hadoop完全分布式
安装部署需要机器
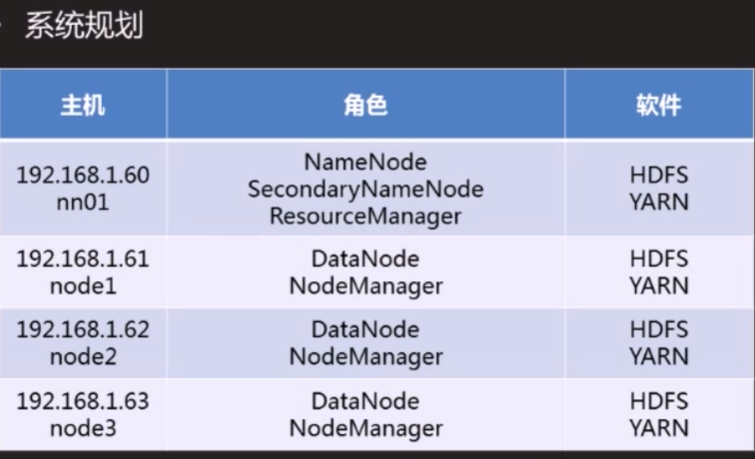
HDFS完成分布式系统配置
—环境配置文件:hadoop-env.sh (这个配置参考上篇文章)
—核心配置文件:core-site.xml
—HDFS配置文件:hdfs-site.xml
—节点配置文件:slaver
可以参考官网配置文件我使用的是2.7的hadoop:https://hadoop.apache.org/docs/r2.7.7/

XML默认格式(参考)
<property>
<name>关键字</name>
<value>变量值</value>
<description>描述</description>
</property>
核心配置文件 core-site.xml
—fs.defaultFS:文件系统配置参数
—hadoop.tmp.dir:数据目录配置参数
[root@nn01 hadoop]# vim core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://nn01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 (一般是给一个存储硬盘暂时存储到/var/hadoop)-->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop</value>
</property>
</configuration>
核心配置文件hdfs-site.xml(参考)
—Namenode:地址声明
dfs.namenode.http-address
—Secondarynamenode:地址声明
—文件冗余份数
dfs.replication
[root@nn01 hadoop]# vim hdfs-site.xml
