,有必要的话需要做补偿措施)。
传进来的任务会被包装为ScheduledFutureTask,其继承于FutureTask,提供异步执行的能力,并且可以返回执行结果。同时实现了Delayed接口,可以通过getDelay方法来获取延迟时间。
相比于ThreadPoolExecutor,ScheduledThreadPoolExecutor中使用的队列是DelayedWorkQueue,是一个无界的队列。所以在定时线程池中,最大线程数是没有意义的(最大线程数会固定为int的最大值,且不会作为定时线程池的参数)。在ThreadPoolExecutor中,如果当前线程数小于核心线程数就直接创建核心线程来执行任务,大于等于核心线程数的话才往阻塞队列中放入任务;而在ScheduledThreadPoolExecutor中却不是这种逻辑。ScheduledThreadPoolExecutor中上来就会把任务放进延迟队列中,然后再去等待执行。
1.1 小顶堆
DelayedWorkQueue的实现有些特殊,是基于小顶堆构建的(与DelayQueue和PriorityQueue类似)。因为要保证每次从延迟队列中拿取到的任务是距现在最近的一个,所以使用小顶堆结构来构建是再适合不过了(堆结构也常常用来解决前N小和前N大的问题)。小顶堆保证每个节点的值不小于其父节点的值,而不大于其孩子节点的值,而对于同级节点来说则没有什么限制。这样在小顶堆中值最小的点永远保证是在根节点处。如果用数组来构建小顶堆的话,值最小的点就在数组中的第一个位置处。
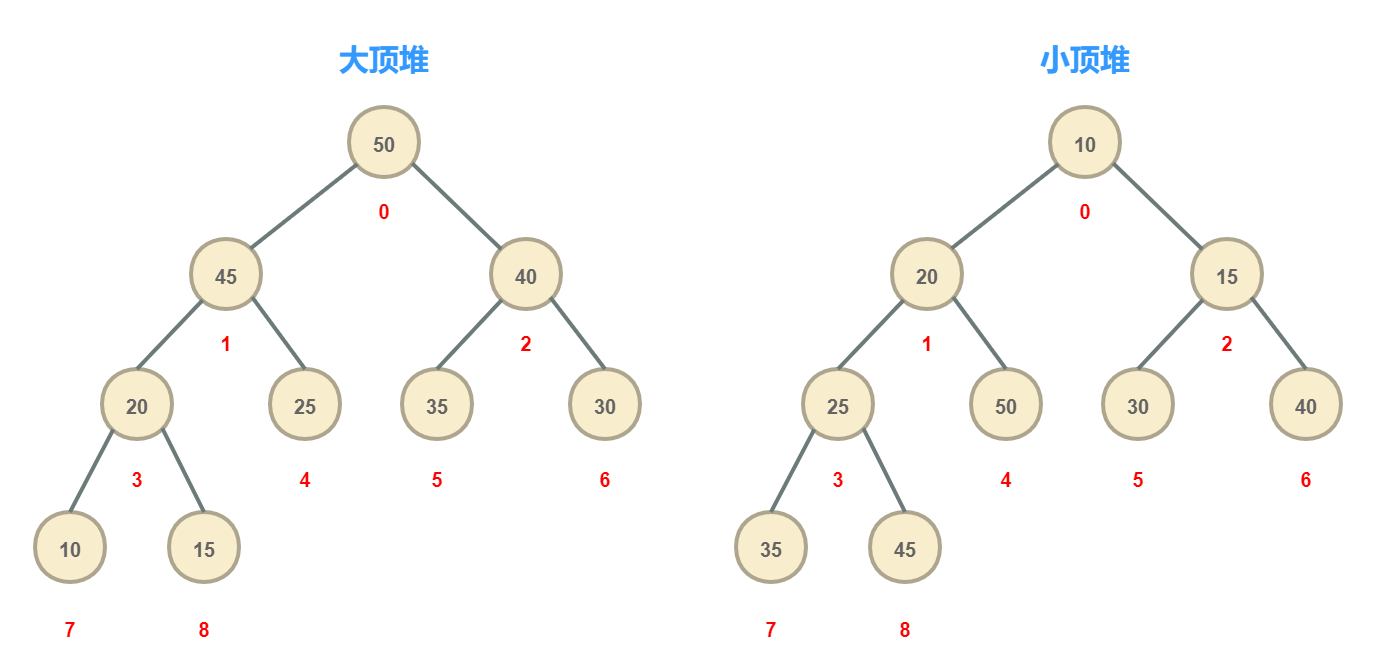
图中红色的数字代表节点在数组中的索引位置,由此可以看出堆的另一条性质是:假设当前节点的索引是k,那么其父节点的索引是:(k-1)/2;左孩子节点的索引是:k2+1;而右孩子节点的索引是k2+2。
构建堆的两个核心方法是siftUp和siftDown,siftUp方法用于添加节点时的上溯过程;而siftDown方法用于删除节点时的下溯过程。具体的实现源码会在下面进行分析,这里就画图来理解一下(下面只会分析经典的小顶堆添加和删除节点的实现,而在源码中的实现略有不同,但核心都是一样的):
1.1.1 添加节点

如果在上面的siftUp过程中,发现某一次当前节点的值就已经大于了父节点的值,siftUp过程也就会提前终止了。同时可以看出:在上面的siftUp以及下面将要讲的siftDown操作过程中,每次都只会比较并交换当前节点和其父子节点的值,而不是整个堆都发生变动,降低了时间复杂度。
1.1.2 删除节点
删除节点分为三种情况,首先来看一下删除根节点的情况:
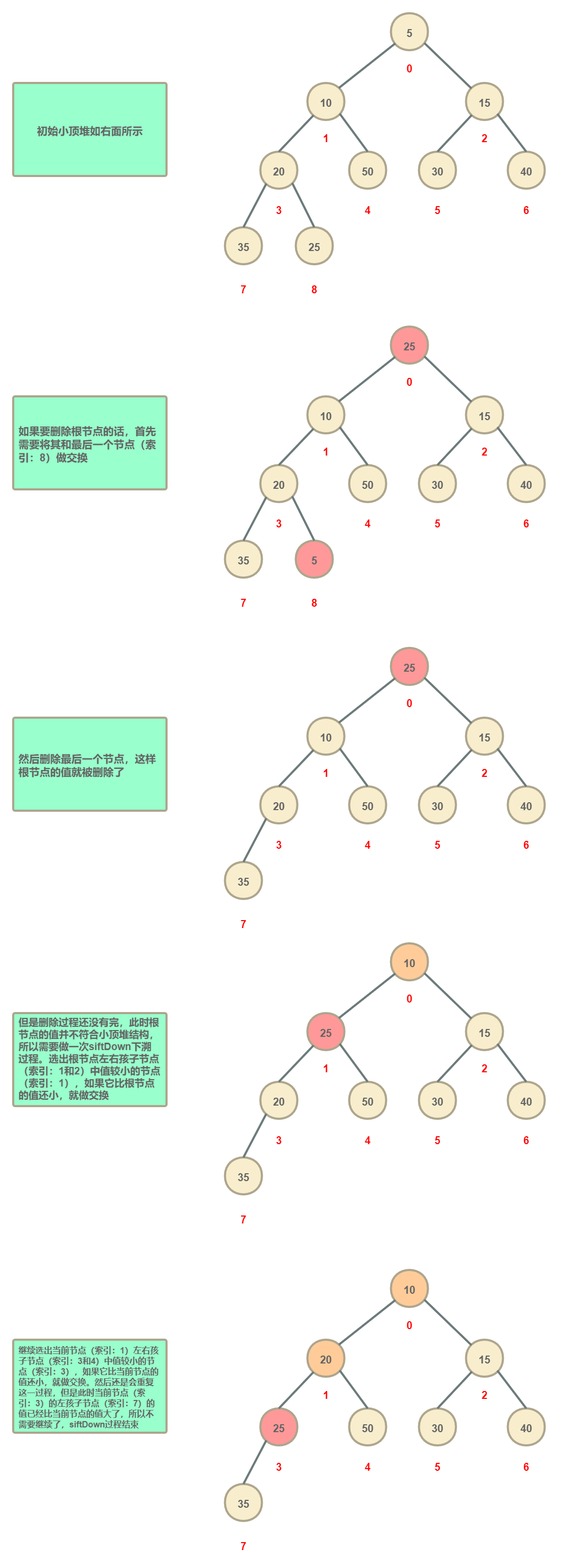
然后是删除最后一个节点的情况。删除最后一个节点是最简单的,只需要进行删除就行了,因为这并不影响小顶堆的结构,不需要进行调整。这里就不再展示了(注意:删除除了最后一个节点的其他叶子节点并不属于当前这种情况,而是属于下面第三种情况。也就是说删除这些叶子节点并不能简单地删除它们就完了的,因为堆结构首先得保证是一颗完全二叉树)。
最后是删除既不是根节点又不是最后一个节点的情况:

在删除既不是根节点又不是最后一个节点的时候,可以看到执行了一次siftDown并伴随了一次siftUp的过程。但是这个siftUp过程并不是会一定触发的,只有满足最后一个节点的值比要删除节点的父节点的值还要小的时候才会触发siftUp操作(这个很好推理:在小顶堆中如果最后一个节点值比要删除节点的父节点值要小的话,那么要删除节点的左右孩子节点值也必然是都大于最后一个节点值的(不考虑值相等的情况),那么此时就不会发生siftDown操作;而如果发生了siftDown操作,就说明最后一个节点值至少要比要删除节点的左右孩子节点中的一个要大(如果有左右孩子节点的话)。而孙子节点值是肯定要大于爷爷节点值的(不考虑值相等的情况),所以也就是说发生了siftDown操作的时候,最后一个节点值是比要删除节点的父节点值大的。这个时候孙子节点和最后一个节点siftDown交换后,依然是满足小顶堆性质的,所以就不需要附加的siftUp操作;还有一种情况是最后一个节点值是介于要删除节点的父节点值和要删除节点的左右孩子节点值中的较小者,那么这个时候既不会发生siftDown,也不会发生siftUp)。
而源码中的实现和上面的经典实现最大的不同就是不会有节点彼此交换的操作。在siftUp和siftDown的经典实现中,如果需要变动节点时,都会来一次父子节点的互相交换操作(包括删除节点时首先做的要删除节点和最后一个节点之间的交换操作也是如此)。如果仔细思考的话,就会发现这其实是多余的。在需要交换节点的时候,只需要siftUp操作时的父节点或siftDown时的孩子节点重新移到当前需要比较的节点位置上,而比较节点是不需要移动到它们的位置上的。此时直接进入到下一次的判断中,重复siftUp或siftDown过程,直到最后找到了比较节点的插入位置后,才会将其插入进去。这样做的好处是可以省去一半的节点赋值的操作,提高了执行的效率。同时这也就意味着,需要将要比较的节点作为参数保存起来,而源码中也正是这么实现的。
1.2 Leader-Follower模式
