Spring源码分析之循环依赖及解决方案
Spring源码分析之循环依赖及解决方案
往期文章:
- Spring源码分析之预启动流程
- Spring源码分析之BeanFactory体系结构
- Spring源码分析之BeanFactoryPostProcessor调用过程详解
- Spring源码分析之Bean的创建过程详解
正文:
首先,我们需要明白什么是循环依赖?简单来说就是A对象创建过程中需要依赖B对象,而B对象创建过程中同样也需要A对象,所以A创建时需要先去把B创建出来,但B创建时又要先把A创建出来...死循环有木有...
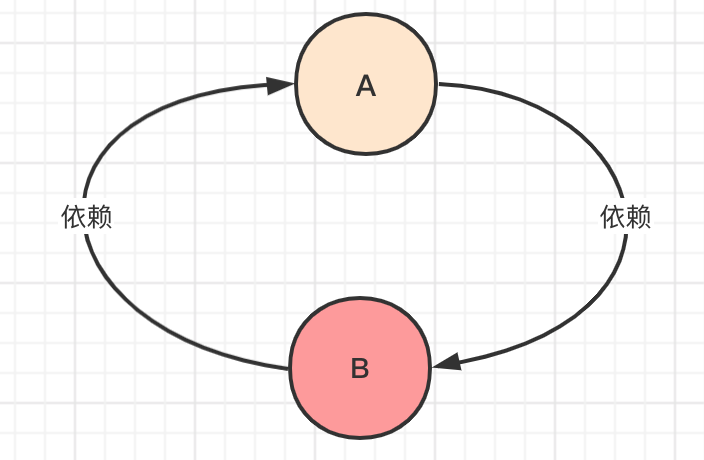
那么在Spring中,有多少种循环依赖的情况呢?大部分人只知道两个普通的Bean之间的循环依赖,而Spring中其实存在三种对象(普通Bean,工厂Bean,代理对象),他们之间都会存在循环依赖,这里我给列举出来,大致分别以下几种:
- 普通Bean与普通Bean之间
- 普通Bean与代理对象之间
- 代理对象与代理对象之间
- 普通Bean与工厂Bean之间
- 工厂Bean与工厂Bean之间
- 工厂Bean与代理对象之间
那么,在Spring中是如何解决这个问题的呢?
1. 普通Bean与普通Bean
首先,我们先设想一下,如果让我们自己来编码,我们会如何解决这个问题?
栗子
现在我们有两个互相依赖的对象A和B
public class NormalBeanA {
private NormalBeanB normalBeanB;
public void setNormalBeanB(NormalBeanB normalBeanB) {
this.normalBeanB = normalBeanB;
}
}
public class NormalBeanB {
private NormalBeanA normalBeanA;
public void setNormalBeanA(NormalBeanA normalBeanA) {
this.normalBeanA = normalBeanA;
}
}
然后我们想要让他们彼此都含有对象
public class Main {
public static void main(String[] args) {
// 先创建A对象
NormalBeanA normalBeanA = new NormalBeanA();
// 创建B对象
NormalBeanB normalBeanB = new NormalBeanB();
// 将A对象的引用赋给B
normalBeanB.setNormalBeanA(normalBeanA);
// 再将B赋给A
normalBeanA.setNormalBeanB(normalBeanB);
}
}
发现了吗?我们并没有先创建一个完整的A对象,而是先创建了一个空壳对象(Spring中称为早期对象),将这个早期对象A先赋给了B,使得得到了一个完整的B对象,再将这个完整的B对象赋给A,从而解决了这个循环依赖问题,so easy!