<configuration>
<!--namenode的地址-->
<property>
<name>dfs.namenode.https-address</name>
<value>nn01:50470</value>
</property>
<!--secondary namenode的地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>nn01:50090</value>
</property>
<!--数据冗余数存储2份 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
节点配置文件slaves
只写DataNde节点的主机名称
node1
node2
node3
同步配置
hadoop所有节点的配置参数完成一样,在一台配置好后。把配置文件同步到其他所有主机上
slaves文件里的localhost必须删除文件配置如下
[root@nn01 hadoop]# vim slaves
node1
node2
node3
[root@nn01 hadoop]# for i in node{1..3};do rsync -aXSH --delete /usr/local/hadoop/ ${i}:/usr/local/hadoop & done
[root@nn01 hadoop]# wait
HDFS完全分布式配置
在本机创建/var/hadoop文件配置hadoop运行时产生文件的存储目录
# mkdir /var/hadoop
在namenode上执行格式化操作
#./bin/hdfs namenode -format
启动集群
#./sbin/start-dfs.sh
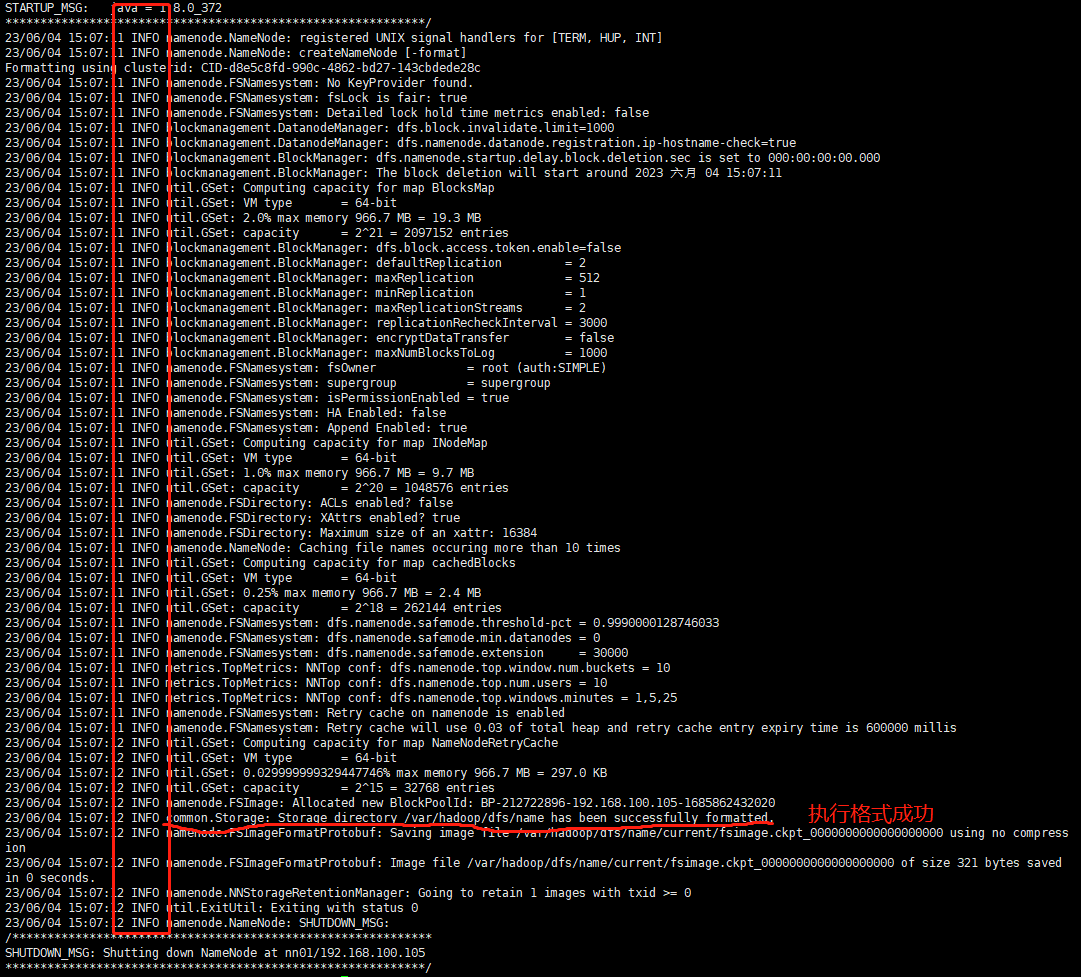