ScheduledThreadPoolExecutor中使用了Leader-Follower模式。这是一种设计思想,假如说现在有一堆等待执行的任务(一般是存放在一个队列中排好序),而所有的工作线程中只会有一个是leader线程,其他的线程都是follower线程。只有leader线程能执行任务,而剩下的follower线程则不会执行任务,它们会处在休眠中的状态。当leader线程拿到任务后执行任务前,自己会变成follower线程,同时会选出一个新的leader线程,然后才去执行任务。如果此时有下一个任务,就是这个新的leader线程来执行了,并以此往复这个过程。当之前那个执行任务的线程执行完毕再回来时,会判断如果此时已经没任务了,又或者有任务但是有其他的线程作为leader线程,那么自己就休眠了;如果此时有任务但是没有leader线程,那么自己就会重新成为leader线程来执行任务。
不像ThreadPoolExecutor是需要立即执行任务的,ScheduledThreadPoolExecutor中的任务是延迟执行的,而拿取任务也是延迟拿取的。所以并不需要所有的线程都处于运行状态延时等待获取任务。而如果这么做的话,最后也只会有一个线程能执行当前任务,其他的线程还是会被再次休眠的(这里只是在说单任务多线程的情况,但对于多任务来说也是一样的,总结来说就是Leader-Follower模式只会唤醒真正需要“干事”的线程)。这是很没有必要的,而且浪费资源。所以使用Leader-Follower模式的好处是:避免没必要的唤醒和阻塞的操作,这样会更加有效,且节省资源。
2 构造器
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 public ScheduledThreadPoolExecutor(int corePoolSize) {
5 super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
6 new DelayedWorkQueue());
7 }
8
9 /**
10 * ThreadPoolExecutor:
11 */
12 public ThreadPoolExecutor(int corePoolSize,
13 int maximumPoolSize,
14 long keepAliveTime,
15 TimeUnit unit,
16 BlockingQueue<Runnable> workQueue) {
17 this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
18 Executors.defaultThreadFactory(), defaultHandler);
19 }
可以看到:ScheduledThreadPoolExecutor的构造器是调用了父类ThreadPoolExecutor的构造器来实现的,而父类的构造器以及之中的所有参数我在之前分析ThreadPoolExecutor的源码文章中讲过,这里就不再赘述了。
3 schedule方法
execute方法和submit方法内部都是调用的schedule方法,所以来看一下其实现:
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 public ScheduledFuture<?> schedule(Runnable command,
5 long delay,
6 TimeUnit unit) {
7 //非空校验
8 if (command == null || unit == null)
9 throw new NullPointerException();
10 //包装任务
11 RunnableScheduledFuture<?> t = decorateTask(command,
12 new ScheduledFutureTask<Void>(command, null,
13 triggerTime(delay, unit)));
14 //延迟执行
15 delayedExecute(t);
16 return t;
17 }
18
19 /**
20 * 第13行代码处:
21 * 延迟操作的触发时间
22 */
23 private long triggerTime(long delay, TimeUnit unit) {
24 //delay非负处理
25 return triggerTime(unit.toNanos((delay < 0) ? 0 : delay));
26 }
27
28 long triggerTime(long delay) {
29 /*
30 now方法内部就一句话:“System.nanoTime();”,也就是获取当前时间。这里也就是获取
31 当前时间加上延迟时间后的结果。如果延迟时间超过了上限,会在overflowFree方法中处理
32 */
33 return now() +
34 ((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay));
35 }
36
37 private long overflowFree(long delay) {
38 //获取队头节点(不移除)
39 Delayed head = (Delayed) super.getQueue().peek();