那么Spring中是不是也这样做的呢?我们就来看看吧~
Spring中的解决方案
由于上一篇已经分析过Bean的创建过程了,其中的某些部分就不再细讲了
先来到创建Bean的方法
AbstractAutowireCapableBeanFactory#doCreateBean
假设此时在创建A
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args){
// beanName -> A
// 实例化A
BeanWrapper instanceWrapper = createBeanInstance(beanName, mbd, args);
// 是否允许暴露早期对象
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// 将获取早期对象的回调方法放到三级缓存中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
}
addSingletonFactory
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
// 单例缓存池中没有该Bean
if (!this.singletonObjects.containsKey(beanName)) {
// 将回调函数放入三级缓存
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
ObjectFactory是一个函数式接口
在这里,我们发现在创建Bean时,Spring不管三七二十一,直接将一个获取早期对象的回调方法放进了一个三级缓存中,我们再来看一下回调方法的逻辑
getEarlyBeanReference
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
// 调用BeanPostProcessor对早期对象进行处理,在Spring的内置处理器中,并无相关的处理逻辑
// 如果开启了AOP,将引入一个AnnotationAwareAspectJAutoProxyCreator,此时将可能对Bean进行动态代理
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
在这里,如果没有开启AOP,或者该对象不需要动态代理,会直接返回原对象
此时,已经将A的早期对象缓存起来了,接下来在填充属性时会发生什么呢?
相信大家也应该想到了,A对象填充属性时必然发现依赖了B对象,此时就将转头创建B,在创建B时同样会经历以上步骤,此时就该B对象填充属性了,这时,又将要转头创建A,那么,现在会有什么不一样的地方呢?我们看看getBean的逻辑吧
doGetBean
protected <T> T doGetBean(
String name, @Nullable Class<T> requiredType, @Nullable Object[] args, boolean typeCheckOnly){
// 此时beanName为A
String beanName = transformedBeanName(name);
// 尝试从三级缓存中获取bean,这里很关键
Object sharedInstance = getSingleton(beanName);
}
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从单例缓存池中获取,此时仍然是取不到的
Object singletonObject = this.singletonObjects.get(beanName);
// 获取不到,判断bean是否正在创建,没错,此时A确实正在创建
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 由于现在仍然是在同一个线程,基于同步锁的可重入性,此时不会阻塞
synchronized (this.singletonObjects) {
// 从早期对象缓存池中获取,这里是没有的
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 从三级缓存中获取回调函数,此时就获取到了我们在创建A时放入的回调函数
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 调用回调方法获取早期bean,由于我们现在讨论的是普通对象,所以返回原对象
singletonObject = singletonFactory.getObject();
// 将早期对象放到二级缓存,移除三级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
