Python 基础第七天
今日主要内容:
1.数据类型补充
2.集合set和用法
3.深浅copy
4.编码的补充
1.数据类型的补充
tuple(元组)
1)元组内如果只有一个元素,并且没有逗号,此元素是什么数据类型,该表达式就是什么类型.
例:
tu = (1)
tu1 = (1,)
print(tu,type(tu))
print(tu1,type(tu1))
tu = ('老男孩')
tu1 = ('老男孩',)
print(tu,type(tu))
print(tu1,type(tu1))
tu = ([1,2,3])
tu1 = ([1,2,3],)
print(tu,type(tu))
print(tu1,type(tu1))
2)list(列表)
在循环一个列表时,最好不要进行删除的动作(一旦删除,索引会随之改变),容易出错。
例:
li = [11,22,33,44,55] 将索引为奇数的元素删除。
法一:
del li[1::2]
print(li)
法二:
for i in range(len(li)-1,-1,-1): #倒叙删除,使用步长(起始点,终点,步长)
if i % 2 == 1:
del li[i]
print(li)
解释:由于for从后向前遍历,当删除操作进行的时候,删除的是从后开始的奇数,所以不影响正序的索引.
法三:
l1 = []
for i in li:
if li.index(i) % 2 == 0:
l1.append(i)
li = l1
print(li)
dict(字典)
1)新方法:fromkeys:创建新字典,前面列的是key,后面是values
例:
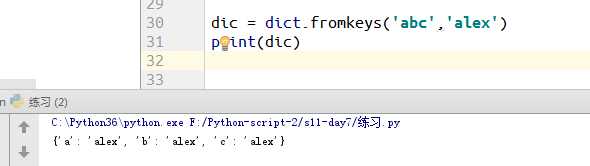
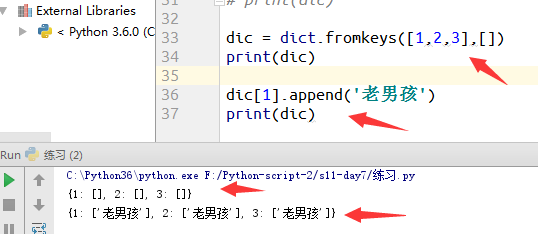
例2:如果values是空列表,则出现如下现象:
为了节省内存空间,所创建的空列表公用一个内存地址.
例题:
dic = {'k1':'value1','k2':'value2','name':'wusir'}
将字典中含有k元素的键,对应的键值对删除。
for i in dic:
if 'k' in i:
del dic[i]
报错:IndentationError: expected an indented block
结论:
在循环字典中,不能增加或者删除此字典的键值对。如果需要删除此键值对需要跳出此字典的循环,方法如下:
l1 = []
for i in dic:
if 'k' in i:
l1.append(i)
for i in l1:
del dic[i]
print(dic)
解析:先循环找到要删除的K值,然后把这些值放到空列表中,在循环该列表,用删除key的方法,删除键值对.
数据转换
list --> tuple
l1 = [1,2,3]
tu1 = tuple(l1)
print(tu1)
tuple ---> list
tu = (1,2,3)
li = list(tu)
print(li)
元组转换字符串
tuple ---> str
tu = ('wusir','老男孩')
s = " ".join(tu)
print(s)
2.集合(set)和用法
什么是集合:是一些不重复,无序的可哈希的数据构成,本是是不可哈希的,不能作为字典的key使用.
作用:
1.进行元素去重
2.数据关系的测试(计算交集/并集/差集)
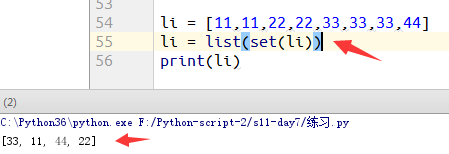
1)去重
例1.给列表出重
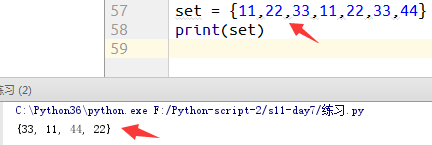
例2.本是有重复元素,输出时全部去重
集合的增加:
1.无序增加(add)
例3:对比是否无序增加
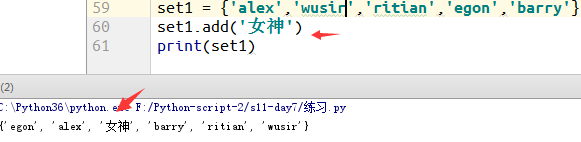
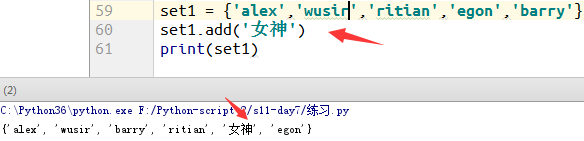
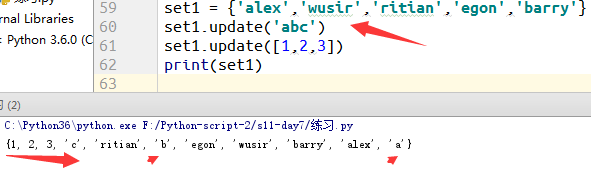
2.迭代增加 (update)
例4:展示迭代增加的现象
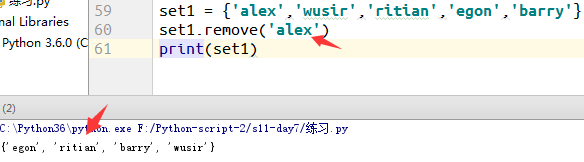
集合的删除
1.根据集合内元素名称删除(remove)
例5:
2.随机删除,能有返回值(pop)
例6:对比查看是否为随机