40 if (head != null) {
41 //获取队头的剩余延迟时间
42 long headDelay = head.getDelay(NANOSECONDS);
43 /*
44 能走进本方法中,就说明delay是一个接近long最大值的数。此时判断如果headDelay小于0
45 就说明延迟时间已经到了或过期了但是还没有执行,并且delay和headDelay的差值小于0,说明headDelay
46 和delay的差值已经超过了long的范围
47 */
48 if (headDelay < 0 && (delay - headDelay < 0))
49 //此时更新一下delay的值,确保其和headDelay的差值在long的范围内,同时delay也会重新变成一个正数
50 delay = Long.MAX_VALUE + headDelay;
51 }
52 return delay;
53 }
54
55 /**
56 * 第39行代码处:
57 * 调用DelayedWorkQueue中覆写的peek方法来获取队头节点
58 */
59 public RunnableScheduledFuture<?> peek() {
60 final ReentrantLock lock = this.lock;
61 lock.lock();
62 try {
63 return queue[0];
64 } finally {
65 lock.unlock();
66 }
67 }
68
69 /**
70 * 第42行代码处:
71 * 可以看到本方法就是获取延迟时间和当前时间的差值
72 */
73 public long getDelay(TimeUnit unit) {
74 return unit.convert(time - now(), NANOSECONDS);
75 }
4 包装任务
上面第11行和第12行代码处会进行任务的包装:
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 ScheduledFutureTask(Runnable r, V result, long ns) {
5 //调用父类FutureTask的构造器
6 super(r, result);
7 //这里会将延迟时间赋值给this.time
8 this.time = ns;
9 //period用来表示任务的类型,为0表示延迟任务,否则表示周期性任务
10 this.period = 0;
11 //这里会给每一个任务赋值一个唯一的序列号。当延迟时间相同时,会以该序列号来进行判断。序列号小的会出队
12 this.sequenceNumber = sequencer.getAndIncrement();
13 }
14
15 /**
16 * schedule方法第11行代码处:
17 * 包装任务,这里只是返回task而已,子类可以覆写本方法中的逻辑
18 */
19 protected <V> RunnableScheduledFuture<V> decorateTask(
20 Runnable runnable, RunnableScheduledFuture<V> task) {
21 return task;
22 }
5 delayedExecute方法
在schedule方法的第15行代码处会执行延迟任务,添加任务和补充工作线程:
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 private void delayedExecute(RunnableScheduledFuture<?> task) {
5 if (isShutdown())
6 /*
7 这里会调用父类ThreadPoolExecutor的isShutdown方法来判断当前线程池是否处于关闭或正在关闭的状态,
8 如果是的话就执行具体的拒绝策略
9 */
10 reject(task);
11 else {
12 //否则就往延迟队列中添加当前任务
13 super.getQueue().add(task);
14 /*
15 添加后继续判断当前线程池是否处于关闭或正在关闭的状态,如果是的话就判断此时是否还能继续执行任务,
16 如果不能的话就删除上面添加的任务
17 */
18 if (isShutdown() &&
19 !canRunInCurrentRunState(task.isPeriodic()) &&
20 remove(task))
21 //同时会取消此任务的执行
22 task.cancel(false);
23 else
24 //否则,说明线程池是可以继续执行任务的,就去判断此时是否需要补充工作线程
25 ensurePrestart();
26 }
27 }
28
29 /**
30 * 第19行代码处:
31 * 传进来的periodic表示任务是否是周期性任务,如果是的话就是true(通过“period != 0”进行判断)
32 */
33 boolean canRunInCurrentRunState(boolean periodic) {
34 return isRunningOrShutdown(periodic ?