#格式化操作(./bin/hdfs namenode -format)执行成功如何下图
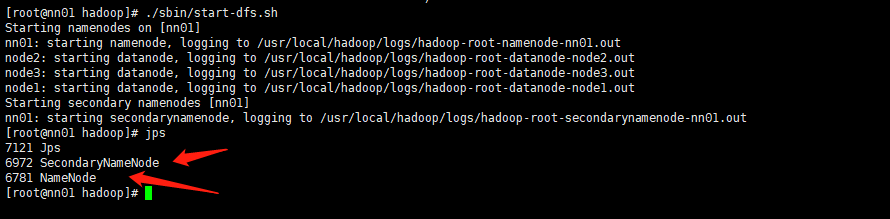
启动集群./sbin/start-dfs.sh 成功如下图
datenode如图没有datenode进程启动失败

执行删除日志文件,在namenode上重新格式化,. 重新启动
#[root@nn01 ~]# rm -rf /var/hadoop/* /usr/local/hadoop/logs/*
#[root@nn01 ~]# ./bin/hdfs namenode -format
#[root@nn01 ~]# ./sbin/start-dfs.sh
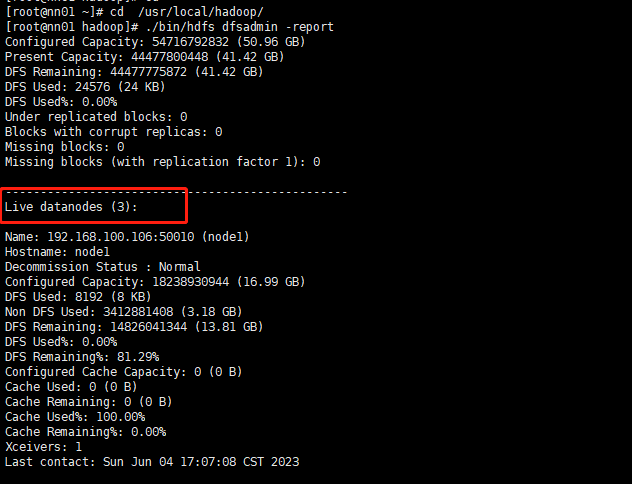
[root@nn01 ~]# ./bin/hdfs dfsadmin -report
如果出错了在log文件里面排查
[root@nn01 hadoop]# /usr/local/hadoop/logs/

mapred部署
分分布式计算框架mapred-site.xml
— 改名
FROM:mapred-site.xml.template
TO: mapred-site.xml
-— 资源管理类
mapreduce.framework,name
[root@nn01 hadoop]# vim mapred-site.xml
<configuration>
<!-- 指定MapReduce运行在yarn上-->
<!-- The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn. -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn部署
资源管理yarn-site.xml
- resourcemanager 地址