// 返回早期对象A
return singletonObject;
}
震惊!此时我们就拿到了A的早期对象进行返回,所以B得以被填充属性,B创建完毕后,又将返回到A填充属性的过程,A也得以被填充属性,A也创建完毕,这时,A和B都创建好了,循环依赖问题得以收场~
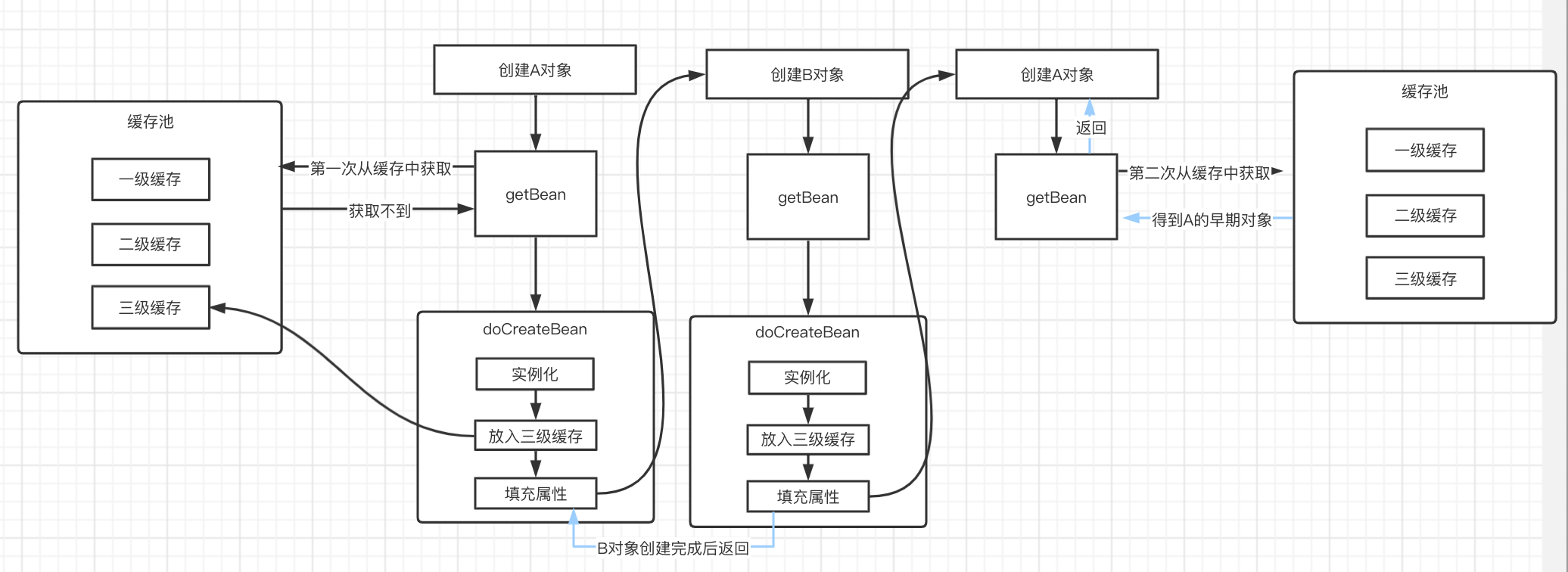
普通Bean和普通Bean之间的问题就到这里了,不知道小伙伴们有没有晕呢~
2. 普通Bean和代理对象
普通Bean和代理对象之间的循环依赖与两个普通Bean的循环依赖其实大致相同,只不过是多了一次动态代理的过程,我们假设A对象是需要代理的对象,B对象仍然是一个普通对象,然后,我们开始创建A对象。
刚开始创建A的过程与上面的例子是一模一样的,紧接着自然是需要创建B,然后B依赖了A,于是又倒回去创建A,此时,再次走到去缓存池获取的过程。
// 从三级缓存中获取回调函数
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 调用回调方法获取早期bean,此时返回的是一个A的代理对象
singletonObject = singletonFactory.getObject();
// 将早期对象放到二级缓存,移除三级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
这时就不太一样了,在singletonFactory.getObject()时,由于此时A是需要代理的对象,在调用回调函数时,就会触发动态代理的过程
AbstractAutoProxyCreator#getEarlyBeanReference
public Object getEarlyBeanReference(Object bean, String beanName) {
// 生成一个缓存Key
Object cacheKey = getCacheKey(bean.getClass(), beanName);
// 放入缓存中,用于在初始化后调用该后置处理器时判断是否进行动态代理过
this.earlyProxyReferences.put(cacheKey, bean);
// 将对象进行动态代理
return wrapIfNecessary(bean, beanName, cacheKey);
}
此时,B在创建时填充的属性就是A的代理对象了,B创建完毕,返回到A的创建过程,但此时的A仍然是一个普通对象,可B引用的A已经是个代理对象了,不知道小伙伴看到这里有没有迷惑呢?
不急,让我们继续往下走,填充完属性自然是需要初始化的,在初始化后,会调用一次后置处理器,我们看看会不会有答案吧
初始化
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {
//...省略前面的步骤...
// 调用初始化方法
invokeInitMethods(beanName, wrappedBean, mbd);
// 处理初始化后的bean
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
在处理初始化后的bean,又会调用动态代理的后置处理器了
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
// 判断缓存中是否有该对象,有则说明该对象已被动态代理,跳过
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
return bean;
}
不知道小伙伴发现没有,earlyProxyReferences这个缓存可不就是我们在填充B的属性,进而从缓存中获取A时放进去的吗?不信您往上翻到getEarlyBeanReference的步骤看看~
所以,此时并未进行任何处理,依旧返回了我们的原对象A,看来这里并没有我们要的答案,那就继续吧~
// 是否允许暴露早期对象
if (earlySingletonExposure) {
// 从缓存池中获取早期对象
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
// bean为初始化前的对象,exposedObject为初始化后的对象
// 判断两对象是否相等,基于上面的分析,这两者是相等的
if (exposedObject == bean) {
// 将早期对象赋给exposedObject
exposedObject = earlySingletonReference;
}
}
}
我们来分析一下上面的逻辑,getSingleton从缓存池中获取早期对象返回的是什么呢?