35 //关闭线程池时判断是否需要继续执行周期性任务
36 continueExistingPeriodicTasksAfterShutdown :
37 //关闭线程池时判断是否需要继续执行延迟任务
38 executeExistingDelayedTasksAfterShutdown);
39 }
40
41 /**
42 * ThreadPoolExecutor:
43 */
44 final boolean isRunningOrShutdown(boolean shutdownOK) {
45 //获取当前线程池的运行状态
46 int rs = runStateOf(ctl.get());
47 //如果是RUNNING状态的,或者是SHUTDOWN状态并且是能继续执行任务的,就返回true
48 return rs == RUNNING || (rs == SHUTDOWN && shutdownOK);
49 }
50
51 /**
52 * ScheduledThreadPoolExecutor:
53 * 上面第20行代码处的remove方法会调用ThreadPoolExecutor的remove方法,而该方法我在之前的
54 * ThreadPoolExecutor的源码分析文章中已经分析过了。但是其中会调用延迟队列覆写的remove逻辑,
55 * 也就是本方法(同时第130行代码处也会调用到这里)
56 */
57 public boolean remove(Object x) {
58 final ReentrantLock lock = this.lock;
59 //加锁
60 lock.lock();
61 try {
62 //获取当前节点的堆索引位
63 int i = indexOf(x);
64 if (i < 0)
65 //如果找不到的话,就直接返回false
66 return false;
67
68 //将当前节点的索引位设置为-1,因为下面要进行删除了
69 setIndex(queue[i], -1);
70 //size-1
71 int s = --size;
72 //获取小顶堆的最后一个节点,用于替换
73 RunnableScheduledFuture<?> replacement = queue[s];
74 //将最后一个节点置为null
75 queue[s] = null;
76 //如果要删除的节点本身就是最后一个节点的话,就可以直接返回true了,因为不影响小顶堆的结构
77 if (s != i) {
78 /*
79 否则执行一次siftDown下溯过程,将最后一个节点的值重新插入到小顶堆中
80 这其中会删除i位置处的节点(siftDown方法后面会再次调用,到时候再来详细分析该方法的实现)
81 */
82 siftDown(i, replacement);
83 /*
84 经过上面的siftDown的操作后,如果最后一个节点的延迟时间本身就比要删除的节点的小的话,
85 那么就会直接将最后一个节点放在要删除节点的位置上。此时从删除节点到其下面的节点都是满足
86 小顶堆结构的,但是不能保证replacement也就是当前删除后的替换节点和其父节点之间满足小顶堆
87 结构,也就是说可能出现replacement节点的延迟时间比其父节点的还小的情况
88 */
89 if (queue[i] == replacement)
90 //那么此时就调用一次siftUp上溯操作,再次调整replacement节点其上的小顶堆的结构即可
91 siftUp(i, replacement);
92 }
93 return true;
94 } finally {
95 //释放锁
96 lock.unlock();
97 }
98 }
99
100 /**
101 * 第63行代码处:
102 */
103 private int indexOf(Object x) {
104 if (x != null) {
105 if (x instanceof ScheduledFutureTask) {
106 //如果当前节点是ScheduledFutureTask类型的,就获取它的堆索引位
107 int i = ((ScheduledFutureTask) x).heapIndex;
108 //大于等于0和小于size说明当前节点还在小顶堆中,并且当前节点还在延迟队列中的话,就直接返回该索引位
109 if (i >= 0 && i < size && queue[i] == x)
110 return i;
111 } else {
112 //否则就按照普通遍历的方式查找是否有相等的节点,如果有的话就返回索引位
113 for (int i = 0; i < size; i++)
114 if (x.equals(queue[i]))
115 return i;
116 }
117 }
118 //找不到的话就返回-1
119 return -1;
120 }
121
122 /**
123 * 第22行代码处:
124 */
125 public boolean cancel(boolean mayInterruptIfRunning) {
126 //调用FutureTask的cancel方法来尝试取消此任务的执行
127 boolean cancelled = super.cancel(mayInterruptIfRunning);
128 //如果取消成功了,并且允许删除节点,并且当前节点存在于小顶堆中的话,就删除它
129 if (cancelled && removeOnCancel && heapIndex >= 0)
130 remove(this);
131 return cancelled;
132 }
133
134 /**
135 * ThreadPoolExecutor:
136 * 第25行代码处:
137 */
138 void ensurePrestart() {
139 //获取当前线程池的工作线程数
140 int wc = workerCountOf(ctl.get());
141 if (wc < corePoolSize)
142 /*
143 如果小于核心线程数,就添加一个核心线程,之前我在分析ThreadPoolExecutor的源码文章中讲过,
144 addWorker方法的执行中会同时启动运行线程。这里传入的firstTask参数为null,因为不需要立即执行任务,
145 而是从延迟队列中拿取任务
146 */
147 addWorker(null, true);
148 else if (wc == 0)
149 //如果当前没有工作线程,就去添加一个非核心线程,然后运行它。保证至少要有一个线程
150 addWorker(null, false);
151 /*
152 从这里可以看出,如果当前的工作线程数已经达到了核心线程数后,就不会再创建工作线程了
153 定时线程池最多只有“核心线程数”个线程,也就是通过构造器传进来的参数大小
154 */
155 }
6 添加任务
因为延迟队列是用小顶堆构建的,所以添加的时候会涉及到小顶堆的调整:
1 /**
2 * ScheduledThreadPoolExecutor:
3 * 这里会调用DelayedWorkQueue的add方法
4 */
5 public boolean add(Runnable e) {
6 return offer(e);
7 }
8
9 public boolean offer(Runnable x) {
10 //非空校验
11 if (x == null)
12 throw new NullPointerException();
13 //强转类型
14 RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>) x;
15 final ReentrantLock lock = this.lock;
16 //加锁
17 lock.lock();
18 try {
19 //获取当前的任务数量
20 int i = size;
21 //判断是否需要扩容(初始容量为16)
22 if (i >= queue.length)
23 grow();