yarn.resoourcemanager.hostname
- nodemanager 使用哪个计算框架(让开发提供,目前我们使用mapreduce_shuffle框架)
yarn.nodemanager.aux-services
- mapreduce_shuffle 计算框架的名称
maperduce_shuffle
[root@nn01 hadoop]# vim yarn-site.xml
<configuration>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>nn01</value>
</property>
<!-- Site specific YARN configuration properties -->
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动yarn服务jps验证
[root@nn01 hadoop]# ./sbin/start-yarn.sh
[root@nn01 hadoop]# jps
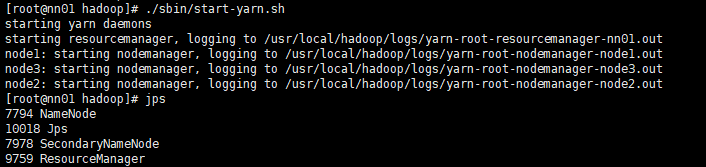
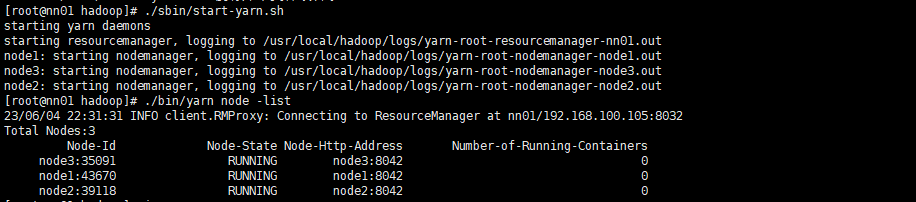
查看集群节点
[root@nn01 hadoop]# ./sbin/start-yarn.sh
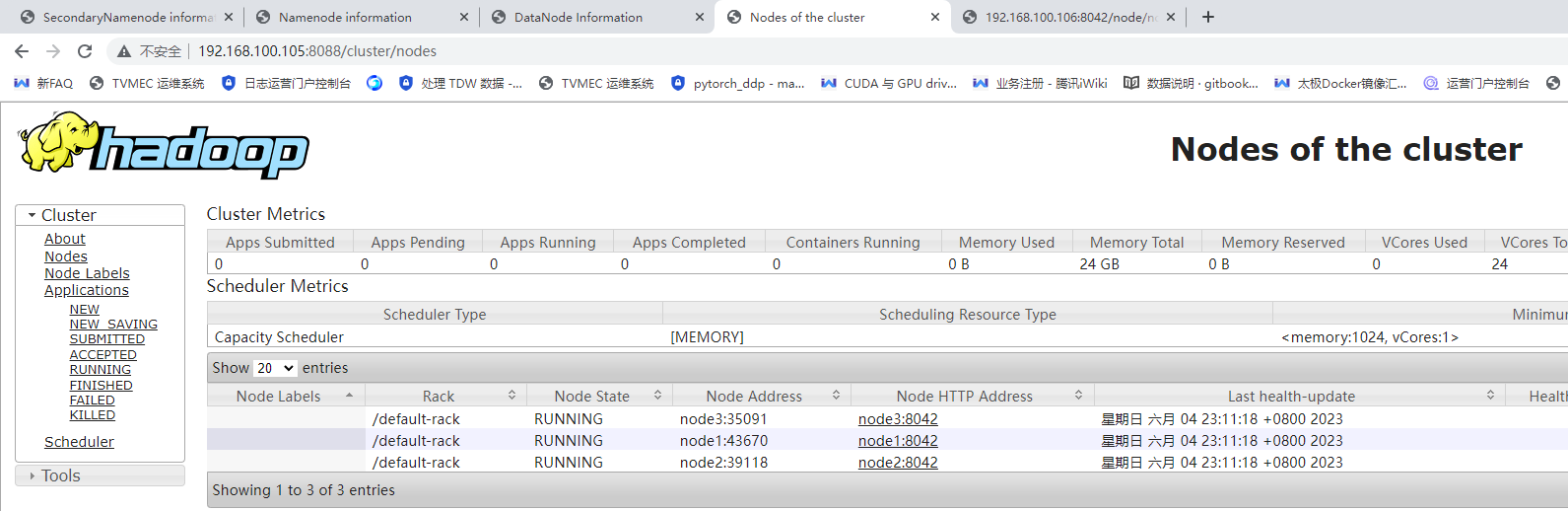
使用Web访问hadoop
- namenode web页面(nn01)
#http://192.168.100.105:50070/
- secondory namenode web页面(nn01)
#http://192.168.100.105:50090/
- resourcemanager web页面(nn01)
#http://192.168.100.105:8088