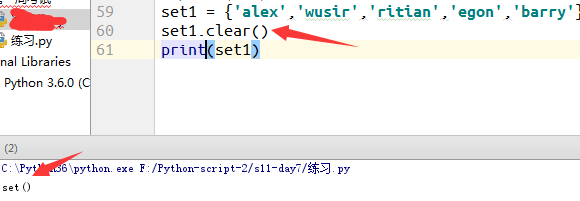
3.清空集合(set)
例7:
4.删除集合(del)
例8:

查看元素
1.只能使用for循环,遍历集合
例9:

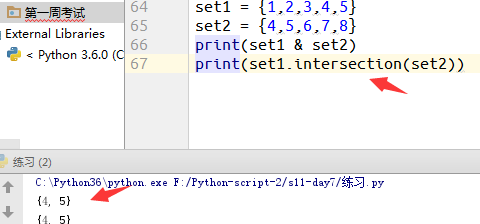
4.显示交集(&/intersection) (表示有多少相同元素)
例10:
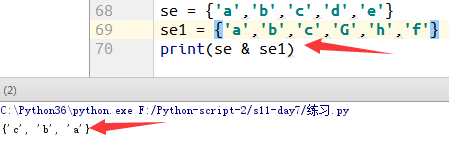
字符串同样适用:
se = {'alex'}
se1 = {'jason'}
print(se & se1) #此种形式不适用
例11:
5.显示反交集(^ /symmetric_difference)(表示有多少不同元素)
例12:

6.显示并集(|/unico)(合并两个集合,显示合并后的集合,重复的去重.)
例13:

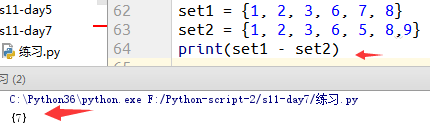
7.显示差集(-)(两个集合的差,第一个集合减去第二个集合重复的元素,第一个集合剩下的元素)
例14:
8.子集和超集(issubset)
例15:

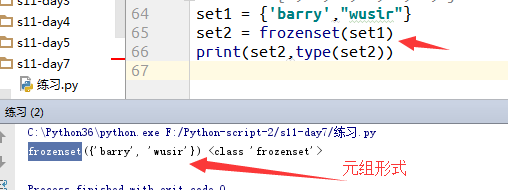
8.将集合set转化成不可变的集合frozenset
转化之后集合元素固定,只能通过for查看,并且可以作为字典的key,也可以作为其他集合的元素
例:16
深浅copy
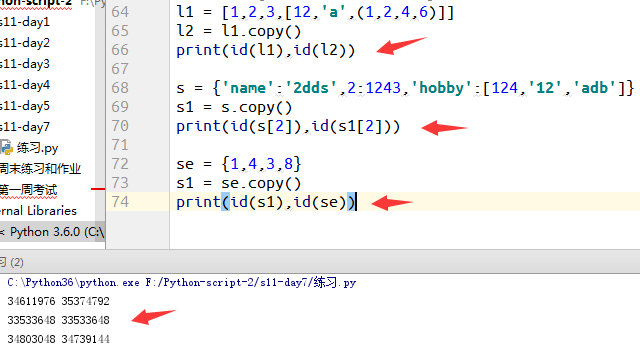
1.元素赋值,浅copy,深copy的关系
赋值:对于赋值运算,指向的是同一个内存地址。字典,列表,集合都一样。(a = b)
浅copy:最外层列表内存地址已经发生变化,单独开辟了内存空间,内存的嵌套的列表还是公用一个.(同样适用于字典,集合,元组不可用)
即,对于第二层或者更深层来说是不变的.(li.copy())
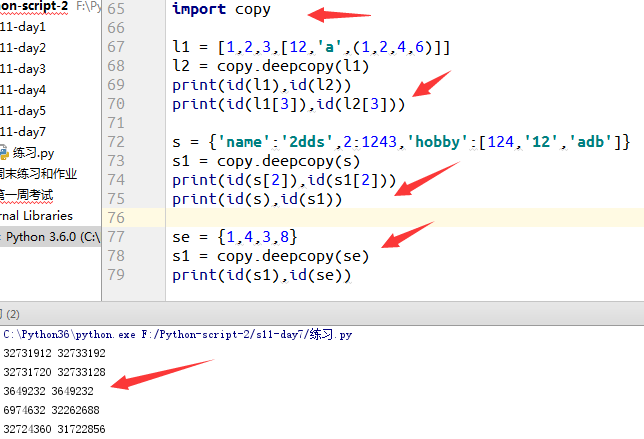
深copy:对于深copy来说操作后这是两个完全独立,改变任意一层都不会对另外一个产生影响.(
import copy
copy.deepcopy)
判断是赋值还是浅copy的方法:
li = [1,'2','abd',['e',123,'34a']]
l1 = li[:]
l1.append(666 )
print(l1)
问l1是否增加元素
确定方法:
1.只要l1 = li(有任何对原数据进行操作的过程都是相当于重新新建了一个列表,比如切片,步长都是如此)
2.如果是赋值的话,应该是两边都是定义的一个变量名称.不涉及到对原数据进行操作.
========================================================================================
2.浅copy的操作
例:三种类型的浅copy实验:
例2:深copy实验,进行验证
编码的补充(python3最后一部分)
回顾一下,str与bytes之间的相互转化:
英文:
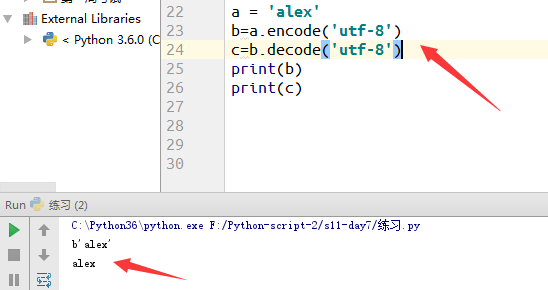
汉字:

如果想把str 的(gbk)编码转换成(utf-8)编码如何操作
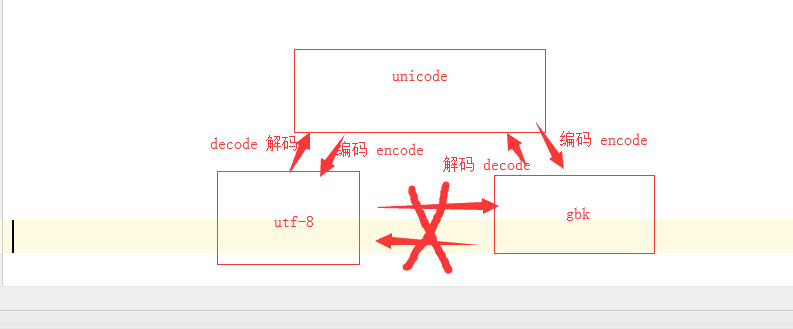
结论:如果需要转换,需要先转换到Unicode,再分别进行转换即可.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号