24 //size+1
25 size = i + 1;
26 if (i == 0) {
27 //如果当前是第一个任务的话,就直接放在小顶堆的根节点位置处就行了(队列第一个位置)
28 queue[0] = e;
29 //同时设置一下当前节点的堆索引位为0
30 setIndex(e, 0);
31 } else {
32 //否则就用siftUp的方式来插入到应该插入的位置
33 siftUp(i, e);
34 }
35 //经过上面的插入过程之后,如果小顶堆的根节点还是当前新添加节点的话,说明新添加节点的延迟时间是最短的
36 if (queue[0] == e) {
37 //那么此时不管有没有leader线程,都得将其置为null
38 leader = null;
39 /*
40 并且重新将条件队列上的一个节点转移到CLH队列中(如果当前只有一个节点的时候也会进入到signal方法中
41 但无妨,因为此时条件队列中还没有节点,所以并不会做什么)需要提一点的是:如果真的看过signal方法内部实现
42 的话就会知道,signal方法在常规情况下并不是在做唤醒线程的工作,唤醒是在下面的unlock方法中实现的
43 */
44 available.signal();
45 }
46 } finally {
47 /*
48 释放锁(注意,这里只会唤醒CLH队列中的head节点的下一个节点,可能是上面被锁住的添加任务的其他线程、
49 也可能是上次执行完任务后准备再次拿取任务的线程,还有可能是等待被唤醒的follower线程,又或者有其他的
50 情况。但不管是哪个,只要能保证唤醒动作是一直能被传播下去的就行。ReentrantLock和阻塞队列的执行细节
51 详见我之前对AQS源码进行分析的文章)
52 */
53 lock.unlock();
54 }
55 return true;
56 }
57
58 /**
59 * 第23行代码处:
60 */
61 private void grow() {
62 int oldCapacity = queue.length;
63 //可以看到这里的扩容策略是*1.5的方式
64 int newCapacity = oldCapacity + (oldCapacity >> 1);
65 //如果扩容后的新容量溢出了,就将其恢复为int的最大值
66 if (newCapacity < 0)
67 newCapacity = Integer.MAX_VALUE;
68 //使用Arrays.copyOf(System.arraycopy)的方式来进行数组的拷贝
69 queue = Arrays.copyOf(queue, newCapacity);
70 }
71
72 /**
73 * 第30行、第99行和第109行代码处:
74 * 设置f节点在小顶堆中的索引位为idx,这样在最后的删除节点时可以通过index是否大于0来判断当前节点是否仍在小顶堆中
75 */
76 private void setIndex(RunnableScheduledFuture<?> f, int idx) {
77 if (f instanceof ScheduledFutureTask)
78 ((ScheduledFutureTask) f).heapIndex = idx;
79 }
80
81 /**
82 * 第33行代码处:
83 * 堆排序的精髓就在于siftUp和siftDown方法,但本实现与常规的实现略有不同,多了一个入参key
84 * key代表当前要插入节点中的任务
85 */
86 private void siftUp(int k, RunnableScheduledFuture<?> key) {
87 //当k<=0的时候说明已经上溯到根节点了
88 while (k > 0) {
89 //获取父节点的索引((当前节点索引位-1)/2的方式)
90 int parent = (k - 1) >>> 1;
91 //获取父节点的任务
92 RunnableScheduledFuture<?> e = queue[parent];
93 //如果当前要插入节点中的任务延迟时间大于父节点的延迟时间的话,就停止上溯过程,说明找到了插入的位置
94 if (key.compareTo(e) >= 0)
95 break;
96 //否则就需要将父节点的内容赋值给当前节点
97 queue[k] = e;
98 //同时设置一下父节点的堆索引位为当前节点处
99 setIndex(e, k);
100 //然后将父节点赋值给当前节点,继续下一次的上溯过程
101 k = parent;
102 }
103 /*
104 走到这里说明有两种情况:<1>已经结束了上溯的过程,但最后一次的父节点还没有赋值,这里就是进行赋值的操作;
105 <2>如果本方法进来的时候要添加的最后一个节点本身就满足小顶堆条件的话,那么该处就是在给最后一个节点进行赋值
106 */
107 queue[k] = key;
108 //同时设置一下要插入节点的堆索引位
109 setIndex(key, k);
110 }
111
112 /**
113 * 第94行代码处:
114 */
115 public int compareTo(Delayed other) {
116 //如果比较的就是当前对象,就直接返回0相等
117 if (other == this)
118 return 0;
119 if (other instanceof ScheduledFutureTask) {
120 //如果需要比较的任务也是ScheduledFutureTask类型的话,就首先强转一下类型
121 ScheduledFutureTask<?> x = (ScheduledFutureTask<?>) other;
122 //计算当前任务和需要比较的任务之间的延迟时间差
123 long diff = time - x.time;
124 if (diff < 0)
125 //小于0说明当前任务的延迟时间更短,就返回-1
126 return -1;
127 else if (diff > 0)
128 //大于0说明需要比较的任务的延迟时间更短,就返回1
129 return 1;
130 //如果两者相等的话,就比较序列号,谁的序列号更小(序列号是唯一的),就应该先被执行
131 else if (sequenceNumber < x.sequenceNumber)
132 return -1;
133 else
134 return 1;
135 }
136 //如果需要比较的任务不是ScheduledFutureTask类型的话,就通过getDelay的方式来进行比较
137 long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
138 return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
139 }
7 拿取任务
在上面的ensurePrestart方法中会调用到addWorker方法,以此来补充工作线程。之前我对ThreadPoolExecutor源码进行分析的文章中说到过,addWorker方法会调用到getTask方法来从队列中拿取任务:
1 /**
2 * ThreadPoolExecutor:
3 */
4 private Runnable getTask() {
5 //...
6 /*
7 这里的allowCoreThreadTimeOut默认为false(为true表示空闲的核心线程也是要超时销毁的),
8 而上面说过定时线程池最多只有“核心线程数”个线程,所以timed为false
9 */
10 boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
11 //...
12 //因为timed为false,所以这里会走take方法中的逻辑
13 Runnable r = timed ?
14 workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
15 workQueue.take();
16 //...