- datanode web 页面(node1,node2,node3)
#http://192.168.100.106:50075/
- nodemanager web页面(node1,node2,node3)
#http://192.168.100.106:8042/
HDFS使用
HDFS基础命令
#./bin/hadoop fs -ls /
- 对应shell命令
# ls /
#./bin/haddop fs -mkdir /abc
- 对应shell命令
# mkdir /abc
#./bin/hadoop fs -touchz /urfile
- 对应shell命令
- 上传文件
#./bin/hadoop fs -put *.txt /oo
- 下载文件
#./bin/hadoop fs -get /oo
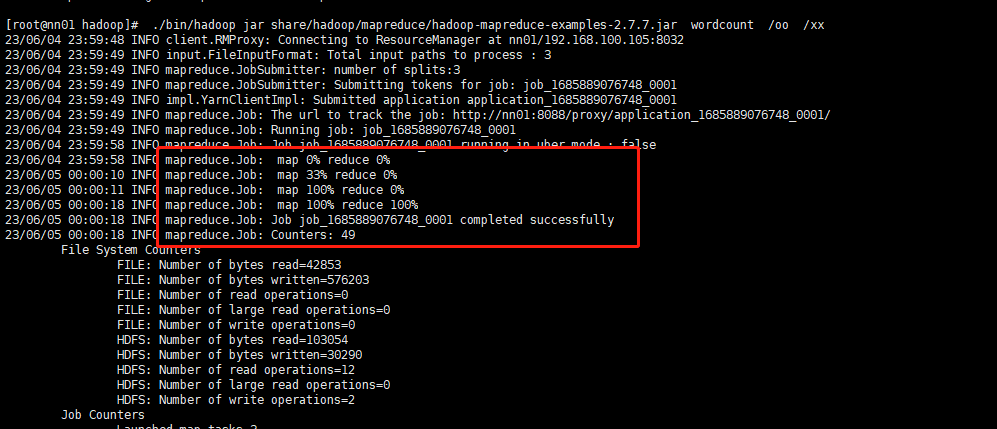
进行数据分析上传hdfs文件分析
[root@nn01 hadoop]# ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /oo /xx
详情(./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount hdfs://192.168.100.105::9000./oo hdfs://192.168.100.105::9000/xx)
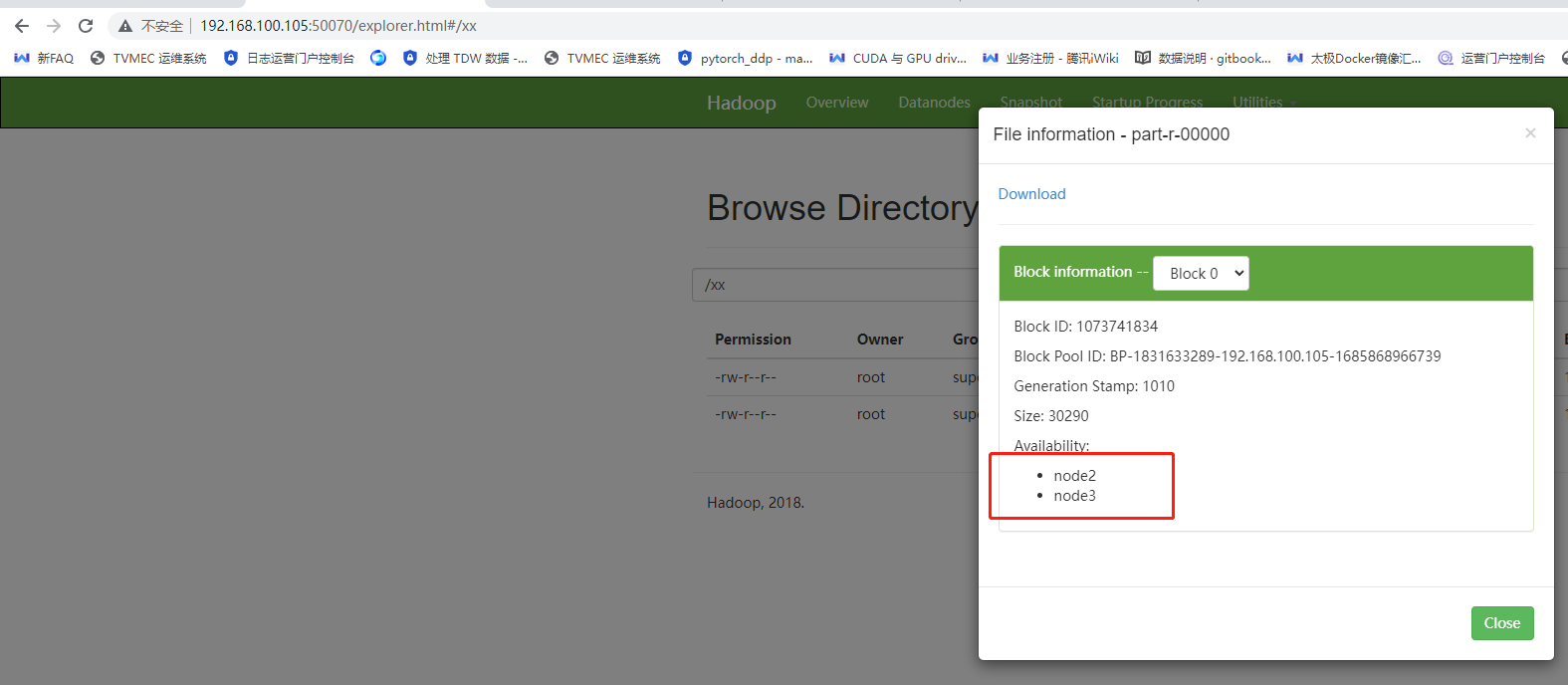
页面查看namenode存储两份hdfs文件在datenode上
http://192.168.100.105:50070/explorer.html#/xx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号