synchronized (this.singletonObjects) {
// 从早期对象缓存池中获取,此时就拿到了我们填充B属性时放入的A的代理对象
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 从三级缓存中获取回调函数
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 调用回调方法获取早期bean
singletonObject = singletonFactory.getObject();
// 将早期对象放到二级缓存,移除三级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
发现了吗?此时我们就获取到了A的代理对象,然后我们又把这个对象赋给了exposedObject,此时创建对象的流程走完,我们得到的A不就是个代理对象了吗~
此次栗子是先创建需要代理的对象A,假设我们先创建普通对象B会发生什么呢?
3. 代理对象与代理对象
代理对象与代理对象的循环依赖是怎么样的呢?解决过程又是如何呢?这里就留给小伙伴自己思考了,其实和普通Bean与代理对象是一模一样的,小伙伴想想是不是呢,这里我就不做分析了。
4. 普通Bean与工厂Bean
这里所说的普通Bean与工厂Bean并非指bean与FactoryBean,这将毫无意义,而是指普通Bean与FactoryBean的getObject方法产生了循环依赖,因为FactoryBean最终产生的对象是由getObject方法所产出。我们先来看看栗子吧~
假设工厂对象A依赖普通对象B,普通对象B依赖普通对象A。
小伙伴看到这里就可能问了,诶~你这不对呀,怎么成了「普通对象B依赖普通对象A」呢?不应该是工厂对象A吗?是这样的,在Spring中,由于普通对象A是由工厂对象A产生,所有在普通对象B想要获取普通对象A时,其实最终寻找调用的是工厂对象A的getObject方法,所以只要普通对象B依赖普通对象A就可以了,Spring会自动帮我们把普通对象B和工厂对象A联系在一起。
小伙伴,哦~
普通对象A
public class NormalBeanA {
private NormalBeanB normalBeanB;
public void setNormalBeanB(NormalBeanB normalBeanB) {
this.normalBeanB = normalBeanB;
}
}
工厂对象A
@Component
public class FactoryBeanA implements FactoryBean<NormalBeanA> {
@Autowired
private ApplicationContext context;
@Override
public NormalBeanA getObject() throws Exception {
NormalBeanA normalBeanA = new NormalBeanA();
NormalBeanB normalBeanB = context.getBean("normalBeanB", NormalBeanB.class);
normalBeanA.setNormalBeanB(normalBeanB);
return normalBeanA;
}
@Override
public Class<?> getObjectType() {
return NormalBeanA.class;
}
}
普通对象B
@Component
public class NormalBeanB {
@Autowired
private NormalBeanA normalBeanA;
}
假设我们先创建对象A
由于FactoryBean和Bean的创建过程是一样的,只是多了步getObject,所以我们直接定位到调用getObject入口
if (mbd.isSingleton()) {
// 开始创建bean
sharedInstance = getSingleton(beanName, () -> {
// 创建bean
return createBean(beanName, mbd, args);
});
// 处理FactoryBean
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
protected Object getObjectForBeanInstance(
Object beanInstance, String name, String beanName, @Nullable RootBeanDefinition mbd) {
// 先尝试从缓存中获取,保证多次从工厂bean获取的bean是同一个bean
object = getCachedObjectForFactoryBean(beanName);
if (object == null) {
// 从FactoryBean获取对象
object = getObjectFromFactoryBean(factory, beanName, !synthetic);
}
}
protected Object getObjectFromFactoryBean(FactoryBean<?> factory, String beanName, boolean shouldPostProcess) {
// 加锁,防止多线程时重复创建bean
synchronized (getSingletonMutex()) {
// 这里是Double Check
Object object = this.factoryBeanObjectCache.get(beanName);
if (object == null) {
// 获取bean,调用factoryBean的getObject()
object = doGetObjectFromFactoryBean(factory, beanName);
}
// 又从缓存中取了一次,why? 我们慢慢分析
Object alreadyThere = this.factoryBeanObjectCache.get(beanName);
if (alreadyThere != null) {
object = alreadyThere;
}else{
// ...省略初始化bean的逻辑...