17 }
18
19 /**
20 * ScheduledThreadPoolExecutor:
21 * 第15行代码处:
22 * 上面的take方法会调用到DelayedWorkQueue的take方法,而该方法也就是用来实现延迟拿取任务的
23 */
24 public RunnableScheduledFuture<?> take() throws InterruptedException {
25 final ReentrantLock lock = this.lock;
26 //加锁(响应中断模式)
27 lock.lockInterruptibly();
28 try {
29 for (; ; ) {
30 //获取队头节点
31 RunnableScheduledFuture<?> first = queue[0];
32 if (first == null)
33 /*
34 如果当前延迟队列中没有延迟任务,就在这里阻塞当前线程(通过AQS中条件队列的方式),等待有任务时被唤醒
35 另外,当线程执行完任务后也会再次走到getTask方法中的本方法中。如果此时没任务了,就会在此被阻塞休眠住
36 (我在之前AQS源码分析的文章中说过:await方法中会释放掉所有的ReentrantLock锁资源,然后才会被阻塞住)
37 */
38 available.await();
39 else {
40 //否则就获取队头的剩余延迟时间
41 long delay = first.getDelay(NANOSECONDS);
42 //如果延迟时间已经到了的话,就删除并返回队头,表示拿取到了任务
43 if (delay <= 0)
44 return finishPoll(first);
45 /*
46 这里将队头节点的引用置为null,如果不置为null的话,可能有多个等待着的线程同时持有着队头节点的
47 first引用,这样如果要删除队头节点的话,因为其还有其他线程的引用,所以不能被及时回收,造成内存泄漏
48 */
49 first = null;
50 /*
51 如果leader不为null,说明有其他的线程已经成为了leader线程,正在延迟等待着
52 同时此时没有新的延迟时间最短的节点进入到延迟队列中
53 */
54 if (leader != null)
55 /*
56 那么当前线程就变成了follower线程,需要被阻塞住,等待被唤醒(同上,其中会释放掉所有的锁资源)
57 线程执行完任务后也会再次走到本方法中拿取任务,如果走到这里发现已经有别的leader线程了,
58 那么当前线程也会被阻塞休眠住;否则就会在下面的else分支中再次成为leader线程
59 */
60 available.await();
61 else {
62 /*
63 leader为null,可能是上一个leader线程拿取到任务后唤醒的下一个线程,也有可能
64 是一个新的延迟时间最短的节点进入到延迟队列中,从而将leader置为null
65
66 此时获取当前线程
67 */
68 Thread thisThread = Thread.currentThread();
69 //并将leader置为当前线程,也就是当前线程成为了leader线程
70 leader = thisThread;
71 try {
72 /*
73 这里也就是在做具体的延时等待delay纳秒的操作了,具体涉及到AQS中条件队列的相关操作
74 如果被唤醒的话可能是因为到达了延迟时间从而醒来;也有可能是被别的线程signal唤醒了;
75 还有可能是中断被唤醒。正常情况下是等到达了延迟时间后,这里会醒来并进入到下一次循环中的
76 finishPoll方法中,剔除队头节点并最终返回(awaitNanos方法和await方法类似,其中会释放掉
77 所有的锁资源;不一样的是在被唤醒时会把当前节点从条件队列中“转移”到CLH队列中。这里可以认为
78 是转移,因为在条件队列中的该节点状态已经改为了0,相当于是个垃圾节点,后续会进行删除)
79 */
80 available.awaitNanos(delay);
81 } finally {
82 /*
83 不管awaitNanos是如何被唤醒的,此时会判断当前的leader线程是否还是当前线程
84 如果是的话就将leader置为null,也就是当前线程不再是leader线程了
85 */
86 if (leader == thisThread)
87 leader = null;
88 }
89 }
90 }
91 }
92 } finally {
93 //在退出本方法之前,判断如果leader线程为null并且删除队头后的延迟队列仍然不为空的话(说明此时有其他的延迟任务)
94 if (leader == null && queue[0] != null)
95 //就将条件队列上的一个节点转移到CLH队列中(同时会剔除上面的垃圾条件节点)
96 available.signal();
97 /*
98 释放锁(同offer方法中的逻辑,这里只会唤醒CLH队列中的head节点的下一个节点。这里就体现了
99 Leader-Follower模式:当leader线程拿取到任务后准备要执行时,会首先唤醒剩下线程中的一个,
100 它将会成为新的leader线程,并以此往复。保证在任何时间都只有一个leader线程,避免不必要的唤醒与睡眠)
101 */
102 lock.unlock();
103 }
104 }
105
106 /**
107 * 第44行代码处:
108 */
109 private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
110 //size-1
111 int s = --size;
112 //获取队列中的最后一个节点
113 RunnableScheduledFuture<?> x = queue[s];
114 //并置空它,便于GC,这里也就是在删除最后一个节点
115 queue[s] = null;
116 //如果删除前延迟队列中有不止一个节点的话,就进入到siftDown方法中,将小顶堆中的根节点删除,并且重新维护小顶堆
117 if (s != 0)
118 siftDown(0, x);
119 //同时设置一下删除前的根节点的堆索引位为-1,表示其不存在于小顶堆中了
120 setIndex(f, -1);
121 //最后将其返回出去
122 return f;
123 }
124
125 /**
126 * 第118行代码处:
127 * 方法参数中的key代表删除的最后一个节点中的任务
128 */
129 private void siftDown(int k, RunnableScheduledFuture<?> key) {
130 /*
131 这里会取数组长度的一半half(注意这里的size是已经删除最后一个节点后的size),
132 而half也就是在指向最后一个非叶子节点的下一个节点
133 */
134 int half = size >>> 1;
135 //从这里可以看出下溯的终止条件是k大于等于half,也就是此时遍历到已经没有了非叶子节点,自然不需要进行调整
136 while (k < half) {
137 //获取左孩子节点的索引位
138 int child = (k << 1) + 1;
139 //获取左孩子节点的任务
140 RunnableScheduledFuture<?> c = queue[child];
141 //获取右孩子节点的索引位
142 int right = child + 1;
143 //如果右孩子节点的索引位小于size,也就是在说当前节点含有右子树。并且左孩子节点的任务延迟时间大于右孩子节点的话
144 if (right < size && c.compareTo(queue[right]) > 0)
145 //就将c重新指向为右孩子节点
146 c = queue[child = right];
147 /*
148 走到这里说明c指向的是左右子节点中、任务延迟时间较小的那个节点。此时判断如果最后一个节点的
149 任务延迟时间小于等于这个较小节点的话,就可以停止下溯了,说明找到了插入的位置
150 */
151 if (key.compareTo(c) <= 0)
152 break;
153 //否则就把较小的那个节点赋值给当前节点处
154 queue[k] = c;
155 //同时设置一下延迟时间较小的那个节点的堆索引位为当前节点处
156 setIndex(c, k);
157 //然后将当前节点指向那个较小的节点,继续下一次循环
158 k = child;
159 }
160 /*
161 同siftUp方法一样,走到这里说明有两种情况:<1>已经结束了下溯的过程,但最后一次的子节点还没有赋值,
162 这里会把其赋值为之前删除的最后一个节点;
163 <2>如果根节点的左右子节点中、任务延迟时间较小的那个节点本身的延迟时间就比之前删除节点大的话,
164 就会把根节点替换为之前删除的最后一个节点
165 所以本方法加上finishPoll方法,实际上并没有将最后一个节点删除,最后一个节点中的任务一直都是保留着的
166 (也就是key),而是变相地将堆的根节点删除了(在第一种情况中根节点在第一次赋值为左右子节点中、
167 任务延迟时间较小的那个节点时,就已经被覆盖了)
168 */
169 queue[k] = key;
170 //同时设置一下最后一个节点现在新的堆索引位
171 setIndex(key, k);
172 }
8 执行延迟任务
拿取到任务之后,就是具体的执行任务了。addWorker方法具体的执行逻辑我在之前ThreadPoolExecutor的源码分析文章中已经讲过了,其中执行任务的时候会调用task的run方法,也就是这里包装为ScheduledFutureTask的run方法:
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 public void run() {
5 //判断是否是周期性任务
6 boolean periodic = isPeriodic();
7 if (!canRunInCurrentRunState(periodic)) {
8 //如果此时不能继续执行任务的话,就尝试取消此任务的执行
9 cancel(false);
10 } else if (!periodic)
11 /*
