
浅谈Hbase
Hbase的基本特性:
(1)半结构化存储,利于水平扩展;
(2)根据rowkey,column family,column qualifier,timestamp四个维度进行数据检索;
(3)无模式数据库,无需提前指定列,只需指定column family;
(4)无数据类型,数据均按照Bytes格式进行存储;
(5)Get,Put,Scan,Delete和Increment是五种基本的操作方式,Get基于rowkey查询,Scan基于过滤器查询。
Hbase针对PB,TB级存储,亿级行数据的海量表记录的高并发,Hbase在物理架构方面设计成一个依赖Hadoop HDFS的全分布式的存储集群,并基于Hadoop的MapReduce网络计算框架,用以支持高吞吐量的数据访问,支持可用性和可靠性。
Hbase先有column family,后有列。列是动态生成的,而column family是在定义阶段需要生成的。create ‘test’,'cf' 创建test表以及cf列簇。只要有列存在,则该行必然存在。如果该行所有列均为null,也就是该行没有列,那么该行不存在,resultScanner也不会扫描到该行。相反,如果该行至少有一列不为null,resultScanner会遍历到该行。这一行有或者没有这个列,是动态的,每个行的列都可以不一样。所以hbase是稀疏的。
Hbase过滤器:
用户创建Hbase过滤器之后,被序列化为网络传输的格式,分发到各个RegionServer。在RegionServer中Filter被还原出来。
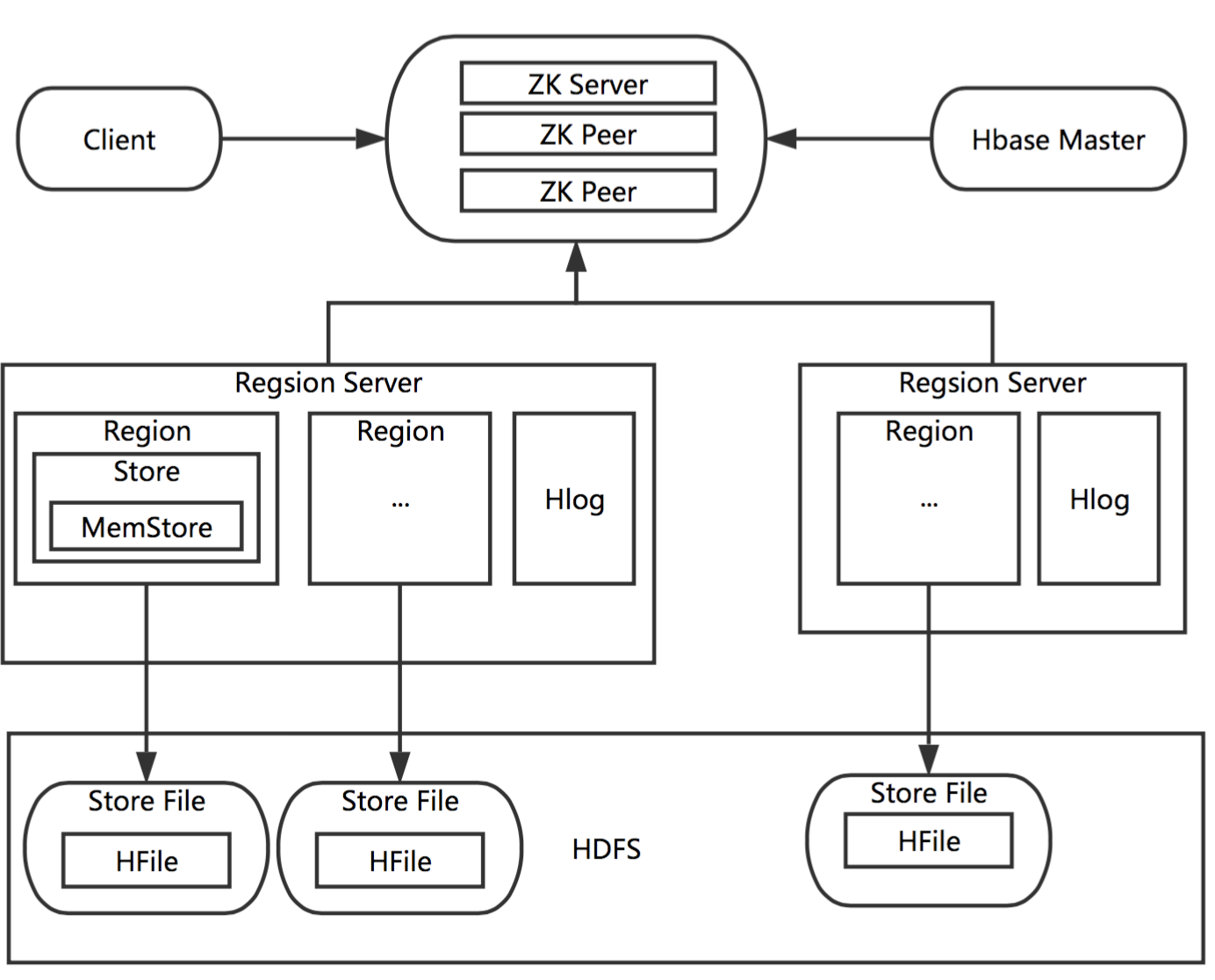
Hbase原理:
1个RegionServer管理多个Region;1个Region对应多个Store对象;1个Store对象对应1个MemStore和1至多个HFile。MemStore是数据在内存中的实体。对于Hbase,Region是数据并行化的基本单元,数据也是存储在Region中的。数据写入Store时,会先写入MemStore。当MemStore中的数据需要向底层文件倾倒时,Store会创建Store File(HFile)的一层封装。
文中大部分内容均转载自:https://developer.ibm.com/zh/articles/ba-cn-bigdata-hbase/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号