// 将获取到的bean放入缓存
this.factoryBeanObjectCache.put(beanName, object);
}
}
}
private Object doGetObjectFromFactoryBean(FactoryBean<?> factory, String beanName){
return factory.getObject();
}
现在,就走到了我们自定义的getObject方法,由于我们调用了context.getBean("normalBeanB", NormalBeanB.class),此时,将会去创建B对象,在创建过程中,先将B的早期对象放入三级缓存,紧接着填充属性,发现依赖了A对象,又要倒回来创建A对象,从而又回到上面的逻辑,再次调用我们自定义的getObject方法,这个时候会发生什么呢?
又要去创建B对象...(Spring:心好累)
但是!此时我们在创建B时,是直接通过getBean在缓存中获取到了B的早期对象,得以返回了!于是我们自定义的getObject调用成功,返回了一个完整的A对象!
但是此时FactoryBean的缓冲中还是什么都没有的。
// 又从缓存中取了一次
Object alreadyThere = this.factoryBeanObjectCache.get(beanName);
if (alreadyThere != null) {
object = alreadyThere;
}
这一次取alreadyThere必然是null,流程继续执行,将此时将获取到的bean放入缓存
this.factoryBeanObjectCache.put(beanName, object);
从FactoryBean获取对象的流程结束,返回到创建B的过程中,B对象此时的属性也得以填充,再返回到第一次创建A的过程,也就是我们第一次调用自定义的getObject方法,调用完毕,返回到这里
// 获取bean,调用factoryBean的getObject()
object = doGetObjectFromFactoryBean(factory, beanName);
Object alreadyThere = this.factoryBeanObjectCache.get(beanName);
if (alreadyThere != null) {
object = alreadyThere;
那么,此时this.factoryBeanObjectCache.get(beanName)能从缓冲中拿到对象了吗?有没有发现,拿到了刚刚B对象填充属性时再次创建A对象放进去的!
所以,明白这里为什么要再次从缓存中获取了吧?就是为了解决由于循环依赖时调用了两次自定义的getObject方法,从而创建了两个不相同的A对象,保证我们返回出去的A对象唯一!
怕小伙伴晕了,画个图给大家
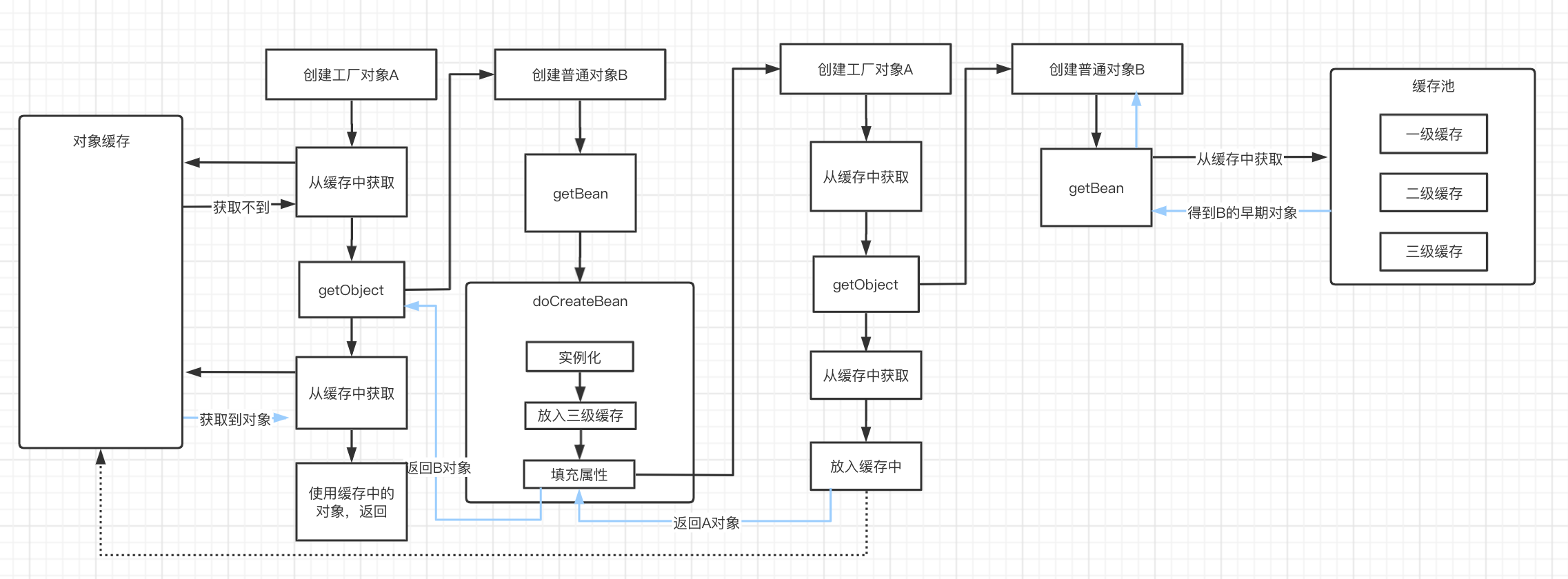
5. 工厂Bean与工厂Bean之间
我们已经举例4种循环依赖的栗子,Spring都有所解决,那么有没有Spring也无法解决的循环依赖问题呢?
有的!就是这个FactoryBean与FactoryBean的循环依赖!
假设工厂对象A依赖工厂对象B,工厂对象B依赖工厂对象A,那么,这次的栗子会是什么样呢?
普通对象
public class NormalBeanA {