12 如果是延迟任务,就调用ScheduledFutureTask父类FutureTask的run方法,
13 其中会通过call方法来最终调用到使用者具体写的任务
14 */
15 ScheduledFutureTask.super.run();
16 else if (ScheduledFutureTask.super.runAndReset()) {
17 //周期性任务的执行放在下一节中进行分析
18 setNextRunTime();
19 reExecutePeriodic(outerTask);
20 }
21 }
9 scheduleAtFixedRate & scheduleWithFixedDelay方法
scheduleAtFixedRate方法是以上次的延迟时间点开始,延迟指定时间后再次执行当前任务;而scheduleWithFixedDelay方法是以上个周期任务执行完毕后的时间点开始,延迟指定时间后再次执行当前任务。因为这两个方法的实现绝大部分都是一样的,所以合在一起来进行分析:
1 /**
2 * ScheduledThreadPoolExecutor:
3 * scheduleAtFixedRate方法
4 */
5 public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
6 long initialDelay,
7 long period,
8 TimeUnit unit) {
9 //非空校验
10 if (command == null || unit == null)
11 throw new NullPointerException();
12 //非负校验
13 if (period <= 0)
14 throw new IllegalArgumentException();
15 //包装任务
16 ScheduledFutureTask<Void> sft =
17 new ScheduledFutureTask<Void>(command,
18 null,
19 triggerTime(initialDelay, unit),
20 unit.toNanos(period));
21 RunnableScheduledFuture<Void> t = decorateTask(command, sft);
22 //把任务赋值给ScheduledFutureTask的outerTask属性
23 sft.outerTask = t;
24 //延迟执行
25 delayedExecute(t);
26 return t;
27 }
28
29 /**
30 * scheduleWithFixedDelay方法
31 */
32 public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
33 long initialDelay,
34 long delay,
35 TimeUnit unit) {
36 //非空校验
37 if (command == null || unit == null)
38 throw new NullPointerException();
39 //非负校验
40 if (delay <= 0)
41 throw new IllegalArgumentException();
42 //包装任务
43 ScheduledFutureTask<Void> sft =
44 new ScheduledFutureTask<Void>(command,
45 null,
46 triggerTime(initialDelay, unit),
47 unit.toNanos(-delay));
48 RunnableScheduledFuture<Void> t = decorateTask(command, sft);
49 //把任务赋值给ScheduledFutureTask的outerTask属性
50 sft.outerTask = t;
51 //延迟执行
52 delayedExecute(t);
53 return t;
54 }
55
56 /**
57 * 第17行和第44行代码处:
58 */
59 ScheduledFutureTask(Runnable r, V result, long ns, long period) {
60 super(r, result);
61 this.time = ns;
62 /*
63 可以看到这里与schedule方法中调用ScheduledFutureTask构造器的区别是多了一个period入参
64 在schedule方法中this.period赋值为0,而这里会赋值为周期时间。其他的代码都是一样的
65 如果细心的话可以看出:在上面scheduleAtFixedRate方法传入的period是一个大于0的数,而
66 scheduleWithFixedDelay方法传入的period是一个小于0的数,以此来进行区分
67 */
68 this.period = period;
69 this.sequenceNumber = sequencer.getAndIncrement();
70 }
10 执行周期性任务
周期性任务和延迟任务的拿取任务逻辑都是一样的,而在下面具体运行任务时有所不同,下面就来看一下其实现的差异:
1 /**
2 * ScheduledThreadPoolExecutor:
3 */
4 public void run() {
5 boolean periodic = isPeriodic();
6 if (!canRunInCurrentRunState(periodic))
7 cancel(false);
8 else if (!periodic)
9 ScheduledFutureTask.super.run();
10 /*
11 前面都是之前分析过的,而周期性任务会走下面的分支中
12
13 FutureTask的runAndReset方法相比于run方法来说,区别在于可以重复计算(run方法不能复用)
14 因为runAndReset方法在计算完成后不会修改状态,状态一直都是NEW
15 */
16 else if (ScheduledFutureTask.super.runAndReset()) {
17 //设置下次的运行时间点
18 setNextRunTime();
19 //重新添加任务
20 reExecutePeriodic(outerTask);
21 }
22 }
23
24 /**
25 * 第18行代码处:
26 */
27 private void setNextRunTime() {
28 /*
29 这里会获取period,也就是之前设置的周期时间。上面说过,通过period的正负就可以区分出到底调用的是
30 scheduleAtFixedRate方法还是scheduleWithFixedDelay方法
31 */
32 long p = period;
33 if (p > 0)
34 /*
35 如果调用的是scheduleAtFixedRate方法,下一次的周期任务时间点就是起始的延迟时间加上周期时间,需要注意的是:
36 如果任务执行的时间大于周期时间period的话,那么定时线程池就不会按照原先设计的延迟时间进行执行,而是会按照近似于
37 任务执行的时间来作为延迟的间隔(不管核心线程有多少个都是如此,因为任务是放在延迟队列中的、是线性执行的)
38 */
39 time += p;
40 else
41 /*
42 triggerTime方法之前分析过是获取当前时间+延迟时间后的结果,而此时是在执行完任务后,也就是说:
43 如果调用的是scheduleWithFixedDelay方法,下一次的周期任务时间点就是执行完上次任务后的时间点加上周期时间
44 由此可以看出,scheduleAtFixedRate方法和scheduleWithFixedDelay方法的区别就在于下一次time设置的不同而已
45 */
46 time = triggerTime(-p);
47 //time属性会记录到节点中,在小顶堆中通过compareTo方法来进行排序
48 }
49
50 /**
51 * 第20行代码处:
52 */
53 void reExecutePeriodic(RunnableScheduledFuture<?> task) {
54 //判断此时是否还能继续执行任务
55 if (canRunInCurrentRunState(true)) {
56 /*
57 这里也就是重新往延迟队列中添加任务,以此达到周期执行的效果。添加之后在getTask方法中的take方法中
58 就又可以拿到这个任务。设置下次的执行时间,然后再添加任务...周而复始
59 */
60 super.getQueue().add(task);
61 //添加后继续判断此时是否还能继续执行任务,如果不能的话就删除上面添加的任务
62 if (!canRunInCurrentRunState(true) && remove(task))
63 //同时会取消此任务的执行
64 task.cancel(false);
65 else
66 //否则,说明线程池是可以继续执行任务的,就去判断此时是否需要补充工作线程
67 ensurePrestart();
68 }
69 }
注意:网上的一种说法是:scheduleAtFixedRate方法是以上一个任务开始的时间计时,period时间过去后,检测上一个任务是否执行完毕。如果上一个任务执行完毕,则当前任务立即执行;如果上一个任务没有执行完毕,则需要等上一个任务执行完毕后立即执行。实际上这种说法是错误的,尽管它的表象是对的。正确的说法是:如果任务的执行时间小于周期时间的话,则会以上次任务执行开始时间加上周期时间后,再去执行下一次任务;而如果任务的执行时间大于周期时间的话,则会等到上次任务执行完毕后立即(近似于)执行下次任务。这两种说法的区别就在于任务的执行时间大于周期时间的时候,检测上一个任务是否完毕的时机不同。实际上在period时间过去后,根本不会有任何的检测机制。因为只有等上次任务执行完毕后才会往延迟队列中添加下一次任务,从而触发各种后续的动作。所以在period时间点时,当前线程还在执行任务中,而其他的线程因为延迟队列中为空会处于休眠的状态(假如就只有一个周期任务的话)。所以根本不会有所谓的“检测”的说法,这种说法也只能说是想当然了。还是那句话:“Talk is cheap. Show me the code.”