private NormalBeanB normalBeanB;
public void setNormalBeanB(NormalBeanB normalBeanB) {
this.normalBeanB = normalBeanB;
}
}
public class NormalBeanB {
private NormalBeanA normalBeanA;
public void setNormalBeanA(NormalBeanA normalBeanA) {
this.normalBeanA = normalBeanA;
}
}
工厂对象
@Component
public class FactoryBeanA implements FactoryBean<NormalBeanA> {
@Autowired
private ApplicationContext context;
@Override
public NormalBeanA getObject() throws Exception {
NormalBeanA normalBeanA = new NormalBeanA();
NormalBeanB normalBeanB = context.getBean("factoryBeanB", NormalBeanB.class);
normalBeanA.setNormalBeanB(normalBeanB);
return normalBeanA;
}
@Override
public Class<?> getObjectType() {
return NormalBeanA.class;
}
}
@Component
public class FactoryBeanB implements FactoryBean<NormalBeanB> {
@Autowired
private ApplicationContext context;
@Override
public NormalBeanB getObject() throws Exception {
NormalBeanB normalBeanB = new NormalBeanB();
NormalBeanA normalBeanA = context.getBean("factoryBeanA", NormalBeanA.class);
normalBeanB.setNormalBeanA(normalBeanA);
return normalBeanB;
}
@Override
public Class<?> getObjectType() {
return NormalBeanB.class;
}
}
首先,我们开始创建对象A,此时为调用工厂对象A的getObject方法,转而去获取对象B,便会走到工厂对象B的getObject方法,然后又去获取对象A,又将调用工厂对象A的getObject,再次去获取对象B,于是再次走到工厂对象B的getObject方法......此时,已经历了一轮循环,却没有跳出循环的迹象,妥妥的死循环了。
我们画个图吧~
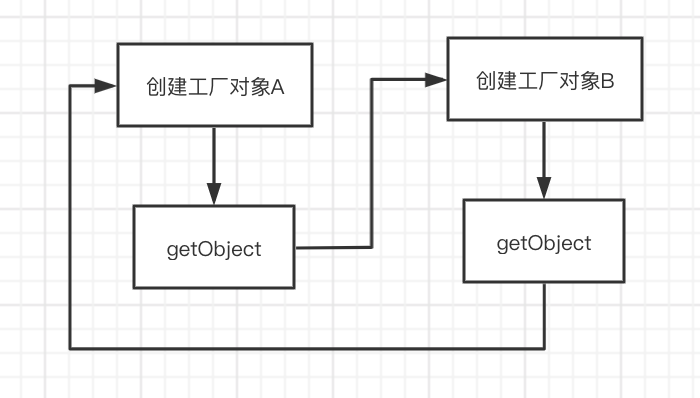
没错!这个图就是这么简单,由于始终无法创建出一个对象,不管是早期对象或者完整对象,使得两个工厂对象反复的去获取对方,导致陷入了死循环。
那么,我们是否有办法解决这个问题呢?