既然都说到这里了,那么现在就想来尝试分析一下如果任务的执行时间大于周期时间的话,具体是怎样的一个执行流程?
为了便于分析,假设现在是只有一个周期任务的场景,那么延迟队列中的任务数量最多就只会有1个:拿取到任务,延迟队列中就变为空。执行完任务的时候,就又会往队列中放一个任务。这样其他抢不到任务的线程就会被休眠住。而添加任务的时候因为每次重新添加的任务都是小顶堆的根节点(从无到有),即添加的这个任务就是此时延迟时间最短的任务,所以同时会触发尝试唤醒线程的动作。
同时在添加下一个任务前会修改下一次的时间点。在setNextRunTime方法中,scheduleAtFixedRate方法是以上一次的延迟时间点加上周期时间来作为下一次的延迟时间点的,并不是scheduleWithFixedDelay方法获取当前时间加上周期时间的方式。在当前这种情况下周期时间是要小于任务的执行时间的,也就是说会造成下一次的延迟时间点会赋值为一个已经过期的时间。且随着周期的增加,下一次的延迟时间点会离当前时间点越来越远。既然下一次的延迟时间点已经过期了,那么就会去立马执行任务。
所以总结一下:需要被唤醒的线程和上次执行完任务的线程就会去争抢锁资源(唤醒线程会把当前节点放进CLH队列中,上次执行完任务的线程也会再次走到lockInterruptibly方法中(在它重新放任务的时候也会经历一次lock),同时因为是ReentrantLock非公平锁,这样在调用unlock解锁时就会出现在CLH队列上的抢资源现象了),抢到的就会立马去执行下一次的周期任务,而不会有任何的延时,造成的表象就是会以一个近似于任务执行时间为间隔的周期来执行任务。
11 shutdown方法
1 /**
2 * ScheduledThreadPoolExecutor:
3 * 可以看到,定时线程池的shutdown方法是使用的父类ThreadPoolExecutor的shutdown方法,
4 * 而该方法我在之前的ThreadPoolExecutor的源码分析文章中已经分析过了。但是其中会调用
5 * onShutdown的钩子方法,也就是在ScheduledThreadPoolExecutor中的实现
6 */
7 public void shutdown() {
8 super.shutdown();
9 }
10
11 @Override
12 void onShutdown() {
13 //获取延迟队列
14 BlockingQueue<Runnable> q = super.getQueue();
15 //关闭线程池时判断是否需要继续执行延迟任务
16 boolean keepDelayed =
17 getExecuteExistingDelayedTasksAfterShutdownPolicy();
18 //关闭线程池时判断是否需要继续执行周期性任务
19 boolean keepPeriodic =
20 getContinueExistingPeriodicTasksAfterShutdownPolicy();
21 if (!keepDelayed && !keepPeriodic) {
22 //如果都不需要的话,就将延迟队列中的任务逐个取消(并删除)
23 for (Object e : q.toArray())
24 if (e instanceof RunnableScheduledFuture<?>)
25 ((RunnableScheduledFuture<?>) e).cancel(false);
26 //最后做清理工作
27 q.clear();
28 } else {
29 for (Object e : q.toArray()) {
30 if (e instanceof RunnableScheduledFuture) {
31 //否则就判断如果任务是RunnableScheduledFuture类型的,就强转一下类型
32 RunnableScheduledFuture<?> t =
33 (RunnableScheduledFuture<?>) e;
34 //如果关闭线程池时不需要继续执行任务,又或者需要继续执行但是任务已经取消了
35 if ((t.isPeriodic() ? !keepPeriodic : !keepDelayed) ||
36 t.isCancelled()) {
37 //就删除当前节点
38 if (q.remove(t))
39 //同时取消任务
40 t.cancel(false);
41 }
42 }
43 }
44 }
45 //根据线程池状态来判断是否应该结束线程池
46 tryTerminate();
47 }
48
49 /**
50 * 第27行代码处:
51 */
52 public void clear() {
53 final ReentrantLock lock = this.lock;
54 //加锁
55 lock.lock();
56 try {
57 for (int i = 0; i < size; i++) {
58 //遍历获得延迟队列中的每一个节点
59 RunnableScheduledFuture<?> t = queue[i];
60 if (t != null) {
61 //将节点置为null
62 queue[i] = null;
63 //同时将索引位置为-1(recheck)
64 setIndex(t, -1);
65 }
66 }
67 //size赋为初始值0
68 size = 0;
69 } finally {
70 //释放锁
71 lock.unlock();
72 }
73 }
更多内容请关注微信公众号:奇客时间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号