我的答案是无法解决,如果有想法的小伙伴也可以自己想一想哦~
我们发现,在发生循环依赖时,只要循环链中的某一个点可以先创建出一个早期对象,那么在下一次循环时,就会使得我们能够获取到早期对象从而跳出循环!
而由于工厂对象与工厂对象间是无法创建出这个早期对象的,无法满足跳出循环的条件,导致变成了死循环。
那么此时Spring中会抛出一个什么样的异常呢?
当然是栈溢出异常啦!两个工厂对象一直相互调用,不断开辟栈帧,可不就是栈溢出有木有~
6. 工厂对象与代理对象
上面的情况是无法解决循环依赖的,那么这个情况可以解决吗?
答案是可以的!
我们分析了,一个循环链是否能够得到终止,关键在于是否能够在某个点创建出一个早期对象(临时对象),而代理对象在doCreateBean时,是会生成一个早期对象放入三级缓存的,于是该循环链得以终结。
具体过程我这里就不再细分析了,就交由小伙伴自己动手吧~
总结
以上我们一共举例了6种情况,通过分析,总结出这样一条定律:
在发生循环依赖时,判断一个循环链是否能够得到终止,关键在于是否能够在某个点创建出一个早期对象(临时对象),那么在下一次循环时,我们就能通过该早期对象进而跳出(打破)循环!
通过这样的定律,我们得出工厂Bean与工厂Bean之间是无法解决循环依赖的,那么还有其他情况无法解决循环依赖吗?
有的!以上的例子举的都是单例的对象,并且都是通过set方法形成的循环依赖。
假使我们是由于构造方法形成的循环依赖呢?是否有解决办法吗?
没有,因为这并不满足我们得出的定律
无法执行完毕构造方法,自然无法创建出一个早期对象。
假使我们的对象是多例的呢?
也不能,因为多例的对象在每次创建时都是创建新的对象,即使能够创建出早期对象,也不能为下一次循环所用!
好了,本文就到这里结束了,希望小伙伴们有所收获~
Spring IOC的核心部分到此篇就结束了,下一篇就让我们进行AOP之旅吧~
下文预告:Spring源码分析之AOP从解析到调用
Spring 源码系列
- Spring源码分析之 IOC 容器预启动流程(已完结)
- Spring源码分析之BeanFactory体系结构(已完结)
- Spring源码分析之BeanFactoryPostProcessor调用过程(已完结)
- Spring源码分析之Bean的创建过程(已完结)
- Spring源码分析之什么是循环依赖及解决方案
- Spring源码分析之AOP从解析到调用
- Spring源码分析之事务管理(上),事物管理是spring作为容器的一个特点,总结一下他的基本实现与原理吧
- Spring源码分析之事务管理(下) ,关于他的底层事物隔离与事物传播原理,重点分析一下
Spring Mvc 源码系列
- SpringMvc体系结构
- SpringMvc源码分析之Handler解析过程
- SpringMvc源码分析之请求链过程
另外笔者公众号:奇客时间,有更多精彩的文章,有兴趣的同学,可以关注

 浙公网安备 33010602011771号
浙公网安备 33010602011771号